Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
$ pip install tflearn
Теперь можно загрузить базу данных, выбрать из словаря 30 тысяч самых распространенных слов, ограничить длину входных последовательностей 500 словами [90]и обработать метки:
from tflearn.data_utils import to_categorical, pad_sequences
from tflearn.datasets import imdb
train, test, _ = imdb.load_data(path='data/imdb.pkl',
n_words=30000,
valid_portion=0.1)
trainX, trainY = train
testX, testY = test
trainX = pad_sequences(trainX, maxlen=500, value=0.)
testX = pad_sequences(testX, maxlen=500, value=0.)
trainY = to_categorical(trainY, nb_classes=2)
testY = to_categorical(testY, nb_classes=2)
Теперь наши входные данные — 500-мерные векторы. Каждый соответствует кинорецензии, причем i -й компонент вектора сопоставлен индексу i -го слова в рецензии в нашем общем словаре из 30 тысяч единиц. Чтобы закончить подготовку, создадим особый класс Python для подачи мини-пакетов желаемого размера из основной базы данных:
class IMDBDataset():
def __init__(self, X, Y):
self.num_examples = len(X)
self.inputs = X
self.tags = Y
self.ptr = 0
def minibatch(self, size):
ret = None
if self.ptr + size < len(self.inputs):
ret = self.inputs[self.ptr: self.ptr+size], self.tags[self.ptr: self.ptr+size]
else:
ret = np.concatenate((self.inputs[self.ptr: ], self.inputs[: size-len(self.inputs[self.ptr: ])])),
np.concatenate((self.tags[self.ptr: ], self.tags[: size-len(self.tags[self.ptr: ])]))
self.ptr = (self.ptr + size) % len(self.inputs)
return ret
train = IMDBDataset(trainX, trainY)
val = IMDBDataset(testX, testY)
Класс Python IMDBDataset используется для подачи как обучающих, так и проверочных данных, которые будут использоваться в обучении нашей модели анализа эмоциональной окраски.
Итак, данные готовы, приступим к пошаговому созданию модели анализа эмоциональной окраски. Для начала нужно привязать каждое слово из входной рецензии к вектору слов. Для этого используется слой плотного векторного представления, который, как вы наверняка помните из предыдущей главы, представляет собой простую таблицу соответствия. Она хранит вектор плотного представления, сопоставленный каждому слову. В отличие от предыдущих примеров, когда обучение векторных представлений слов мы рассматривали как отдельную проблему (и создавали, например, модель Skip-Gram), мы будем обучать векторные представления слов вместе с проблемой анализа эмоциональной окраски и считать матрицу векторных представлений матрицей параметров общей проблемы. Воспользуемся примитивами TensorFlow для управления плотными векторными представлениями (помните, что входные данные — это один полный мини-пакет, а не просто вектор кинорецензии):
def embedding_layer(input, weight_shape):
weight_init = tf.random_normal_initializer(stddev=(1.0/weight_shape[0])**0.5)
E = tf.get_variable("E", weight_shape, initializer=weight_init)
incoming = tf.cast(input, tf.int32)
embeddings = tf.nn.embedding_lookup(E, incoming)
return embeddings
Затем берем результат из слоя векторных представлений слов и строим LSTM с прореживанием при помощи тех же примитивов, что и в предыдущем разделе. Проделаем небольшую дополнительную работу, чтобы сохранить последнее значение, выданное LSTM, при помощи операторов tf.slice и tf.squeeze, которые находят фрагмент, где содержится последний вывод LSTM, и устраняют ненужные измерения. Смена измерений выглядит так:
[batch_size, max_time, cell.output_size] to [batch_size, 1, cell.out put_size] to [batch_size, cell.output_size].
Реализовать LSTM можно следующим образом:
def lstm(input, hidden_dim, keep_prob, phase_train):
lstm = tf.nn.rnn_cell.BasicLSTMCell(hidden_dim)
dropout_lstm = tf.nn.rnn_cell.DropoutWrapper(lstm,
input_keep_prob=keep_prob,
output_keep_prob=keep_prob)
# stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(
[dropout_lstm] * 2,
state_is_tuple=True)
lstm_outputs, state = tf.nn.dynamic_rnn(dropout_lstm,
input, dtype=tf.float32)
return tf.squeeze(tf.slice(lstm_outputs,
[0, tf.shape(
lstm_outputs)[1]-1, 0],
[tf.shape(lstm_outputs)[0],
1, tf.shape(
lstm_outputs)[2]])
В завершение мы добавляем скрытый слой пакетной нормализации, идентичный тем, которые мы использовали в предыдущих примерах. Собрав все компоненты вместе, мы можем перейти к построению графа логического вывода:
def inference(input, phase_train):
embedding = embedding_layer(input, [30000, 512])
lstm_output = lstm(embedding, 512, 0.5, phase_train)
output = layer(lstm_output, [512, 2], [2], phase_train)
return output
Опустим остальной шаблонный код, который сохраняет сводную статистику, промежуточные состояния и создает сессию: он такой же, как и остальные модели, уже созданные в этой книге; вы можете посмотреть исходный код в репозитории GitHub. Теперь можно запустить и визуализировать работу модели при помощи TensorBoard (рис. 7.23).
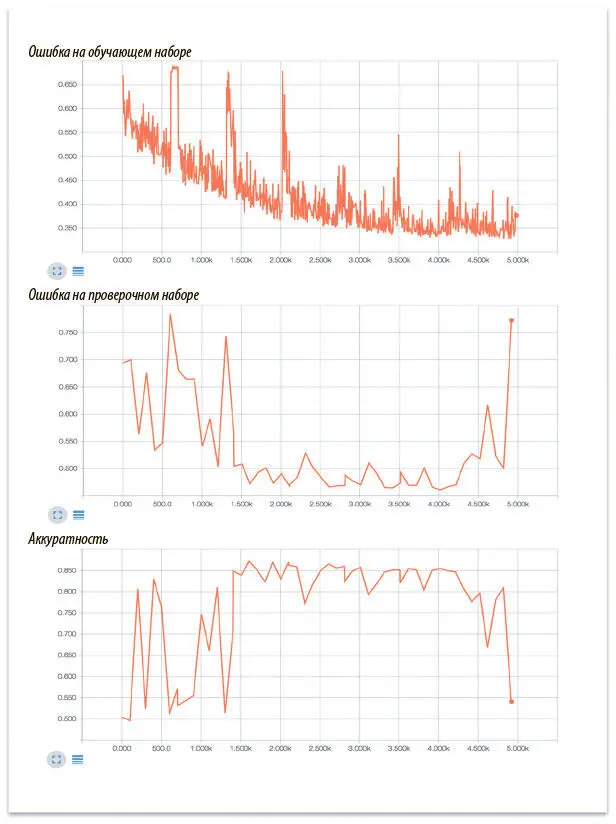
Рис. 7.23. Ошибка на обучающем и проверочном наборах данных, а также аккуратность модели анализа эмоциональной окраски кинорецензий
В начале обучения модель несколько нестабильна, а в конце явно происходит переобучение, поскольку ошибки на обучающем и проверочном наборах начинают сильно различаться. В период же оптимальной работы модель демонстрирует эффективные результаты и показывает на тестовом наборе данных аккуратность примерно 86%. Поздравляем! Вы создали свою первую рекуррентную нейронную сеть.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.