Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Здесь есть возможность читать онлайн «Savo G. Glisic - Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
A practical overview of the implementation of artificial intelligence and quantum computing technology in large-scale communication networks Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks
Artificial Intelligence and Quantum Computing for Advanced Wireless Networks — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Table 3.3 Variables, for the derivation of gradient with ϕ ↔ φ .
| Alias | Size and Meaning | |
|---|---|---|
| X | x l | H l W l× D l, the input tensor |
| F | f, w l | HW D l× D , D kernels, each H × W and D lchannels |
| Y | y, x l+1 | H l + 1 W l + 1× D l + 1, the output, D l + 1= D |
| ϕ ( x l) | H l + 1 W l + 1× HW D l, the im2rowexpansion of x l |
|
| M | H l + 1 W l + 1 HW D l× H l W l D l, the indictor matrix for ϕ ( x l) | |
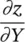 |
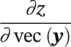 |
H l + 1 W l + 1× D l + 1, gradient for y |
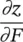 |
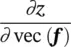 |
HW D l× D , gradient to update the convolution kernels |
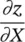 |
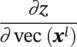 |
H l W l× D l, gradient for x l, useful for back propagation |
From the chain rule, it is easy to compute ∂z /∂vec( F ) as
(3.91) 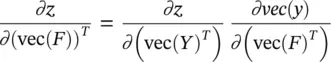
The first term on the right in Eq. (3.91)is already computed in the ( l + 1)‐th layer as ∂z / ∂ (vec( x l + 1)) T. Based on Eq. (3.89), we have
(3.92) 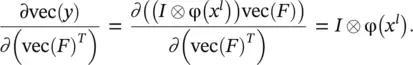
We have used the fact that ∂Xa T/ ∂a = X or ∂Xa / ∂a T= X so long as the matrix multiplications are well defined. This equation leads to
(3.93) 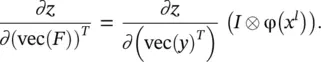
Taking the transpose, we get
(3.94) 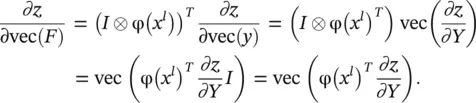
Both Eqs. (3.87)and (3.88)are used in the above derivation giving ∂z / ∂F = φ( x l) T ∂z / ∂Y , which is a simple rule to update the parameters in the l −th layer: the gradient with respect to the convolution parameters is the product between φ( x l) T(the im2col expansion) and ∂z / ∂Y (the supervision signal transferred from the ( l + 1)‐th layer).
Function φ( x l) has dimension H l + 1 W l + 1 HW D l. From the above, we know that its elements are indexed by a pair p , q . So far, from Eq. (3.84)we know: (i) from q we can determine d l, the channel of the convolution kernel that is used; and we can also determine i and j , the spatial offsets inside the kernel; (ii) from p we can determine i l + 1and j l + 1, the spatial offsets inside the convolved result x l + 1; and (iii) the spatial offsets in the input x lcan be determined as i l= i l + 1+ i and j l= j l + 1+ j . In other words, the mapping m : ( p , q ) → ( i l, j l, d l) is one to one, and thus is a valid function. The inverse mapping, however, is one to many (and thus not a valid function). If we use m −1to represent the inverse mapping, we know that m −1( i l, j l, d l) is a set S , where each ( p , q ) ∈ S satisfies m ( p , q ) = ( i l, j l, d l). Now we take a look at φ( x l) from a different perspective.
The question: What information is required in order to fully specify this function? It is obvious that the following three types of information are needed (and only those). The answer : For every element of φ( x l), we need to know
(A) Which region does it belong to, or what is the value of (0 ≤ p < H l + 1 W l + 1)?
(B) Which element is it inside the region (or equivalently inside the convolution kernel); that is, what is the value of q (0 ≤ q < HWDl )? The above two types of information determine a location ( p , q ) inside φ( x l). The only missing information is (C) What is the value in that position, that is, [φ( x l)] pq ?
Since every element in φ( x l) is a verbatim copy of one element from x l, we can reformulate question (C) into a different but equivalent one:
(C.1) Where is the value of a given [φ( x l)] pq copied from? Or, what is its original location inside x l, that is, an index u that satisfies 0 ≤ u < H l W l D l? (C.2) The entire x l.
It is easy to see that the collective information in [A, B, C.1] (for the entire range of p , q , and u , and (C.2) ( x l) contains exactly the same amount of information as φ( x l). Since 0 ≤ p < H l + 1 W l + 1, 0 ≤ q < HW D l, and 0 ≤ u < H l W l D l, we can use a a matrix 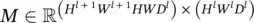 to encode the information in [A, B, C.1]. One row index of this matrix corresponds to one location inside φ( x l) (a( p , q ) pair). One row of M has H l W l D lelements, and each element can be indexed by ( i l, j l, d l). Thus, each element in this matrix is indexed by a 5‐tuple: ( p , q , i l, j l, d l).
to encode the information in [A, B, C.1]. One row index of this matrix corresponds to one location inside φ( x l) (a( p , q ) pair). One row of M has H l W l D lelements, and each element can be indexed by ( i l, j l, d l). Thus, each element in this matrix is indexed by a 5‐tuple: ( p , q , i l, j l, d l).
Интервал:
Закладка:
Похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks»
Представляем Вашему вниманию похожие книги на «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Artificial Intelligence and Quantum Computing for Advanced Wireless Networks» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.