Bioinformatics
Здесь есть возможность читать онлайн «Bioinformatics» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Bioinformatics
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Bioinformatics: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Bioinformatics»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
“This book is a gem to read and use in practice.”
— "This volume has a distinctive, special value as it offers an unrivalled level of details and unique expert insights from the leading computational biologists, including the very creators of popular bioinformatics tools."
— “A valuable survey of this fascinating field. . . I found it to be the most useful book on bioinformatics that I have seen and recommend it very highly.”
— “This should be on the bookshelf of every molecular biologist.”
— The field of bioinformatics is advancing at a remarkable rate. With the development of new analytical techniques that make use of the latest advances in machine learning and data science, today’s biologists are gaining fantastic new insights into the natural world’s most complex systems. These rapidly progressing innovations can, however, be difficult to keep pace with.
The expanded fourth edition of the best-selling
aims to remedy this by providing students and professionals alike with a comprehensive survey of the current field. Revised to reflect recent advances in computational biology, it offers practical instruction on the gathering, analysis, and interpretation of data, as well as explanations of the most powerful algorithms presently used for biological discovery.
offers the most readable, up-to-date, and thorough introduction to the field for biologists at all levels, covering both key concepts that have stood the test of time and the new and important developments driving this fast-moving discipline forwards.
This new edition features:
New chapters on metabolomics, population genetics, metagenomics and microbial community analysis, and translational bioinformatics A thorough treatment of statistical methods as applied to biological data Special topic boxes and appendices highlighting experimental strategies and advanced concepts Annotated reference lists, comprehensive lists of relevant web resources, and an extensive glossary of commonly used terms in bioinformatics, genomics, and proteomics
is an indispensable companion for researchers, instructors, and students of all levels in molecular biology and computational biology, as well as investigators involved in genomics, clinical research, proteomics, and related fields.
Bioinformatics — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Bioinformatics», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The Method
Starting with a query sequence of interest, the PSI-BLAST process operates by taking a query protein sequence and performing a standard BLASTP search, as described above. This search produces a number of hits having E values better than a certain set threshold. These hits, along with the initial, single-query sequence, are used to construct a PSSM in an automated fashion. As soon as the PSSM is constructed, the PSSM then serves as the query for doing a new search against the target database, using the collective characteristics of the identified sequences to find new, related sequences. The process continues, round by round, either until the search converges (meaning that no new sequences were found in the last round) or until the limit on the number of iterations is reached.
Performing a PSI-BLAST Search
PSI-BLAST searches can be initiated by following the Protein BLAST link on the BLAST landing page ( Figure 3.5). The search page shown in Figure 3.14is identical to the one shown in the BLASTP example discussed earlier in this chapter. Here, the sequence of the human sex-determining protein SRY from UniProtKB/Swiss-Prot (Q05066) will be used as the query, using UniProtKB/Swiss-Prot as the target database and limiting returned results to human sequences. PSI-BLAST is selected in the Program Selection section and, as before, selected changes will be made to the default parameters ( Figure 3.15). The maximum number of target sequences has been raised from 500 to 1000, as a safeguard in case a large number of sequences in UniProtKB/Swiss-Prot match the query. In addition, both the E value threshold and the PSI-BLAST threshold have been changed to 0.001, and filtering of low-complexity regions has been enabled. The query can now be issued as before by clicking on the blue “BLAST” button at the bottom of the page.

Figure 3.13 Constructing a position-specific scoring matrix (PSSM). In the upper portion of the figure is a multiple sequence alignment of length 10. Using the criteria described in the text, the PSSM corresponding to this multiple sequence alignment is shown in the lower portion of the figure. Each row of the PSSM corresponds to a column in the multiple sequence alignment. Note that position 8 of the alignment always contains a threonine residue (T), whereas position 10 always contains a glycine (G). Looking at the corresponding scores in the matrix, in row 8, the threonine scores 150 points; in row 10, the glycine also scores 150 points. These are the highest values in the row, corresponding to the fact that the multiple sequence alignment shows absolute conservation at those positions. Now, consider position 9, where most of the sequences have a proline (P) at that position. In row 9 of the PSSM, the proline scores 89 points – still the highest value in the row, but not as high a score as would have been conferred if the proline residue was absolutely conserved across all sequences. The first column of the PSSM provides the deduced consensus sequence.
The results of the first round of the search are shown in Figure 3.16, with 31 sequences found in the first round (at the time of this writing). The structure of the hit list table is exactly as before, now containing two additional columns that are specific to PSI-BLAST. The first shows a column of check boxes that are all selected; this instructs the algorithm to use all the sequences to construct the first PSSM for this particular search. Keeping in mind that the first round of any PSI-BLAST search is simply a BLASTP search and that no PSSM has yet been constructed, the second column is blank. To run the next iteration of PSI-BLAST, simply click the “Go” button at the bottom of this section. At this point, the first PSSM is constructed based on a multiple sequence alignment of the sequences selected for inclusion, and the matrix is now used as the query against Swiss-Prot. The results of this second round are shown in Figure 3.17, with the final two columns indicating which sequences are to be used in constructing the new PSSM for the next round of searches, as well as which sequences were used to build the PSSM for the current round. Also note that a good number of the sequences are highlighted in yellow; here, 26 additional sequences that scored below the PSI-BLAST threshold in the first round have now been pulled into the search results. This provides an excellent example of how PSSMs can be used to discover new relationships during each PSI-BLAST iteration, thereby making it possible to identify additional homologs that may not have been found using the standard BLASTP approach. Of course, the user should always check the E values and percent identities for all returned results before passing them through to the next round, unchecking inclusion boxes as needed. There may also be cases where prior knowledge would argue for removing some of the found sequences based on the descriptors. As with all computational methods, it is always important to keep biology in mind when reviewing the results.
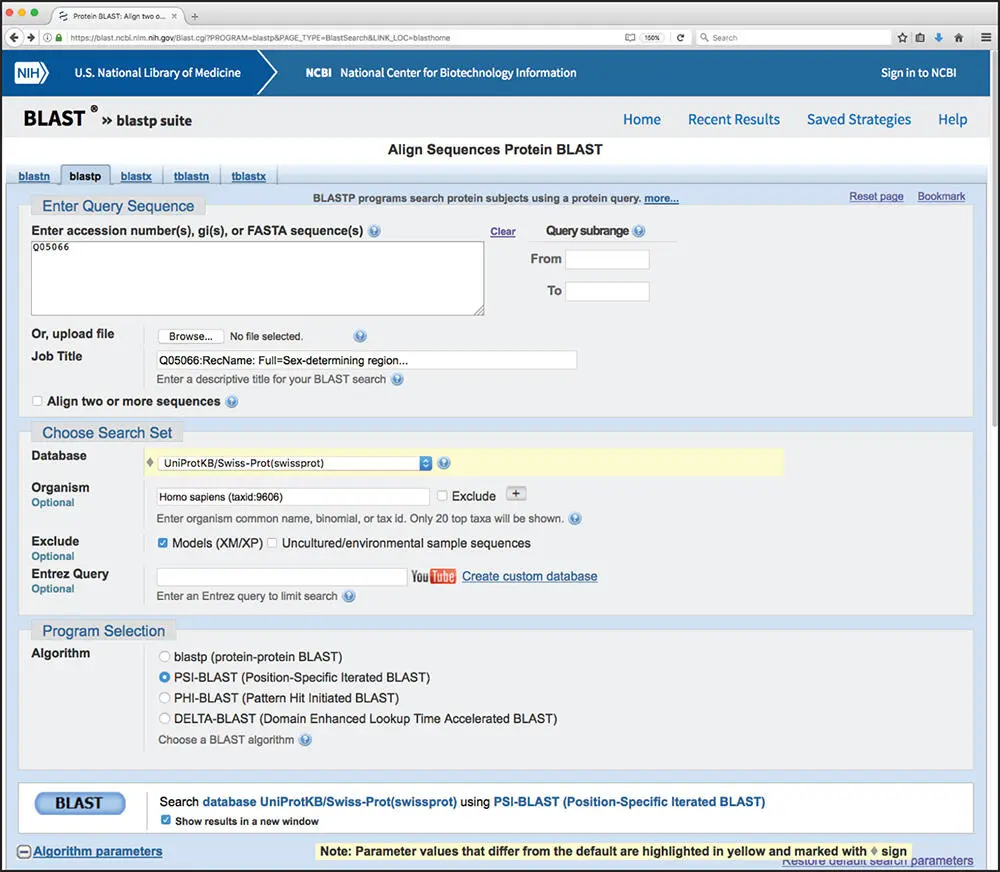
Figure 3.14 Performing a PSI-BLAST search. See text for details.
BLAT
In response to the assembly needs of the Human Genome Project, a new nucleotide sequence alignment program called BLAT (for BLAST-Like Alignment Tool) was introduced (Kent 2002). BLAT is most similar to the MegaBLAST version of BLAST in that it is designed to rapidly align longer nucleotide sequences having more than 95% similarity. However, the BLAT algorithm uses a slightly different strategy than BLAST to achieve faster speeds. Before any searches are performed, the target databases are pre-indexed, keeping track of all non-overlapping 11-mers; this index is then used to find regions similar to the query sequence. BLAT is often used to find the position of a sequence of interest within a genome or to perform cross-species analyses.
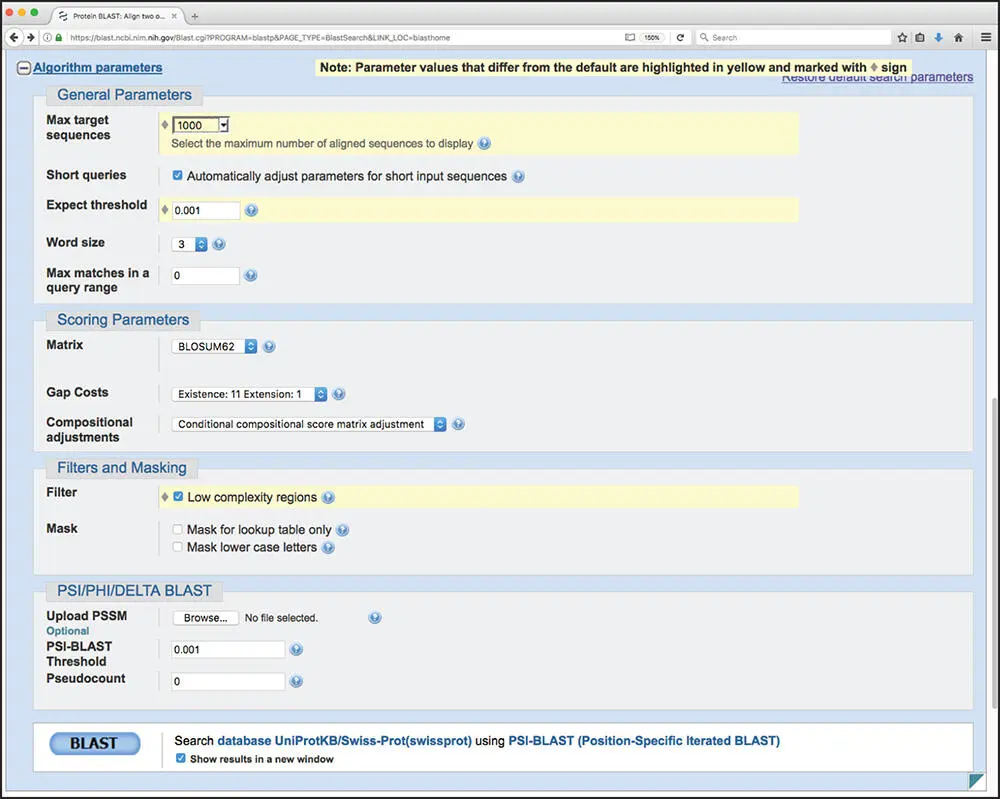
Figure 3.15 Selecting algorithm parameters for a PSI-BLAST search. See text for details.
As an example, consider a case where an investigator wishes to map a cDNA clone coming from the Cancer Genome Anatomy Project (CGAP) to the rat genome. The BLAT query page is shown in Figure 3.18, and the sequence of the clone of interest has been pasted into the sequence box. Above the sequence box are several pull-down menus that can be used to specify which genome should be searched (organism), which assembly should be used (usually, the most recent), and the query type (DNA, protein, translated DNA, or translated RNA). Once the appropriate choices have been made, the search is commenced by pressing the “Submit” button. The results of the query are shown in the upper panel of Figure 3.19; here, the hit with the highest score is shown at the top of the list, a match having 98.1% identity with the query sequence. More details on this hit can be found by clicking the “details” hyperlink, to the left of the entry. A long web page is then returned, providing information on the original query, the genomic sequence, and an alignment of the query against the found genomic sequence ( Figure 3.19, bottom panel). The genomic sequence here is labeled chr5, meaning that the query corresponds to a region of rat chromosome 5. Matching bases in the cDNA and genomic sequences are colored in dark blue and are capitalized. Lighter blue uppercase bases mark the boundaries of aligned regions and often signify splice sites. Gaps and unaligned regions are indicated by lower case black type. In the Side by Side Alignment, exact matches are indicated by the vertical line between the two sequences. Clicking on the “browser” hyperlink in the upper panel of Figure 3.19would take the user to the UCSC Genome Browser, where detailed information about the genomic assembly in this region of rat chromosome 5 (specifically, at 5q31) can be obtained (cf. Chapter 4).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Bioinformatics»
Представляем Вашему вниманию похожие книги на «Bioinformatics» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.




Обсуждение, отзывы о книге «Bioinformatics» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.