Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# representar muestras de clase
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0],
y=X[y == cl, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=cl,
edgecolor='black')
En primer lugar, definimos un número de colors y markers y creamos un mapa de colores a partir de la lista de colores a través de ListedColormap. A continuación, determinamos los valores mínimos y máximos para las dos características y utilizamos los vectores de características para crear un par de matrices de cuadrícula xx1 y xx2 mediante la función meshgrid de NumPy. Como hemos entrenado nuestro clasificador de perceptrón en dos dimensiones de características, necesitamos acoplar las matrices y crear una matriz que tenga el mismo número de columnas que el subconjunto de entrenamiento Iris. Para ello, podemos utilizar el método predict para predecir las etiquetas de clase Z de los correspondientes puntos de la cuadrícula. Después de remodelar las etiquetas de clase Z predichas en una cuadrícula con las mismas dimensiones que xx1 y xx2, ya podemos dibujar un diagrama de contorno con la función contourf de Matplotlib, que mapea las diferentes regiones de decisión en distintos colores para cada clase predicha en la matriz de cuadrícula:
>>> plot_decision_regions(X, y, classifier=ppn)
>>> plt.xlabel('sepal length [cm]')
>>> plt.ylabel('petal length [cm]')
>>> plt.legend(loc='upper left')
>>> plt.show()
Después de ejecutar el ejemplo de código anterior, deberíamos ver un diagrama de las regiones de decisión, como se muestra en la siguiente figura:
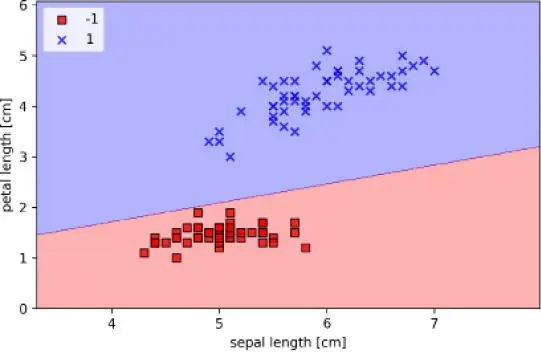
Como podemos ver en el diagrama, el perceptrón ha aprendido un límite de decisión capaz de clasificar perfectamente todas las muestras de flor en el subconjunto de entrenamiento Iris.
 |
 |
Aunque el perceptrón ha clasificado a la perfección las dos clases de flor Iris, la convergencia es uno de los mayores problemas del perceptrón. Frank Rosenblatt probó matemáticamente que la regla de aprendizaje del perceptrón converge si las dos clases pueden ser separadas por un hiperplano lineal. Sin embargo, si las clases no pueden ser separadas perfectamente por un límite de decisión lineal, los pesos no dejarán nunca de actualizarse a menos que indiquemos un número máximo de épocas. |  |
Neuronas lineales adaptativas y la convergencia del aprendizaje
En esta sección, echaremos un vistazo a otro tipo de red neuronal de capa única: las neuronas lineales adaptativas, en inglés ADAptive LInear NEuron (Adaline). Adaline fue publicada por Bernard Widrow y su alumno Ted Hoff, pocos años después del algoritmo de perceptrón de Frank Rosenblatt, y puede considerarse como una mejora de este último. (Puedes consultar An Adaptive "Adaline" Neuron Using Chemical "Memistors", Technical Report Number 1553-2, B. Widrow and others, Stanford Electron Labs, Stanford, CA, October 1960).
El algoritmo Adaline es especialmente interesante porque ilustra los conceptos clave para definir y minimizar las funciones de coste continuas. Esto sienta las bases para la comprensión de algoritmos de aprendizaje automático más avanzados para la clasificación, como la regresión logística, máquinas de vectores de soporte y modelos de regresión, que trataremos en capítulos posteriores.
La diferencia clave entre la regla Adaline (también conocida como regla Widrow-Hoff) y el perceptrón de Rosenblatt es que los pesos se actualizan en base a una función de activación lineal en vez de en base a una función escalón unitario como sucede en el perceptrón. En Adaline, esta función de activación lineal 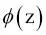 es simplemente la función de identificación de la entrada de red, por lo que:
es simplemente la función de identificación de la entrada de red, por lo que:
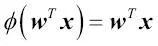
Mientras que la función de activación lineal se utiliza para aprender los pesos, seguimos utilizando una función de umbral que realiza la predicción final, que es parecida a la función escalón unitario que hemos visto anteriormente. Las diferencias principales entre el perceptrón y el algoritmo Adaline se encuentran destacadas en la siguiente imagen:
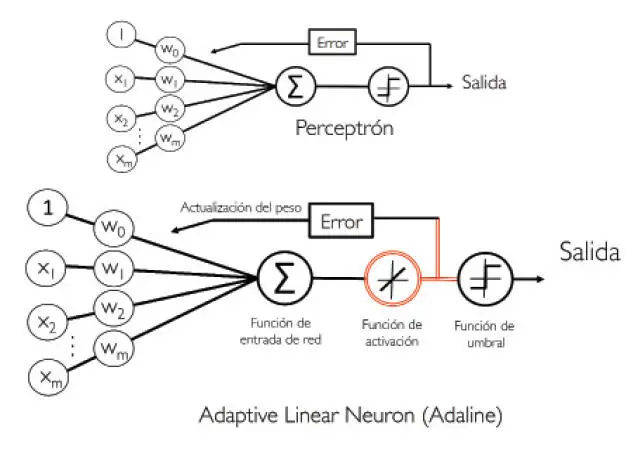
Esta ilustración muestra que el algoritmo Adaline compara las etiquetas de clase verdaderas con la salida de valores continuos de la función de activación lineal para calcular el error del modelo y actualizar los pesos. Por el contrario, el perceptrón compara las etiquetas de clase verdaderas con las etiquetas de clase predichas.
Minimizar funciones de coste con el descenso de gradiente
Uno de los ingredientes clave de los algoritmos de aprendizaje automático supervisado es una función objetivo definida que debe ser optimizada durante el proceso de aprendizaje. Esta función objetivo suele ser una función de coste que queremos minimizar. En el caso de Adaline, podemos definir la función de coste 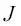 para aprender los pesos como la Suma de Errores Cuadráticos (SSE, del inglés Sum of Squared Errors) entre la salida calculada y la etiqueta de clase verdadera:
para aprender los pesos como la Suma de Errores Cuadráticos (SSE, del inglés Sum of Squared Errors) entre la salida calculada y la etiqueta de clase verdadera:
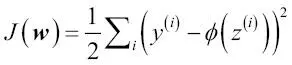
Hemos añadido el término 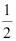 simplemente para facilidad nuestra, porque nos permitirá derivar el gradiente de un modo más fácil, como veremos en los siguientes párrafos. La principal ventaja de esta función de activación lineal continua, en comparación con la función escalón unitario, es que la función de coste pasa a ser diferenciable. Otra propiedad a tener en cuenta de esta función de coste es que es convexa; esto significa que podemos utilizar un simple pero potente algoritmo de optimización, denominado descenso de gradiente, para encontrar los pesos que minimicen nuestra función de coste y clasificar así las muestras del conjunto de datos Iris.
simplemente para facilidad nuestra, porque nos permitirá derivar el gradiente de un modo más fácil, como veremos en los siguientes párrafos. La principal ventaja de esta función de activación lineal continua, en comparación con la función escalón unitario, es que la función de coste pasa a ser diferenciable. Otra propiedad a tener en cuenta de esta función de coste es que es convexa; esto significa que podemos utilizar un simple pero potente algoritmo de optimización, denominado descenso de gradiente, para encontrar los pesos que minimicen nuestra función de coste y clasificar así las muestras del conjunto de datos Iris.
Интервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.