Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Дополнение рекуррентных сетей вниманием
Продолжим разговор о проблемах перевода. Если вы когда-то пытались выучить иностранный язык, то знаете, что именно помогает успешному переводу. Во-первых, стоит полностью прочесть предложение, чтобы понять, какую идею нужно передать. Затем вы слово за словом записываете перевод, и каждое слово вытекает из предыдущего. При этом, составляя новое предложение, вы часто обращаетесь к исходному тексту, сосредоточиваясь на определенных фрагментах, которые важны для текущего перевода. На каждом шаге вы обращаете внимание на самые важные в данный момент части «входных данных», чтобы принять наилучшее решение по поводу следующего слова, которое должно будет появиться на бумаге.
Вернемся к нашему подходу к seq2seq. Прочтя полностью входные данные и резюмируя их в виде «мысли» в скрытом состоянии, сеть кодера фактически копирует первую часть процесса перевода. Используя предшествующие выходные данные как текущие входные, сеть декодера реализует вторую часть процесса. Это явление внимания еще не отражено в нашем подходе к seq2seq, так что сейчас мы этим и займемся.
Единственные входные данные декодера на шаге t — его выходные на шаге ( t − 1). Один из способов дать сети декодера представление об исходном предложении — предоставить доступ ко всему выводу кодера (который мы пока игнорировали). Эти выходные данные интересуют нас, поскольку отражают изменение внутреннего состояния кодера после поступления каждого нового токена. Предлагаемая реализация этой стратегии показана на рис. 7.26.
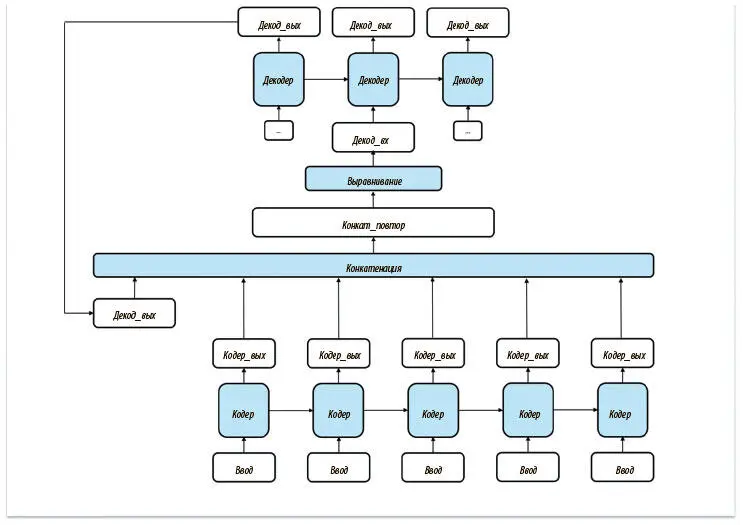
Рис. 7.26. Попытка ввести внимание в архитектуру seq2seq. Нас ждет неудача, поскольку сеть не может динамически выбирать самые важные части входных данных и сосредоточиваться на них
Но у этого подхода обнаруживается важный недостаток. На каждом шаге декодер рассматривает все выходные данные кодера одинаково. Человек же в процессе перевода действует не так. Работая над разными фрагментами, мы сосредоточиваемся на разных аспектах оригинала. Важно понять, что дать декодеру доступ ко всем выходным данным недостаточно. Нужно придумать механизм, с помощью которого он мог бы динамически обращать внимание на конкретную подвыборку выходных данных кодера.
Проблему можно решить, подвергнув входные данные конкатенации. Поможет в этом предложение, внесенное в 2015 году Дмитрием Баданау и коллегами [93]. Вместо того чтобы непосредственно работать с сырыми выходными данными из кодера, мы присваиваем им веса. Для этого используем состояние сети декодера в момент ( t − 1) как основу.
Операция присвоения весов показана на рис. 7.27. Сначала назначаем скалярный (одно число, а не тензор) коэффициент релевантности для каждого выходного значения кодера. Для этого вычисляем скалярное произведение каждого вывода кодера и состояния декодера на шаге ( t − 1). Затем нормализуем эти результаты с помощью операции мягкого максимума. Наконец, с помощью нормализованных результатов индивидуально оцениваем все выходные значения кодера, прежде чем начать конкатенацию. Важно, что относительные показатели для каждого выходного значения кодера отражают степень его важности для решения декодера на шаге t . Позже мы покажем, как визуализировать то, какие элементы выходных данных наиболее важны для перевода на каждом шаге, с помощью анализа выходных данных операции мягкого максимума.
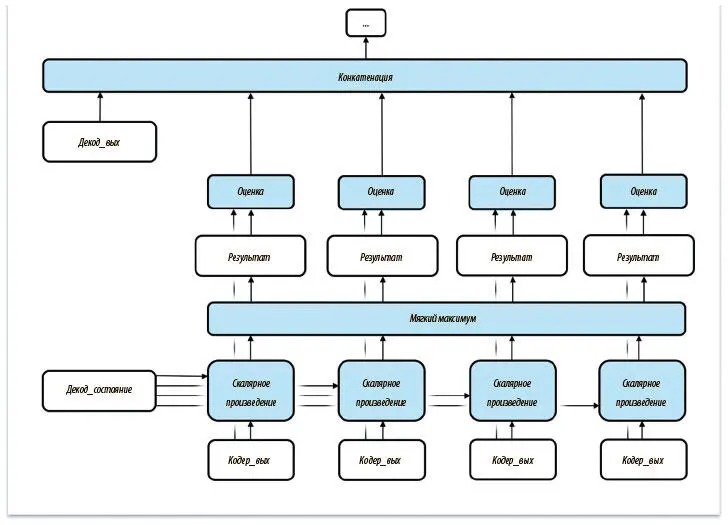
Рис. 7.27. Внесение изменений в первичный вариант позволяет создать динамический механизм внимания на основе скрытого состояния сети декодера на предыдущем шаге
Вооружившись пониманием стратегии введения внимания в архитектуру seq2seq, мы готовы заняться построением модели РНС для перевода английских предложений на французский. Но сначала стоит отметить, что внимание очень важно и для других проблем, не связанных с переводом. Оно может сыграть свою роль в задаче распознавания языка, когда алгоритм обучается динамически обращать внимание на соответствующие части аудиофайла при его переводе в текст. Оно применимо для улучшения алгоритма описания изображений и дает ему возможность фокусироваться на конкретных фрагментах входного изображения при создании описания. Если существуют отдельные элементы входных данных, которые тесно связаны с верным воспроизводством соответствующих сегментов выходных данных, внимание может существенно повысить производительность.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.