Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
if ave_reward > 50.0:
solved = False
else:
solved = False
Результаты DQNAgent в Breakout
Мы обучаем DQNAgent на 1000 эпизодах и рассматриваем кривую обучения. Чтобы достичь на Atari результатов выше, чем у человека, обычно время обучения растягивается на несколько дней. Но общая восходящая тенденция в вознаграждениях проявляется быстро, что показано на рис. 9.7.
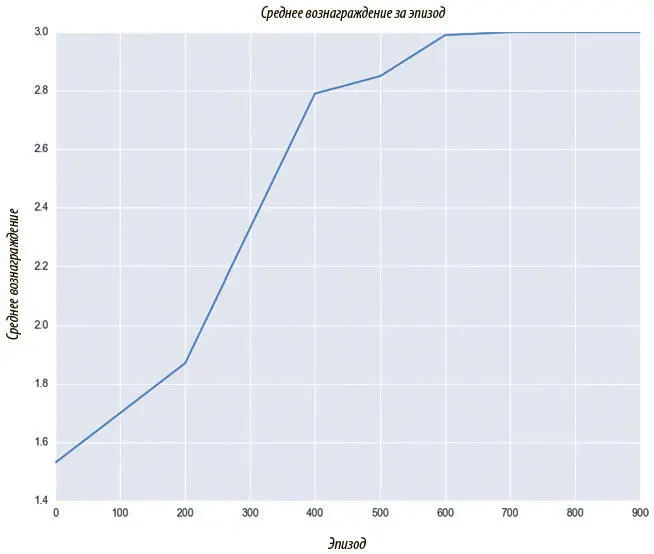
Рис. 9.7. Агент DQN показывает все более успешные результаты в Breakout во время обучения, усвоив хорошую функцию-значение, и действует все менее случайно благодаря ϵ-жадной нормализации
Улучшение и выход за пределы DQN
* * *
В 2013 году DQN прекрасно поработала над решением задач Atari, но имела ряд серьезных недостатков. Среди основных слабостей — слишком большое время обучения, неудачные результаты в определенных типах игр и необходимость повторного обучения для каждой новой задачи. Большинство исследований в области глубокого обучения с подкреплением в последние несколько лет было сосредоточено на устранении этих недостатков.
Глубокие рекуррентные Q-сети (DRQN)
Помните предположение Маркова — что следующее состояние зависит только от предыдущего и действия агента? Решение Маркова при помощи DQN, при котором четыре последовательных кадра помещаются в стек как отдельный канал, просто обходит проблему и во многом напоминает инженерную уловку. Почему кадров четыре, а не десять? Этот искусственный гиперпараметр ограничивает обобщающую способность модели. Как работать с произвольными последовательностями взаимосвязанных данных? Можно воспользоваться тем, что мы узнали в главе 6о рекуррентных нейронных сетях, для моделирования последовательностей при помощи глубоких рекуррентных Q-сетей (DRQN).
В DRQN рекуррентный слой используется для передачи латентного знания о состоянии с одного временного шага на другой. Благодаря этому модель может обучиться тому, сколько кадров обладает информацией, которую нужно включить в состояние, и даже тому, как выкидывать неинформативные кадры или запоминать информативные старые.
DRQN даже расширили, включив нейронный механизм внимания, о чем говорится в работе Ивана Сорокина и коллег «Глубокие рекуррентные Q-сети с вниманием; DAQRN» 2015 года [106]. Поскольку DRQN работает с последовательностью данных, она может уделять внимание конкретным ее фрагментам. Такая способность концентрироваться на деталях и повышает эффективность, и обеспечивает интерпретируемость модели, создавая логическое обоснование для предпринимаемых действий.
DRQN оказалась лучше, чем DQN, в играх-«стрелялках» от первого лица, например DOOM [107], а также продемонстрировала лучшие результаты в некоторых играх Atari с длинными временными зависимостями, например Seaquest [108].
Продвинутый асинхронный агент-критик (A3C)
Продвинутый асинхронный агент-критик (Asynchronous advantage actor-critic , A3C) — новый подход к глубокому обучению с подкреплением, представленный в DeepMind 2016 года «Асинхронные методы глубокого обучения с подкреплением» [109]. Поговорим о том, что это и в чем его преимущества перед DQN.
Подход A3C асинхронный , то есть можно распараллелить агент по нескольким потокам, что значительно сократит время на обучение, поскольку ускоряется симуляция среды. A3C запускает одновременно несколько сред для сбора опыта. Помимо повышения скорости, этот подход дает еще одно значительное преимущество: он еще больше снимает взаимозависимость опыта в пакетах, поскольку пакет одновременно заполняется опытом многих агентов, действующих по разным сценариям.
A3C использует метод агента-критика [110]. Он заключается в обучении как функции ценностей V(s t) — критик, так и стратегии π ( s t ) — агент. В этой главе мы выделили два разных подхода: обучение ценности и обучение стратегии. В A3C сочетаются сильные стороны обоих: функция ценностей критика улучшает стратегию агента.
A3C использует функцию преимущества вместо чистой дисконтированной будущей выгоды. При обучении стратегии мы хотим, чтобы агент получал штраф, выбирая действие, которое ведет к плохому подкреплению. A3C стремится к тому же, но критерием считает не вознаграждение, а преимущество, то есть разницу между предсказанным моделью и реальным качеством совершенного действия. Преимущество можно выразить так:
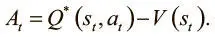
У A3C есть функция ценности, V(t), но она не выражает Q-функцию. Она оценивает преимущество, используя дисконтирование будущей выгоды как приближение Q-функции:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.