Нихиль Будума - Основы глубокого обучения
Здесь есть возможность читать онлайн «Нихиль Будума - Основы глубокого обучения» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Манн, Иванов и Фербер, Жанр: economics, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы глубокого обучения
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:9785001464723
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы глубокого обучения: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы глубокого обучения»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы глубокого обучения — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы глубокого обучения», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
После операции изменения размерности мы при помощи полносвязного слоя сжимаем сглаженное отображение до скрытого состояния размером 1024. Вероятность прореживания в этом слое мы определяем как 0,5 при обучении и 1 во время оценки модели (стандартная процедура при использовании прореживания). Мы отправляем это скрытое состояние в исходящий слой мягкого максимума с 10 выходами (softmax, как обычно, вычисляется в конструкторе loss для повышения эффективности).
Наконец, мы обучаем сеть при помощи оптимизатора Adam. После нескольких эпох работы с набором данных мы получаем точность 99,4% — не шедевр (все-таки не 99,7–99,8%), но очень даже неплохо.
Предварительная обработка изображений улучшает работу моделей
Пока мы имели дело с простыми наборами данных. Почему MNIST считается таковым? В целом потому, что он уже прошел предварительную обработку и все изображения в нем похожи друг на друга. Рукописные цифры расположены примерно одинаково; нет отклонений цвета, поскольку MNIST включает черно-белые изображения, и т. д. Естественные же изображения — совсем другой уровень сложности. Они выглядят беспорядочно, и можно выполнить несколько операций по их предварительной обработке, чтобы облегчить обучение. Первая методика, которая поддерживается в TensorFlow, — приближенное выбеливание. Главная задача — сместить к 0 каждый пиксел в изображении, вычтя среднее значение и нормализовав дисперсию до 1. В TensorFlow это достигается так:
tf.image.per_image_whitening(image)
Можно искусственно расширить набор данных, случайным образом обрезав изображение, повернув его, изменив насыщенность или яркость и т. д.:
tf.random_crop(value, size, seed=None, name=None)
tf.image.random_flip_up_down(image, seed=None)
tf.image.random_flip_left_right(image, seed=None)
tf.image.transpose_image(image)
tf.image.random_brightness(image, max_delta, seed=None)
tf.image.random_contrast(image, lower, upper, seed=None)
tf.image.random_saturation(image, lower, upper, seed=None)
tf.image.random_hue(image, max_delta, seed=None)
Применение таких трансформаций позволяет создавать сети, эффективные при различных вариациях, которые встречаются в естественных изображениях, и делать предсказания с высокой точностью, несмотря на потенциальные искажения.
Ускорение обучения с помощью пакетной нормализации
В 2015 году исследователи из Google разработали замечательный способ ускорить обучение сетей с прямым распространением сигнала и сверточных с помощью пакетной нормализации [66]. Этот процесс можно визуализировать, представив себе башню из строительных кирпичиков (рис. 5.15).
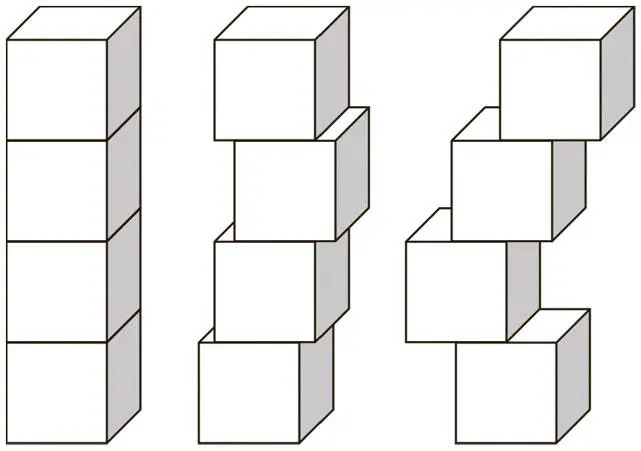
Рис. 5.15. Когда кирпичики в башне смещаются слишком сильно и перестают быть единым целым, структура может стать очень нестабильной
Когда кирпичи в башне сложены аккуратно, структура стабильна. Но если мы случайным образом сдвигаем их, это может привести к нарастанию нестабильности башни: со временем она упадет и развалится.
Похожее явление наблюдается при обучении нейронных сетей. Представьте себе двухслойную нейронную сеть. В процессе обучения весов сети распределение на выходе нейронов в нижнем слое начинает смещаться. В результате верхний слой должен будет не только научиться делать соответствующие предсказания, но и измениться сам, чтобы нивелировать сдвиги во входном распределении. Это значительно замедляет процесс обучения, и проблемы нарастают с увеличением числа слоев.
Нормализация входных изображений улучшает процесс, делая его более устойчивым к вариациям. Пакетная нормализация делает шаг вперед, нормализуя данные на входе во все слои нейронной сети.
Мы модифицируем архитектуру сети, вводя операции, которые выполняют следующие функции.
1. Перехватывают векторы логитов, поступающие в слой, до того как те дойдут до нелинейности.
2. Нормализуют каждый компонент вектора логитов по всем примерам мини-выборки, вычитая среднее и деля на стандартное отклонение (мы записываем импульсы, используя экспоненциально взвешенное скользящее среднее).
3. Получив нормализованные входящие значения  , используют аффинные преобразования для восстановления репрезентативности с двумя векторами (обучаемых) параметров:
, используют аффинные преобразования для восстановления репрезентативности с двумя векторами (обучаемых) параметров:  .
.
В TensorFlow пакетная нормализация для сверточного слоя может выглядеть так:
def conv_batch_norm(x, n_out, phase_train):
beta_init = tf.constant_initializer(value=0.0, dtype=tf.float32)
gamma_init = tf.constant_initializer(value=1.0, dtype=tf.float32)
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы глубокого обучения»
Представляем Вашему вниманию похожие книги на «Основы глубокого обучения» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы глубокого обучения» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.