Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
>>> print('Labels counts in y:', np.bincount(y))
Labels counts in y: [50 50 50]
>>> print('Labels counts in y_train:', np.bincount(y_train))
Labels counts in y_train: [35 35 35]
>>> print('Labels counts in y_test:', np.bincount(y_test))
Labels counts in y_test: [15 15 15]
Muchos algoritmos de optimización y aprendizaje automático también requieren escalado de características para un rendimiento óptimo, como recordamos del ejemplo de descenso de gradiente en el Capítulo 2, Entrenar algoritmos simples de aprendizaje automático para clasificación. En este caso, vamos a normalizar las características utilizando la clase StandardScaler del módulo preprocessing de scikit-learn:
>>> from sklearn.preprocessing import StandardScaler
>>> sc = StandardScaler()
>>> sc.fit(X_train)
>>> X_train_std = sc.transform(X_train)
>>> X_test_std = sc.transform(X_test)
Con el código anterior, hemos cargado la clase StandardScaler del módulo preprocessing y hemos inicializado un nuevo objeto StandardScaler, que hemos asignado a la variable sc. Con el método fit, StandardScaler ha estimado los parámetros μ (muestra media) y σ (desviación estándar) para cada dimensión de características de los datos de entrenamiento. Llamando al método transform, hemos normalizado los datos de entrenamiento mediante estos parámetros estimados de 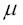 y
y 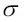 . Observa que hemos utilizado los mismos parámetros de escalado para normalizar el conjunto de prueba, por lo que ambos valores en el conjunto de datos de prueba y de entrenamiento son comparables unos con otros.
. Observa que hemos utilizado los mismos parámetros de escalado para normalizar el conjunto de prueba, por lo que ambos valores en el conjunto de datos de prueba y de entrenamiento son comparables unos con otros.
Una vez normalizados los datos de entrenamiento, ya podemos entrenar un modelo de perceptrón. La mayoría de los algoritmos en scikit-learn soportan la clasificación multiclase por defecto mediante el método One-versus-Rest (OvR), que nos permite alimentar al perceptrón con las tres clases de flor a la vez. El código es el siguiente:
>>> from sklearn.linear_model import Perceptron
>>> ppn = Perceptron(n_iter=40, eta0=0.1, random_state=1)
>>> ppn.fit(X_train_std, y_train)
La interfaz de scikit-learn nos recuerda a la implementación de nuestro perceptrón en el Capítulo 2, Entrenar algoritmos simples de aprendizaje automático para clasificación: después de cargar la clase Perceptron desde el módulo linear_model, iniciamos un nuevo objeto Perceptron y entrenamos el modelos mediante el método fit. En este caso, el parámetro de modelo eta0 es equivalente al rango de aprendizaje eta que utilizamos en la implementación de nuestro perceptrón, y el parámetro n_iter define el número de épocas (pasos en el conjunto de entrenamiento).
Como recordarás del Capítulo 2, Entrenar algoritmos simples de aprendizaje automático para clasificación, encontrar un rango de aprendizaje apropiado requiere algo de experimentación. Si el rango de aprendizaje es demasiado amplio, el algoritmo superará el mínimo coste global. Si el rango de aprendizaje es demasiado pequeño, el algoritmo requerirá más épocas hasta la convergencia, hecho que puede provocar que el aprendizaje sea lento, especialmente en conjuntos de datos grandes. Además, también utilizamos el parámetro random_state para garantizar la reproducibilidad de la mezcla inicial del conjunto de datos de entrenamiento después de cada época.
Una vez entrenado un modelo en scikit-learn, ya podemos realizar predicciones mediante el método predict, exactamente como en la implementación de nuestro perceptrón en el Capítulo 2, Entrenar algoritmos simples de aprendizaje automático para clasificación. El código es el siguiente:
>>> y_pred = ppn.predict(X_test_std)
>>> print('Misclassified samples: %d' % (y_test != y_pred).sum())
Misclassified samples: 3
Al ejecutar el código, vemos que el perceptrón clasifica erróneamente tres de las 45 muestras de flor. Por tanto, el error de clasificación en el conjunto de datos de prueba es aproximadamente el 0.067 o 6.7 % 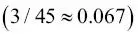 .
.
 |
 |
En lugar del error de clasificación, muchos de los que trabajan con el aprendizaje automático informan de la precisión de la clasificación de un modelo, que se calcula simplemente de la siguiente forma:1-error = 0.933 o 93.3 %. |  |
La librería también implementa una amplia variedad de mediciones de rendimiento distintas disponibles a través del módulo de medición. Por ejemplo, podemos calcular la precisión de clasificación del perceptrón en la prueba del modo siguiente:
>>> from sklearn.metrics import accuracy_score
>>> print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
Accuracy: 0.93
En este caso, y_test con las etiquetas de clase verdaderas e y_pred son las etiquetas de clase que habíamos predicho anteriormente. De forma alternativa, cada clasificador en scikit-learn tiene un método score, que calcula la precisión de la predicción de un clasificador combinando la llamada predict con accuracy_score, como se muestra a continuación:
>>> print('Accuracy: %.2f' % ppn.score(X_test_std, y_test))
Accuracy: 0.93
 |
 |
Observa que en este capítulo evaluamos el rendimiento de nuestros modelos en base al conjunto de prueba. En el Capítulo 5, Comprimir datos mediante la reducción de dimensionalidad, aprenderás unas útiles técnicas –incluyendo análisis gráficos como las curvas de aprendizaje– para detectar y prevenir el overfitting o sobreajuste. El sobreajuste significa que el modelo captura los patrones en los datos de entrenamiento, pero falla en la generalización de los datos no vistos. |  |
Por último, podemos utilizar nuestra función plot_decision_regions del Capítulo 2, Entrenar algoritmos simples de aprendizaje automático para clasificación para mostrar gráficamente las regiones de decisión de nuestro modelo de perceptrón recién entrenado y visualizar cómo separa correctamente las diferentes muestras de flor. Sin embargo, vamos a añadir una pequeña modificación para destacar las muestras del conjunto de datos de prueba mediante unos pequeños círculos:
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.