Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Наша функция потерь выводится из выражения цели, приведенного выше в этой главе:
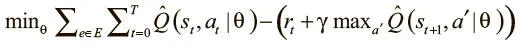
Мы хотим, чтобы предсказательная сеть равнялась целевой плюс выгода на текущем шаге. Это можно выразить в чистом коде TensorFlow в виде разницы между выводами предсказательной и целевой сетей. Этот градиент мы используем для обновления и обучения предсказательной сети с помощью AdamOptimizer.
Обновление целевой Q-сети
Чтобы гарантировать стабильную среду обучения, мы обновляем целевую Q-сеть через каждые четыре пакета. Правило обновления довольно простое: мы приравниваем ее веса к весам предсказательной сети. Для этого используется функция update_target_q_network(self). Можно применить tf.get_collection() для получения переменных областей действия предсказательной и целевой сетей. Мы можем пройти в цикле по этим переменным и запустить операцию tf.assign() для приравнивания весов целевой Q-сети к весам предсказательной.
Реализация повторения опыта
Мы уже говорили, что повторение опыта может помочь устранить корреляцию обновлений градиентных пакетов для повышения качества Q-обучения и выработанной на его основе стратегии. Рассмотрим кратко простой случай реализации повторения опыта. Задействуем метод add_episode(self, episode), который берет весь эпизод (объект EpisodeHistory) и добавляет его в ExperienceReplayTable. Затем он контролирует переполнение таблицы и удаляет оттуда самые старые значения опыта.
Когда дело доходит до выборки из таблицы, можно обратиться к sample_batch(self, batch_size) для случайной компоновки пакета:
class ExperienceReplayTable(object):
def __init__(self, table_size=5000):
self.states = []
self.actions = []
self.rewards = []
self.state_primes = []
self.discounted_returns = []
self.table_size = table_size
def add_episode(self, episode):
self.states += episode.states
self.actions += episode.actions
self.rewards += episode.rewards
self.discounted_returns += episode.discounted_returns
self.state_primes += episode.state_primes
self.purge_old_experiences()
def purge_old_experiences(self):
if len(self.states) > self.table_size:
self.states = self.states[-self.table_size:]
self.actions = self.actions[-self.table_size:]
self.rewards = self.rewards[-self.table_size:]
self.discounted_returns = self.discounted_returns[
— self.table_size:]
self.state_primes = self.state_primes[
— self.table_size:]
def sample_batch(self, batch_size):
s_t, action, reward, s_t_plus_1, terminal = [], [], [], [], []
rands = np.arange(len(self.states))
np.random.shuffle(rands)
rands = rands[: batch_size]
for r_i in rands:
s_t.append(self.states[r_i])
action.append(self.actions[r_i])
reward.append(self.rewards[r_i])
s_t_plus_1.append(self.state_primes[r_i])
terminal.append(self.discounted_returns[r_i])
return np.array(s_t), np.array(action),
np.array(reward), np.array(s_t_plus_1),
np.array(terminal)
Основной цикл DQN
Сведем всё воедино в основной функции, которая создаст среду OpenAI Gym для Breakout, выведет образец DQNAgent и заставит его взаимодействовать со средой и успешно обучаться игре в Breakout:
def main(argv):
# Configure Settings (Конфигурируем настройки)
run_index = 0
learn_start = 100
scale = 10
total_episodes = 500*scale
epsilon_stop = 250*scale
train_frequency = 4
target_frequency = 16
batch_size = 32
max_episode_length = 1000
render_start = total_episodes — 10
should_render = True
env = gym.make(‘Breakout-v0')
num_actions = env.action_space.n
solved = False
with tf.Session() as session:
agent = DQNAgent(session=session,
um_actions=num_actions)
session.run(tf.global_variables_initializer())
episode_rewards = []
batch_losses = []
replay_table = ExperienceReplayTable()
global_step_counter = 0
for i in tqdm.tqdm(range(total_episodes)):
frame = env.reset()
past_frames = [frame] * (agent.history_length-1)
state = agent.process_state_into_stacked_frames(
frame, past_frames, past_state=None)
episode_reward = 0.0
episode_history = EpisodeHistory()
epsilon_percentage = float(min(i/float(
epsilon_stop), 1.0))
for j in range(max_episode_length):
action = agent.predict_action(state,
epsilon_percentage)
if global_step_counter < learn_start:
action = random_action(agent.num_actions)
# print(action)
frame_prime, reward, terminal, _ = env.step(
action)
state_prime =
agent.process_state_into_stacked_frames(
frame_prime, past_frames,
past_state=state)
past_frames.append(frame_prime)
past_frames = past_frames[-4:]
if (render_start > 0 and (i >
render_start)
and should_render) or (solved and
should_render):
env.render()
episode_history.add_to_history(
state, action, reward, state_prime)
state = state_prime
episode_reward += reward
global_step_counter += 1
if j == (max_episode_length — 1):
terminal = True
if terminal:
episode_history.discounted_returns =
discount_rewards(
episode_history.rewards)
replay_table.add_episode(episode_history)
if global_step_counter > learn_start:
if global_step_counter %
train_frequency == 0:
s_t, action, reward, s_t_plus_1,
terminal = \
replay_table.sample_batch(
batch_size)
q_t_plus_1 = agent.target_q.eval(
{agent.target_s_t:
s_t_plus_1})
terminal = np.array(terminal) + 0.
max_q_t_plus_1 = np.max(q_t_plus_1,
axis=1)
target_q_t = (1. — terminal) * \
agent.gamma * max_q_t_plus_1 +
reward
_, q_t, loss = agent.session.run(
[agent.train_step, agent.q_t,
agent.loss], {
agent.target_q_t: target_q_t,
agent.action: action,
agent.s_t: s_t
})
if global_step_counter %
target_frequency == 0:
agent.update_target_q_weights()
episode_rewards.append(episode_reward)
break
if i % 50 == 0:
ave_reward = np.mean(episode_rewards[-100:])
print(ave_reward)
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.