Innovando la educación en la tecnología
Здесь есть возможность читать онлайн «Innovando la educación en la tecnología» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Innovando la educación en la tecnología
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Innovando la educación en la tecnología: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Innovando la educación en la tecnología»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Su temática principal giró alrededor del impacto de las tecnologías de la información en la educación. Las ponencias magistrales y los trabajos de investigación presentados ofrecieron innovadoras experiencias de aplicación y prometedoras líneas de trabajo futuro encaminadas a la transformación de las formas tradicionales de educación hacia esquemas dinámicos y soportados fuertemente por la tecnología.
La aplicación de paradigmas innovadores basados en técnicas de improvisación, gamificación, educación en ingeniería y enseñanza de la programación demostraron el potencial impacto que el binomio tecnología-educación puede generar en todos los niveles educativos y en diversos contextos de enseñanza-aprendizaje.
Innovando la educación en la tecnología — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Innovando la educación en la tecnología», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
a) Recolectar una base de datos de noticias escritas en español.
b) Clasificar estas noticias utilizando el servicio de Google AutoML, esto sirve para el entrenamiento.
c) Transformar las noticias en vectores para que sirvan de input para el modelo.
d) Formular e implementar el modelo de redes neuronales long short-term memory .
e) Realizar la validación del modelo.
f) Realizar el experimento para determinar el estado de ánimo de las personas luego de leer las noticias.
2. METODOLOGÍA
2.1 Recolección y preparación de noticias
Se utilizó una librería del lenguaje de programación Python llamada BeautifulSoup para poder realizar un web scrapping de diferentes páginas web de noticias del Perú ( RPP, El Comercio, La República y Exitosa )
Se escogió el título y el cuerpo de la noticia como input para el modelo, y se seleccionaron noticias entre el 12 de agosto del 2018 al 11 de septiembre del 2018 (Easton y McColl, 2007). Luego fueron almacenadas en un formato separado por comas (csv).
Para clasificar las noticas en negativas o positivas, primero fueron traducidas al inglés y luego se usó el servicio AutoML de Google para clasificarlas. Las noticias fueron traducidas al inglés debido a que AutoML de Google no puede determinar el sentimiento de textos en español.
En el siguiente paso, se empezó a realizar un proceso de muestreo aleatorio para balancear la proporción de noticias en 1:1, esto se realizó para que no exista un bias a la hora de entrenar el modelo. Al concluir este proceso se obtuvo una base de datos de noticias, de 20 000 noticias (10 000 noticias negativas y 10 000 noticias positivas) (Trochim, 2007).
Tabla 1
Distribución de las noticias
| Base de datos de noticias | ||
| Fuente | Positivas | Negativas |
| El Comercio | 2563 | 1709 |
| La República | 2896 | 2108 |
| RPP | 2563 | 3156 |
| Exitosa | 1978 | 3027 |
| 10 000 | 10 000 |
Elaboración propia
Luego, se realizó un proceso de encoding y tokenización (Famili, Shen, Weber y Simoudis, 1997). De esta forma se transformarán las noticias en vectores de números. También se creó automáticamente un diccionario de palabras en el cual se identifican las palabras con un valor numérico, generado después del encoding .
En la tarea de tokenización se realizó la eliminación de stop-words , la eliminación de caracteres especiales y signos de puntuación (Klevecka y Lelis, 2008).
2.2 Desarrollo del modelo
Para determinar la polaridad de las noticias se decidió usar una granularidad a nivel del documento, esto se debe a que una noticia posee un texto extenso, entonces es necesario poder obtener la polaridad de este en forma conjunta, pues a lo largo del escrito puede haber diferentes puntos de vista, tomar la granularidad a nivel de oración podría haber sido perjudicial para la tarea de clasificación.
El modelo de aprendizaje de máquinas seleccionado fue de redes neuronales recurrentes, en específico el tipo LSTM (Hochreiter y Schmidhuber, 1997), este tipo se escogió debido a la capacidad de poder “recordar” los elementos de un texto, esto es fundamental en el análisis de textos largos porque de esta manera se puede capturar su contexto completo.
Para normalizar los datos de entrada ( inputs ) del modelo se usó la técnica de mean pooling por dos motivos: 1) para controlar la cantidad de features que van a ser recibidas por la capa de regresión logística; 2) para extraer la información promedio de cada texto, tomando en cuenta toda la información del texto, esto quiere decir que todos los valores son usados para realizar un mapeado de features .
Para determinar la clasificación de las noticias, en la capa final de la red neuronal, se usó una regresión logística, debido a que la salida de la red LSTM normalizada por el average pooling brinda valores entre 0 y 1, lo cual demuestra una probabilidad de ser positivos o negativos, pero para ser aún más exactos, se decidió usar la regresión logística ya que sólo se cuenta con dos posibles clasificaciones, positivas o negativas.
Se decidió recolectar un dataset propio de noticias de medios de comunicación locales, debido a que no existe uno. Igualmente, se recurrió al uso de técnicas de limpiado de datos como la eliminación de signos de puntación y de stopwords , ya que ambos no agregan valor para la tarea a realizar. Luego se realizó un muestreo aleatorio en la base de datos para tenerla en una relación de 1:1 con respecto a noticias positivas y negativas, esto con el fin de que no exista un bias a la hora de entrenar el modelo.
El modelo propuesto es una variación de la red neuronal LSTM. En esta variación, la activación que ocurre en la puerta de salida de la capa LSTM no depende de su estado Ct , esto permite realizar parte de las operaciones necesarias en paralelo, volviendo el modelo mucho más eficiente computacionalmente, menos tiempo en entrenar el modelo sin algún impacto notable en la efectividad del modelo (Gers, Schmidhuber y Cummins, 2000).
Las ecuaciones siguientes describen como se actualiza la capa LSTM en cada unidad de tiempo t , según el modelo propuesto.
1) Es el input (datos de entrada) de la capa LSTM en un tiempo t .
2) W f, W c, W o, U i, U f, U c, U o y V o son matrices de weights (pesos del modelo).
3) b i, b f, b c y b o son vectores “bias”.
Primero, se calculan los valores para la puerta de entrada y el valor candidato para los estados de la capa LSTM en un tiempo t.
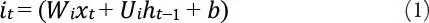
Donde i t es el valor de la puerta de entrada en un tiempo t y σ es la función de activación.
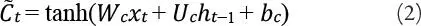
Donde 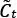 es el valor candidato para los estados de la red LSTM en un tiempo t .
es el valor candidato para los estados de la red LSTM en un tiempo t .
Luego se calcula el valor de la función de activación f t de las puertas de olvido en un tiempo t .
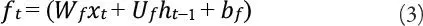
Luego de obtener el valor de la función de activación de la puerta de entrada, el valor de la función de activación de la puerta de salida y el valor candidato para los estados de la capa LSTM, se pasa a calcular el nuevo estado C t de la capa LSTM en un tiempo t .
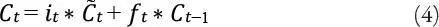
Donde es el valor candidato para los estados de la red LSTM en un tiempo t .
Интервал:
Закладка:
Похожие книги на «Innovando la educación en la tecnología»
Представляем Вашему вниманию похожие книги на «Innovando la educación en la tecnología» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Innovando la educación en la tecnología» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.