Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Разбор нейронной сети для перевода
Современные нейронные сети для перевода используют ряд методов и достижений, основанных всё на той же архитектуре кодера-декодера seq2seq. Внимание, рассмотренное в предыдущем разделе, — жизненно важное новшество. Ниже мы разберем полностью реализованную нейронную систему машинного перевода, дополним ее обработкой данных, построим модель, обучим ее и используем в качестве системы перевода английских фраз на французский! Работать мы будем с упрощенной версией официального учебного кода для машинного перевода TensorFlow [94].
Обучение и последующее использование нейронной системы машинного перевода очень похожи на большинство других процессов в области машинного обучения: сбор данных, их подготовка, построение модели, ее обучение, оценка ее качества и, наконец, использование обученной модели для получения полезных предсказаний или выводов. Все эти этапы мы и рассмотрим.
Сначала мы получаем данные из репозитория WMT'15, который содержит большие массивы, используемые для обучения систем перевода. Мы воспользуемся англо-французскими данными. Заметим, что если нужно будет переводить с нескольких или на несколько языков, то придется с нуля обучать модель на новых данных. Предварительно обрабатываем данные, преобразуя их в формат, который модели смогут использовать при обучении и логическом выводе. Для этого надо провести чистку и разбиение на токены предложений в каждой английской и французской фразе. Мы приведем методы, используемые в подготовке данных, и поговорим об их реализации.
Первый шаг — преобразовать предложения и фразы в совместимый с моделью формат путем разбиения на токены , или составляющие (и для английских, и для французских фраз). Например, простой пословный токенизатор, получив предложение I read. («я читаю»), выдаст набор ["I", "read","."], а из французского предложения Je lis. сделает набор ["Je", "lis","."]. Посимвольный токенизатор разобьет предложение на отдельные символы или пары символов, получится ["I", " ", "r", "e", "a", "d", "."] и ["I", " "re", "ad", "."] соответственно.
В каждом случае нужно решить, какое разбиение лучше: у обоих есть свои достоинства и недостатки. Например, пословный токенизатор обеспечит выдачу слов из словаря, но размер последнего может быть слишком велик для эффективного выбора во время декодирования. Эта проблема известна, мы обратимся к ней позже. Токенизатор на основе посимвольного разбиения не всегда может выдать читабельные данные, но словарь, из которого декодер выбирает варианты, гораздо меньше: это набор всех печатаемых символов ASCII. Мы используем пословное разбиение, но читателю предлагаем поэкспериментировать с разными вариантами и посмотреть на результаты. Нам придется добавить EOS — особый символ конца последовательности — по окончании всех входных последовательностей, поскольку нам нужен способ указать декодеру, что он завершил работу. Обычную пунктуацию использовать нельзя, ведь мы не можем по умолчанию считать, что переводим полные предложения. В наших входных последовательностях символы EOS не нужны, поскольку они уже отформатированы и нам не надо специально отмечать конец каждой исходной последовательности.
Следующий шаг — новые изменения представления каждого входного и выходного предложения. Здесь мы вводим идею группирования . Этот метод используется в основном в задачах вроде seq2seq, особенно при машинном переводе, и помогает модели эффективно обрабатывать предложения или фразы разной длины. Сначала рассмотрим простейший метод ввода обучающих данных и покажем его недостатки. При введении токенов в кодер и декодер длина исходной и целевой последовательностей в парах данных для обучения не всегда идентична. Например, исходная последовательность может иметь длину X, а целевая — Y. Кажется, что нам нужны разные сети seq2seq для каждой пары (X, Y), что сразу можно расценить как неэффективную трату сил и времени. Чуть лучше пойдут дела, если мы дополним каждую последовательность до определенной длины, как показано на рис. 7.28 (считаем, что мы используем пословное разбиение и уже добавили в целевые последовательности метки EOS).
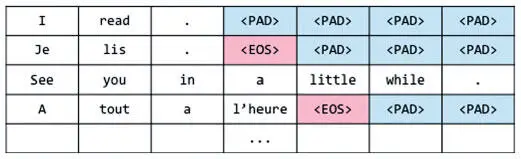
Рис. 7.28. Наивная стратегия дополнения последовательностей
Этот шаг дает возможность не создавать разные модели seq2seq для каждой пары исходной и целевой длины. Но при этом возникает проблема иного рода: если найдется очень длинная последовательность, все остальные придется дополнять до этой длины . И дополненная короткая последовательность будет требовать столько же вычислительных ресурсов, что и длинная с небольшим количеством заполнителей, а это приведет к трате сил и может крайне негативно сказаться на производительности нашей модели. Допустимо разбить каждую последовательность в корпусе на фразы, чтобы длина каждой из них не превышала определенного максимального значения, но не вполне понятно, как разбивать переводы. Здесь-то и поможет группирование.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.