Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Группирование основано на том, что пары кодера и декодера можно поместить в группы сходного размера и дополнять до максимальной длины последовательности в каждой соответствующей группе. Например, допустимо обозначить ряд групп [(5, 10), (10, 15), (20, 25), (30,40)], где каждая запись — максимальная длина исходной и целевой последовательностей соответственно. Если вернуться к предыдущему примеру, то можно поместить пару последовательностей (["I", "read", "."], ["Je", "lis", ".", "EOS"]) в первую группу, поскольку исходное предложение меньше пяти токенов, а целевое — меньше 10. Во вторую группу помещаем набор (["See", "you", "in", "a", "little", "while"], ["A", "tout", "a","l'heure", "EOS]) и т. д. Этот метод позволяет найти компромисс между двумя экстремумами: теперь дополнять можно ровно столько, сколько необходимо, что и показано на рис. 7.29.
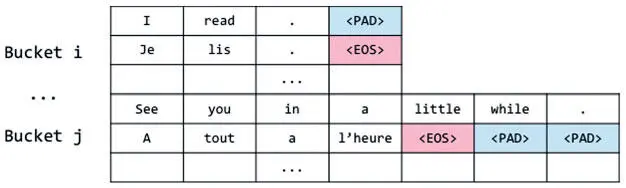
Рис. 7.29. Дополнение последовательностей в группах
Группирование позволяет существенно ускорить время обучения и тестирования, а разработчикам дает возможность писать оптимизированный код, используя то обстоятельство, что все последовательности из одной группы имеют один размер, и упаковывать данные для повышения эффективности работы GPU.
Как только все дополнения последовательностей выполнены, добавляем в целевые последовательности еще один токен — GO . Он говорит декодеру, что пора начать декодирование. Тот действует соответственно.
Последнее, что нужно делать во время подготовки данных, — переворачивать исходные предложения. Исследователи установили, что это повышает эффективность, и это действие стало стандартным при обучении нейронных моделей машинного перевода. Это своего рода трюк, но вспомните, что наше нейронное состояние фиксированного размера и, соответственно, не может содержать информации больше определенного предела. Получается, информация, закодированная при обработке начала предложения, может подвергнуться перезаписи при кодировании последующих фрагментов.
Во многих языковых парах начало предложений перевести сложнее, чем конец, и переворачивание повышает точность: последнее слово на финальной стадии кодирования остается за началом последовательности. После реализации всех этих идей конечные последовательности должны выглядеть так, как на рис. 7.30.
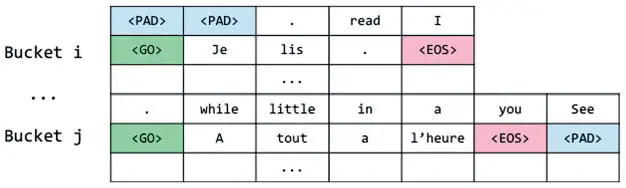
Рис. 7.30. Итоговая схема дополнения в группах после переворачивания данных и добавления метки GO
Описав эти техники, мы можем перейти к подробностям реализации. Идеи реализованы в методе get_batch() кода. Он получает отдельный пакет обучающих данных, учитывая bucket_id, который берется из цикла обучения. В результате создаются токены для исходного и целевого предложений, метод задействует все описанные выше техники, включая дополнение в группах и переворачивание ввода:
def get_batch(self, data, bucket_id):
encoder_size, decoder_size = self.buckets[bucket_id]
encoder_inputs, decoder_inputs = [], []
Сначала мы задаем заполнители для каждого входного значения, поступающего в кодер и декодер:
for _ in xrange(self.batch_size):
encoder_input, decoder_input = random.choice(data[bucket_id])
# Encoder inputs are padded and then reversed. (Входные данные кодера дополняются и переворачиваются)
encoder_pad = [data_utils.PAD_ID] * (encoder_size — len(encoder_input))
encoder_inputs.append(list(reversed(encoder_input + encoder_pad)))
# Decoder inputs get an extra "GO" symbol,
# and are then padded. (Входные данные декодера получают дополнительный символ "GO" и затем переворачиваются)
decoder_pad_size = decoder_size — len(decoder_input) — 1
decoder_inputs.append([data_utils.GO_ID] + decoder_input + [data_utils.PAD_ID] * decoder_pad_size)
В соответствии с размером пакета мы берем соответствующее количество кодирующих и декодирующих последовательностей:
# Now we create batch-major vectors from the data selected
# above. (Теперь создаем пакетные векторы на основании выбранных выше данных)
batch_encoder_inputs, batch_decoder_inputs, batch_weights =
[], [], []
# Batch encoder inputs are just re-indexed encoder_inputs. (Пакетные вводы кодера — переформатированные encoder_inputs)
for length_idx in xrange(encoder_size):
batch_encoder_inputs.append(
np.array([encoder_inputs[batch_idx][length_idx]
for batch_idx in xrange(self.batch_size)],
dtype=np.int32))
# Batch decoder inputs are re-indexed decoder_inputs,
# we create weights. (Пакетные вводы декодера — переформатированные decoder_inputs, мы назначаем веса)
for length_idx in xrange(decoder_size):
batch_decoder_inputs.append(
np.array([decoder_inputs[batch_idx][length_idx]
for batch_idx in xrange(self.batch_size)], dtype=np.int32))
Убеждаемся, что первое измерение тензора — размер мини-пакета, и преобразуем определенные ранее заполнители в нужный формат:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.