Bioinformatics and Medical Applications
Здесь есть возможность читать онлайн «Bioinformatics and Medical Applications» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Bioinformatics and Medical Applications
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Bioinformatics and Medical Applications: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Bioinformatics and Medical Applications»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
The main topics addressed in this book are big data analytics problems in bioinformatics research such as microarray data analysis, sequence analysis, genomics-based analytics, disease network analysis, techniques for big data analytics, and health information technology.
Audience Bioinformatics and Medical Applications: Big Data Using Deep Learning Algorithms
Bioinformatics and Medical Applications — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Bioinformatics and Medical Applications», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
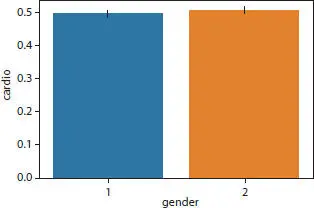
Figure 1.5 Gender distribution.
1.3.3 Decision Tree
Decision Trees are amazing and well-known devices which are used for classification and forecasting. It is a tree based classifier wherein nodes represent a test on one attribute, leaves indicate the worth of the target attribute, edge represents split of 1 attribute and path is a dis junction of test to form the ultimate decision.
The current implementation offers two stages of impurity (Gini impurity and entropy) and one impurity measure for regression (variability). Gini’s impurity refers to the probability of a misdiagnosis of a replacement variate, if that condition is new organized randomly in accordance with the distribution of class labels from the information set. Bound by 0 occurs when data contains only one category. Gini Index is defined by the formula
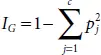
Entropy is defined as
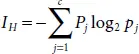
where p jis the proportion of samples that belong to class c for a specific node.
Gini impurity and entropy are used as selection criterion for decision trees. Basically, they assist us with figuring out what is a decent split point for root/decision nodes on classification/regression trees. Decision trees utilizes the split point to split on the feature resulting in the highest information gain (IG) for a given criteria which is referred to as Gini or entropy. It is based on the decrease in entropy after a dataset is split on an attribute. A number of the benefits of decision tree are as follows:
• It requires less effort to process data while it is done in advance.
• It does not require standardization and data scaling.
• Intuitive and simple to clarify.
However, it has some disadvantages too, as follows:
• Minor changes in the data can cause major structural changes leading to instability.
• Sometimes math can be very difficult in some algorithms.
• It usually involves more time for training.
• It is very expensive as the complexity and time taken is too much.
• Not adequate on regression and predicting continuous values.
1.3.4 Random Forest
The Random Forest, just as its name infers, increases the number of individual decision trees that work in conjunction. The main idea behind a random forest is the wisdom of the masses. An enormous number of moderately unrelated trees functioning as a council will surpass any existing models. Random Forest allows us to change the contributions by tuning the boundaries like basis, depth of tree, and maximum and minimum leaf. It is a supervised machine learning algorithm, used for both classification and regression. It makes use of bagging and feature randomness while assembling each singular tree to try to make an uncorrelated forest whose expectation is to be more precise than that of any individual tree. The numerical clarification of the model is as given:
1 1. Let D be a collection of dataset used for purpose of training D = (x1, y1) … (xn, yn).
2 2. Let w = w1(x); w2(x) … wk(x) be an ensemble of weak classifiers.
3 3. If every wk is a decision tree, then the parameters of the tree are described as
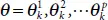
1 4. Output of each decision tree is a classifier wk(x) = w(x|θk).
2 5. Hence, Final Classification f(x) = Majority Voting of wk(X).
Figure 1.6gives a pictorial representation of the working of random forest.
Some of the advantages of Random Forest algorithm are as follows:
• Reduces overfitting problem.
• Solves both clasification and regression problems.
• Handles missing values automatically.
• Stable and robust to outliers.
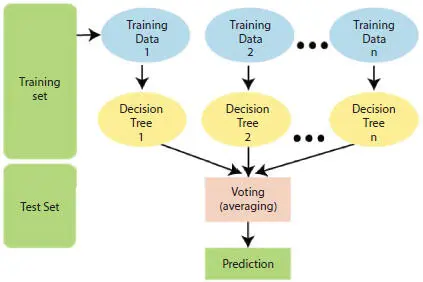
Figure 1.6 Random forest algorithm.
Some of the disadvantages are as follows:
• Complexity
• Longer training period.
1.3.5 Naive Bayes Algorithm
Naive Bayes is a fantastic AI calculation utilized for prediction which depends on Bayes Theorem. Bayes Theorem expresses that given a theory H and proof E, the relationship between possibility of pre-proof likelihood P(H) and the possibility of the following theoretical evidence P (H|E) is
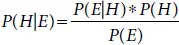
Assumption behind Naive Bayes classifiers is that the estimation of a unique element is not dependent on the estimation of some different element taking the class variable into consideration. For instance, a product may be regarded as an apple if possibly it is red in color, round in shape, and around 10 cm wide.
A Naive Bayes classifier looks at all these highlights to offer independently to the chances that this product is an apple, although there is a potential relationship between shading, roundness, and dimension highlights. They are probabilistic classifiers and, subsequently, will compute the likelihood of every classification utilizing Bayes’ hypothesis, and the classification with the most elevated likelihood will be the yield.
Let D be the training dataset, y be the variable for class and the attributes represented as X hence according to Bayes theorem
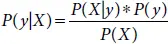
where
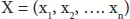
So, replacing the X and applying the chain rule, we get
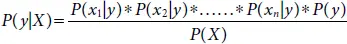
Since the denominator remains same, removing it from the dependency
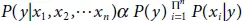
Therefore, to find the category y with high probability, we use the following function:
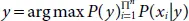
Some of the advantages of Naive Bayes algorithm are as follows:
• Easy to execute.
• Requires a limited amount of training data to measure parameters.
• High computational efficiency.
However, there are some disadvantages too, as follows:
• It is thought that all aspects are independent and equally important which is virtually impossible in real applications.
• The tendency to bias when increasing the number of training sets.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Bioinformatics and Medical Applications»
Представляем Вашему вниманию похожие книги на «Bioinformatics and Medical Applications» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Bioinformatics and Medical Applications» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.