Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Нейроны гиперболического тангенса (tanh-нейроны) используют похожую S-образную нелинейность, но исходящие значения варьируют не от 0 до 1, а от −1 до 1. Формула для них предсказуемая: f(z) = tanh( z ). Отношения между входным значением y и логитом z показаны на рис. 1.12. Когда используются S-образные нелинейности, часто предпочитают tanh-нейроны, а не сигмоидные, поскольку у tanh-нейронов центр находится в 0.
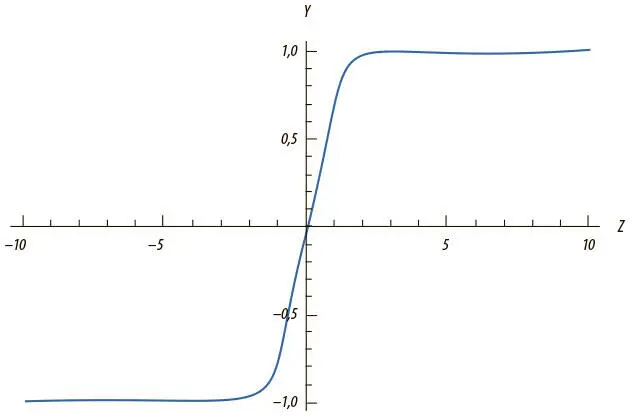
Рис. 1.12. Выходные данные tanh-нейрона с переменной z
Еще один тип нелинейности используется нейроном с усеченным линейным преобразованием (ReLU) . Здесь задействована функция f(z) = max(0, z ), и ее график имеет форму хоккейной клюшки (рис. 1.13).
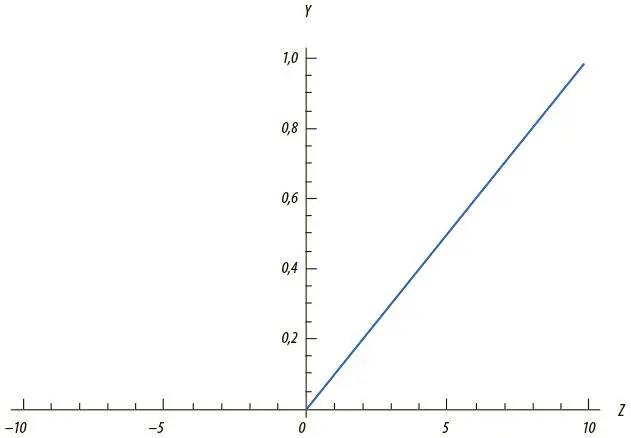
Рис. 1.13. Выходные данные ReLU-нейрона с переменной z
ReLU в последнее время часто выбирается для выполнения многих задач (особенно в системах компьютерного зрения) по ряду причин, несмотря на свои недостатки [8]. Этот вопрос мы рассмотрим в главе 5 вместе со стратегиями борьбы с потенциальными проблемами.
Выходные слои с функцией мягкого максимума
Часто нужно, чтобы выходной вектор был распределением вероятностей по набору взаимоисключающих значений. Допустим, нам нужно создать нейросеть для распознавания рукописных цифр из набора данных MNIST. Каждое значение (от 0 до 9) исключает остальные, но маловероятно, чтобы нам удалось распознать цифры со стопроцентной точностью. Распределение вероятностей поможет понять, насколько мы уверены в своих выводах. Желаемый выходной вектор приобретает такую форму, где 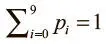 :
:
[p 0 p 1 p 2 p 3… p 9 ] .
Для этого используется особый выходной слой, именуемый слоем с мягким максимумом (softmax) . В отличие от других типов, выходные данные нейрона в слое с мягким максимумом зависят от выходных данных всех остальных нейронов в нем. Нам нужно, чтобы сумма всех выходных значений равнялась 1. Приняв z i как логит i -го нейрона с мягким максимумом, мы можем достичь следующей нормализации, задав выходные значения:
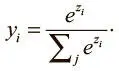
При сильном предсказании одно из значений вектора будет близко к 1, остальные — к 0. При слабом останется несколько возможных значений, каждое из которых характеризуется своим уровнем вероятности.
Резюме
В этой главе мы дали базовые представления о машинном обучении и нейросетях. Мы рассказали о структуре нейрона, работе нейросетей с прямым распространением сигнала и важности нелинейности в решении сложных задач обучения. В следующей главе мы начнем создавать математический фундамент для обучения нейросети решению задач. Например, мы поговорим о нахождении оптимальных векторов параметров, лучших методов обучения нейросетей и основных проблемах. В последующих главах мы будем применять эти основополагающие идеи к более специализированным вариантам архитектуры нейросетей.
Глава 2. Обучение нейросетей с прямым распространением сигнала
Проблема фастфуда
Мы начинаем понимать, как решать некоторые интересные задачи с помощью глубокого обучения, но остается важный вопрос: как определить, какими должны быть векторы параметров (веса всех соединений нейросети)? Ответ прост: в ходе процесса, часто именуемого обучением (рис. 2.1). Мы демонстрируем нейросети множество обучающих примеров и последовательно модифицируем веса, чтобы минимизировать ошибки, которые уже были совершены. Продемонстрировав достаточное число примеров, мы ожидаем, что нейросеть будет эффективно решать поставленную задачу.
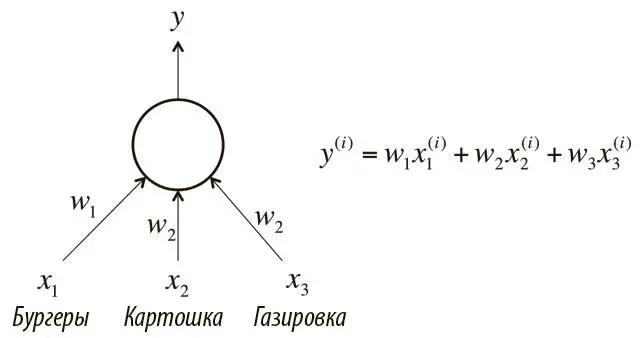
Рис. 2.1. Нейрон, который мы хотим обучить решать проблему фастфуда
Вернемся к примеру, который упоминали в предыдущей главе при обсуждении линейного нейрона. Итак: каждый день мы покупаем в ресторане быстрого обслуживания обед — бургеры, картошку и газировку, причем по несколько порций каждого наименования. Мы хотим предсказывать, сколько будет стоить обед, но ценников нет. Кассир сообщает только общую цену.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.