Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
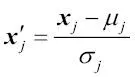
En este caso, 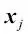 es un vector que consta de los valores de la característica j de todas las muestras de entrenamiento n, y esta técnica de normalización se aplica a cada característica j de nuestro conjunto de datos.
es un vector que consta de los valores de la característica j de todas las muestras de entrenamiento n, y esta técnica de normalización se aplica a cada característica j de nuestro conjunto de datos.
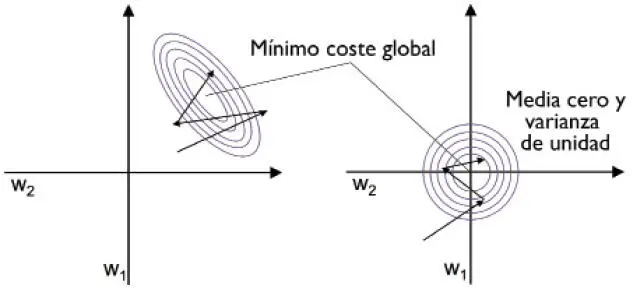
Una de las razones por las que la normalización ayuda al aprendizaje del descenso de gradiente es que el optimizador tiene que realizar menos pasos para encontrar una buena u óptima solución (el mínimo coste global), como se muestra en la siguiente figura, donde las dos imágenes representan la superficie de coste como una función de dos pesos modelo en un problema de clasificación bidimensional:
La normalización se puede conseguir fácilmente mediante el método integrado de NumPy mean y std:
>>> X_std = np.copy(X)
>>> X_std[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()
>>> X_std[:,1] = (X[:,1] - X[:,1].mean()) / X[:,1].std()
Tras la normalización, volveremos a entrenar Adaline y veremos que ahora converge después de un pequeño número de épocas con un rango de aprendizaje 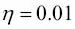 :
:
>>> ada = AdalineGD(n_iter=15, eta=0.01)
>>> ada.fit(X_std, y)
>>> plot_decision_regions(X_std, y, classifier=ada)
>>> plt.title('Adaline - Gradient Descent')
>>> plt.xlabel('sepal length [standardized]')
>>> plt.ylabel('petal length [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.tight_layout()
>>> plt.show()
>>> plt.plot(range(1, len(ada.cost_) + 1), ada.cost_, marker='o')
>>> plt.xlabel('Epochs')
>>> plt.ylabel('Sum-squared-error')
>>> plt.show()
Una vez ejecutado el código, deberíamos ver una imagen de las regiones de decisión, así como un diagrama del coste decreciente, como se muestra en la siguiente figura:
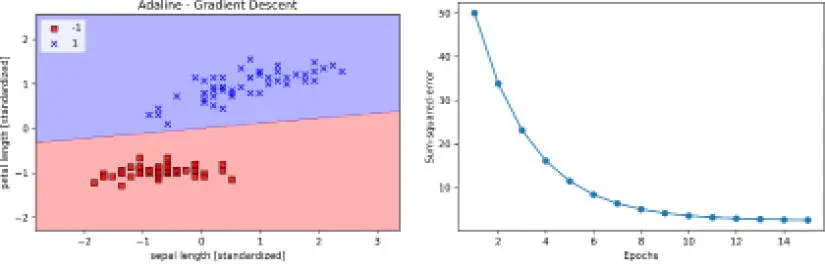
Como podemos ver en los diagramas, Adaline ahora ha convergido después de entrenar las características normalizadas mediante un rango de aprendizaje 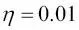 . Sin embargo, se observa que el SSE no es cero, incluso si todas las muestras están correctamente clasificadas.
. Sin embargo, se observa que el SSE no es cero, incluso si todas las muestras están correctamente clasificadas.
Aprendizaje automático a gran escala y descenso de gradiente estocástico
En la sección anterior, hemos aprendido a minimizar la función de coste dando un paso en la dirección opuesta a un gradiente de coste calculado a partir de un conjunto de entrenamiento completo. Esta es la razón por la que a veces este enfoque también se conoce como descenso de gradiente en lotes. Ahora imaginemos que tenemos un conjunto de datos muy amplio con millones de puntos de datos, cosa bastante frecuente en aplicaciones de aprendizaje automático. En casos como este, ejecutar un descenso de gradiente en lotes puede ser computacionalmente muy costoso, puesto que necesitamos reevaluar todo el conjunto de datos de entrenamiento cada vez que realizamos un paso hacia el mínimo global.
Una conocida alternativa al algoritmo del descenso de gradiente en lotes es el descenso de gradiente estocástico, llamado también a veces «descenso de gradiente online o iterativo». En lugar de actualizar los pesos en base a la suma de los errores acumulados en todas las muestras 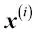 :
:
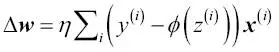
Actualizamos los pesos de forma incremental para cada muestra de entrenamiento:
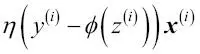
Aunque el descenso de gradiente estocástico se puede considerar como una aproximación al descenso de gradiente, normalmente consigue la convergencia mucho más rápido debido a unas actualizaciones del peso más frecuentes. Como cada gradiente se calcula en base a un único ejemplo de entrenamiento, la superficie de error es más ruidosa que en el descenso de gradiente. El descenso de gradiente estocástico también puede tener la ventaja de que puede escapar de los mínimos locales poco profundos más fácilmente si trabajamos con funciones de coste no lineales, como veremos más adelante en el Capítulo 12, Implementar una red neuronal artificial multicapa desde cero. Para que los resultados sean satisfactorios con el descenso de gradiente estocástico, es importante presentar los datos de entrenamiento en un orden aleatorio; además, nos interesa mezclar los conjuntos de entrenamiento para cada época con el fin de evitar ciclos.
 |
 |
En las implementaciones de descenso de gradiente estocástico, el rango de aprendizaje fijado 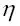 a menudo se sustituye por un rango de aprendizaje adaptativo que disminuya con el tiempo; por ejemplo: a menudo se sustituye por un rango de aprendizaje adaptativo que disminuya con el tiempo; por ejemplo: 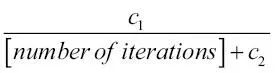 donde donde 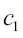 y y 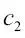 son constantes. Debemos observar que el descenso de gradiente estocástico no alcanza el mínimo global, sino un área muy cercana a él. Y mediante un rango de aprendizaje adaptativo, podemos conseguir un mayor recorrido hacia el coste mínimo. son constantes. Debemos observar que el descenso de gradiente estocástico no alcanza el mínimo global, sino un área muy cercana a él. Y mediante un rango de aprendizaje adaptativo, podemos conseguir un mayor recorrido hacia el coste mínimo. |
 |
Otra ventaja del descenso de gradiente estocástico es que podemos utilizarlo para aprendizaje online. En el aprendizaje online, nuestro modelo se entrena sobre la marcha al mismo tiempo que van llegando nuevos datos de entrenamiento. Esto resulta especialmente útil si estamos acumulando grandes cantidades de datos, por ejemplo, datos de clientes en aplicaciones web. Con el aprendizaje online, el sistema se puede adaptar de inmediato a los cambios y los datos de entrenamiento pueden ser descartados después de actualizar el modelo si existen problemas con el espacio de almacenamiento.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.