Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Observa que el método activation no tiene ningún efecto sobre el código, puesto que es simplemente una función de identidad. En este caso, hemos añadido la función de activación (calculada mediante el método activation) para mostrar cómo fluye la información a través de una red neuronal de una sola capa: características a partir de los datos de entrada, entrada de red, activación y salida. En el siguiente capítulo, conoceremos un clasificador de regresión logística que utiliza una función de activación no lineal sin identidad. Veremos que un modelo de regresión logística está estrechamente relacionado con Adaline, siendo la única diferencia su activación y función de coste.
Ahora, de forma parecida a la implementación del perceptrón anterior, recogemos los valores de coste en una lista self.cost_ para comprobar si el algoritmo converge después del entrenamiento.
 |
 |
Llevar a cabo una multiplicación matriz por vector es similar a calcular un producto escalar, donde cada fila de la matriz es tratada como un único vector de fila. Este enfoque vectorizado representa una notación más compacta y da como resultado un cálculo más eficiente con NumPy. Por ejemplo: 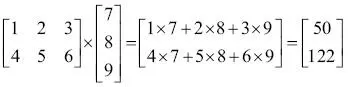 |
 |
A la práctica, esto suele requerir algo de experimentación para encontrar un buen rango de aprendizaje 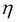 para una óptima convergencia. Así que vamos a elegir dos rangos de aprendizaje distintos,
para una óptima convergencia. Así que vamos a elegir dos rangos de aprendizaje distintos, 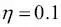 y
y 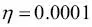 , para empezar y mostrar en un diagrama las funciones de coste frente al número de épocas, y ver cómo aprende la implementación de Adaline de los datos de entrenamiento.
, para empezar y mostrar en un diagrama las funciones de coste frente al número de épocas, y ver cómo aprende la implementación de Adaline de los datos de entrenamiento.
 |
|
El rango de aprendizaje (eta), así como el número de épocas (n_iter), también se conocen como hiperparámetros del perceptrón y algoritmos de aprendizaje Adaline. En el Capítulo 6, Aprender las mejores prácticas para la evaluación de modelos y el ajuste de hiperparámetros, veremos diferentes técnicas para encontrar automáticamente los valores de distintos hiperparámetros que producen un rendimiento óptimo del modelo de clasificación. |
 |
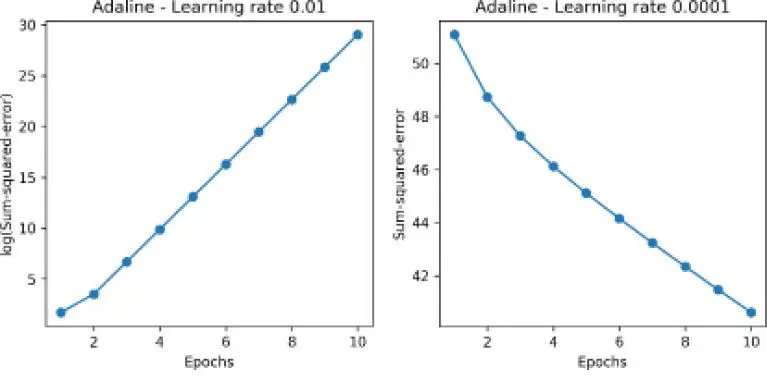
Ahora veamos en un diagrama el coste contra el número de épocas para los dos rangos de aprendizaje distintos:
>>> fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
>>> ada1 = AdalineGD(n_iter=10, eta=0.01).fit(X, y)
>>> ax[0].plot(range(1, len(ada1.cost_) + 1),
... np.log10(ada1.cost_), marker='o')
>>> ax[0].set_xlabel('Epochs')
>>> ax[0].set_ylabel('log(Sum-squared-error)')
>>> ax[0].set_title('Adaline - Learning rate 0.01')
>>> ada2 = AdalineGD(n_iter=10, eta=0.0001).fit(X, y)
>>> ax[1].plot(range(1, len(ada2.cost_) + 1),
... ada2.cost_, marker='o')
>>> ax[1].set_xlabel('Epochs')
>>> ax[1].set_ylabel('Sum-squared-error')
>>> ax[1].set_title('Adaline - Learning rate 0.0001')
>>> plt.show()
Como podemos ver en los diagramas de función coste obtenidos, nos encontraríamos con dos tipos de problemas. El gráfico de la izquierda muestra qué pasaría si eligiéramos un rango de aprendizaje demasiado amplio. En lugar de minimizar la función de coste, el error es mayor en cada época, porque sobrepasamos el mínimo global. Por otro lado, podemos ver que el coste disminuye en el diagrama de la derecha, pero el rango de aprendizaje elegido es tan pequeño que el algoritmo requeriría un número de épocas muy elevado para converger con el mínimo coste global:
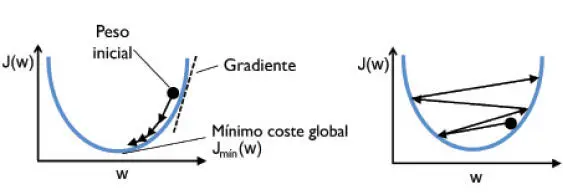
La siguiente imagen ilustra qué pasaría si cambiáramos el valor de un parámetro de peso concreto para minimizar la función de coste 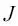 . La imagen de la izquierda muestra el caso de una buena elección del rango de aprendizaje, donde el coste disminuye gradualmente, moviéndose en la dirección del mínimo global. Sin embargo, la imagen de la derecha muestra qué pasa si elegimos un rango de aprendizaje demasiado amplio (que sobrepasamos el mínimo global):
. La imagen de la izquierda muestra el caso de una buena elección del rango de aprendizaje, donde el coste disminuye gradualmente, moviéndose en la dirección del mínimo global. Sin embargo, la imagen de la derecha muestra qué pasa si elegimos un rango de aprendizaje demasiado amplio (que sobrepasamos el mínimo global):
Mejorar el descenso de gradiente mediante el escalado de características
Muchos de los algoritmos de aprendizaje automático con los que nos encontraremos en este libro requieren algún tipo de escalado de características para un rendimiento óptimo, como veremos con mayor detalle en el Capítulo 3, Un recorrido por los clasificadores de aprendizaje automático con scikit-learn y en el Capítulo 4, Generar buenos modelos de entrenamiento - Preprocesamiento de datos.
El descenso de gradiente es uno de los muchos algoritmos que se benefician del escalado de características. En esta sección, utilizaremos un método de escalado de características denominado normalización, que proporciona a nuestros datos la propiedad de una distribución normal estándar, la cual ayuda al descenso de gradiente a converger más rápidamente. La normalización cambia la media de cada característica para que se centre en cero y para que cada característica tenga una desviación estándar de 1. Por ejemplo, para normalizar la característica j, podemos simplemente sustraer la media de muestra 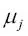 de cada muestra de entrenamiento y dividirla por su desviación estándar
de cada muestra de entrenamiento y dividirla por su desviación estándar 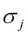 :
:
Интервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.