Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
def plot_decision_regions(X, y, classifier, test_idx=None,
resolution=0.02):
# define generador de marcador y mapa de colores
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# representa la superficie de decisión
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=colors[idx],
marker=markers[idx], label=cl,
edgecolor='black')
# destaca las muestras de prueba
if test_idx:
# representa todas las muestras
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0], X_test[:, 1],
c='', edgecolor='black', alpha=1.0,
linewidth=1, marker='o',
s=100, label='test set')
Con esta pequeña modificación en la función plot_decision_regions, ya podemos especificar los índices de las muestras que queremos marcar en los diagramas resultantes. El código es el siguiente:
>>> X_combined_std = np.vstack((X_train_std, X_test_std))
>>> y_combined = np.hstack((y_train, y_test))
>>> plot_decision_regions(X=X_combined_std,
... y=y_combined,
... classifier=ppn,
... test_idx=range(105, 150))
>>> plt.xlabel('petal length [standardized]')
>>> plt.ylabel('petal width [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.show()
Como podemos ver en el diagrama resultante, las tres clases de flor no pueden ser separadas perfectamente por un límite de decisión lineal:
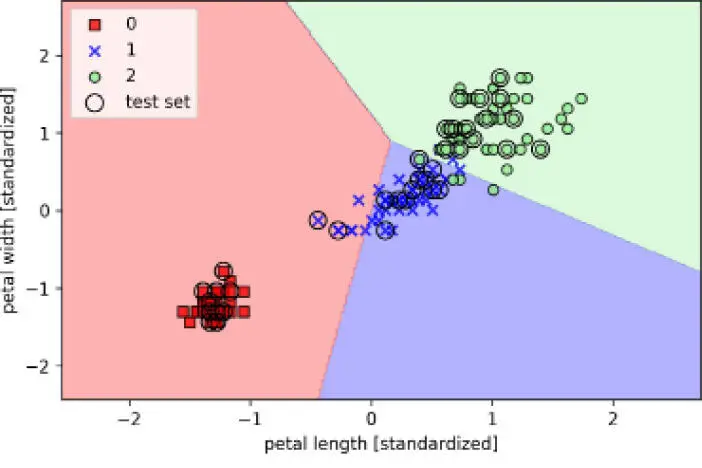
Recuerda que en el Capítulo 2, Entrenar algoritmos simples de aprendizaje automático para clasificación dijimos que el algoritmo de perceptrón no converge nunca en conjuntos de datos que no son perfectamente separables linealmente, razón por la cual el uso del algoritmo de perceptrón no suele ser recomendable para esta práctica. En las siguientes secciones, trataremos unos clasificadores lineales más potentes que convergen en un mínimo coste, incluso si las clases no son perfectamente separables linealmente.
 |
 |
El Perceptron, así como otras funciones y clases de scikit-learn, con frecuencia tiene parámetros adicionales que nosotros omitimos para mayor claridad. Puedes leer más acerca de estos parámetros en la función help de Python (por ejemplo, help(Perceptron)) o accediendo a la excelente documentación online de scikit-learn en http://scikit-learn.org/stable/. |  |
Modelar probabilidades de clase mediante regresión logística
Aunque la regla de perceptrón ofrece una sencilla y agradable introducción a los algoritmos de aprendizaje automático para clasificación, su mayor inconveniente es que nunca converge si las clases no son perfectamente separables linealmente. La tarea de clasificación de la sección anterior sería un ejemplo de este caso. De forma intuitiva, podemos pensar que la razón por la que los pesos se actualizan continuamente es que siempre existe como mínimo una muestra clasificada erróneamente en cada época. Evidentemente, puedes cambiar el rango de aprendizaje y aumentar el número de épocas, pero ten en cuenta que el perceptrón no convergerá nunca en este conjunto de datos. Para aprovechar mejor el tiempo, veamos otro sencillo –a la vez que potente– algoritmo para problemas de clasificación binaria y lineal: la regresión logística. Ten en cuenta que, a pesar de su nombre, la regresión logística es un modelo para clasificación, no para regresión.
Intuición en regresión logística y probabilidades condicionales
La regresión logística es un modelo de clasificación muy sencillo de implementar y que funciona muy bien en clases separables lineales. Es uno de los algoritmos más utilizados para clasificación en la industria. Parecido al perceptrón y a Adaline, el modelo de regresión logística es también, en este caso, un modelo lineal para clasificación binaria que puede ampliarse a la clasificación multiclase, por ejemplo, mediante la técnica OvR.
Para explicar la idea que se esconde detrás de la regresión logística como modelo probabilístico, vamos a presentar primero la razón de probabilidades: las probabilidades de que ocurra un evento concreto. La razón de probabilidades se puede escribir como 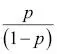 , donde
, donde 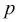 significa la probabilidad del evento positivo. El término evento positivo no significa necesariamente bueno, sino que se refiere al evento que queremos predecir, por ejemplo, la probabilidad de que un paciente tenga una determinada enfermedad. Podemos pensar en el evento positivo como una etiqueta de clase
significa la probabilidad del evento positivo. El término evento positivo no significa necesariamente bueno, sino que se refiere al evento que queremos predecir, por ejemplo, la probabilidad de que un paciente tenga una determinada enfermedad. Podemos pensar en el evento positivo como una etiqueta de clase 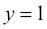 . Seguidamente, también podemos definir la función logit, que es simplemente el logaritmo de la razón de probabilidades:
. Seguidamente, también podemos definir la función logit, que es simplemente el logaritmo de la razón de probabilidades:
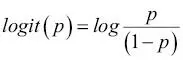
Ten en cuenta que log se refiere al logaritmo natural, puesto que es la convención común en informática. La función logit toma como entrada valores del rango de 0 a 1 y los transforma en valores de todo el rango de números reales, que podemos utilizar para expresar una relación lineal entre valores de características y logaritmos de la razón de probabilidades:
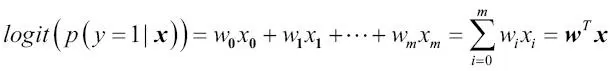
En este caso, 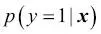 es la probabilidad condicional de que una muestra en concreto pertenezca a la clase 1 dadas sus características x.
es la probabilidad condicional de que una muestra en concreto pertenezca a la clase 1 dadas sus características x.
Ahora, nos interesa realmente predecir la probabilidad de que una determinada muestra pertenezca a una clase concreta, que es la forma inversa de la función logit. También se denomina función sigmoide logística, en ocasiones abreviada simplemente como función sigmoide, debido a su característica forma de S:
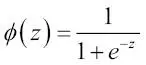
Aquí z es la entrada de red, la combinación lineal de pesos y las características de la muestra, 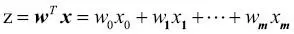 .
.
Интервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.