Charles S. Cockell - Astrobiology
Здесь есть возможность читать онлайн «Charles S. Cockell - Astrobiology» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Astrobiology
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Astrobiology: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Astrobiology»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
offers an introductory text that explores the structure of living things, the formation of the elements required for life in the Universe, the biological and geological history of the Earth, and the habitability of other planets. Written by a noted expert on the topic, the book examines many of the major conceptual foundations in astrobiology, which cover a diversity of traditional fields including chemistry, biology, geosciences, physics, and astronomy.
The book explores many profound questions such as: How did life originate on Earth? How has life persisted on Earth for over three billion years? Is there life elsewhere in the Universe? What is the future of life on Earth?
is centered on investigating the past and future of life on Earth by looking beyond Earth to get the answers. Astrobiology links the diverse scientific fields needed to understand life on our own planet and, potentially, life beyond. This new second edition:
Expands on information about the nature of astrobiology and why it is useful Contains a new chapter “What is Life?” that explores the history of attempts to understand life Contains 20% more material on the astrobiology of Mars, icy moons, the structure of life, and the habitability of planets New ‘Discussion Boxes’ to stimulate debate and thought about key questions in astrobiology New review and reflection questions for each chapter to aid learning New boxes describing the careers of astrobiologists and how they got into the subject Offers revised and updated information throughout to reflect the latest advances in the field Written for students of life sciences, physics, astronomy and related disciplines, the updated edition of
is an essential introductory text that includes recent advances to this dynamic field.
Astrobiology — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Astrobiology», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Let's go through this process in a simplified way and consider what is happening. You can follow this text and cross-refer to Figure 5.10. We have an mRNA strand, just transcribed from DNA. Around this strand the ribosome forms, made up of subunits which provide the assembly point around which protein synthesis occurs. The ribosome is an impressive structure. In bacteria, it is made up of a large subunit of RNA, consisting of two folded strands of RNA and no fewer than 31 specialized proteins. There is also a small subunit, made up of one folded piece of RNA, called the 16S rRNA, together with another 21 proteins. Remember the 16S rRNA, as it will become important in Chapter 8when we explore the diversity of life on Earth. This whole apparatus is now ready to make protein.
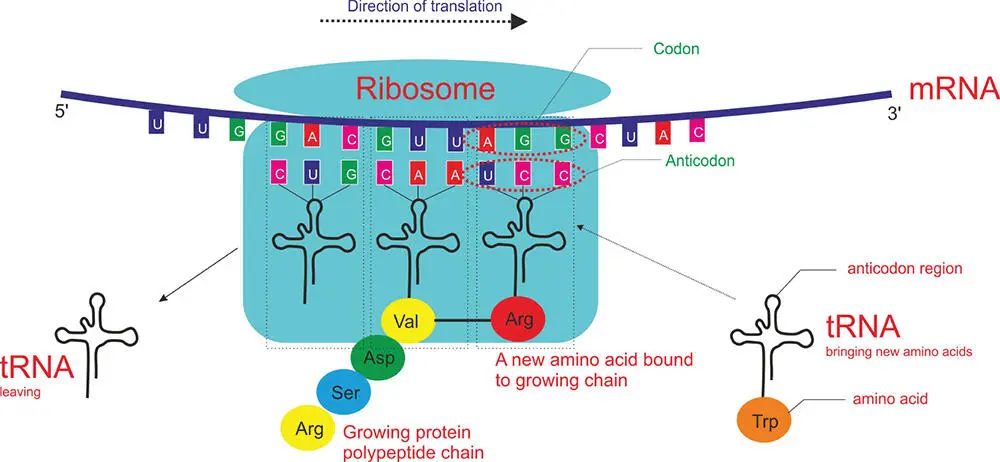
Figure 5.10 The translation of the genetic code. The protein synthesis apparatus around the mRNA.
The ribosome provides a protected environment in which the tRNA can bind. The tRNA has an amino acid at one end, and each amino acid has its own tRNA molecule associated with it. At the other end is an anticodon. The anticodon is a three-letter sequence of bases that matches three bases on the mRNA molecule (called the codon). Thus, each codon or triplet code on the mRNA corresponds to a specific amino acid (Figure 5.11).
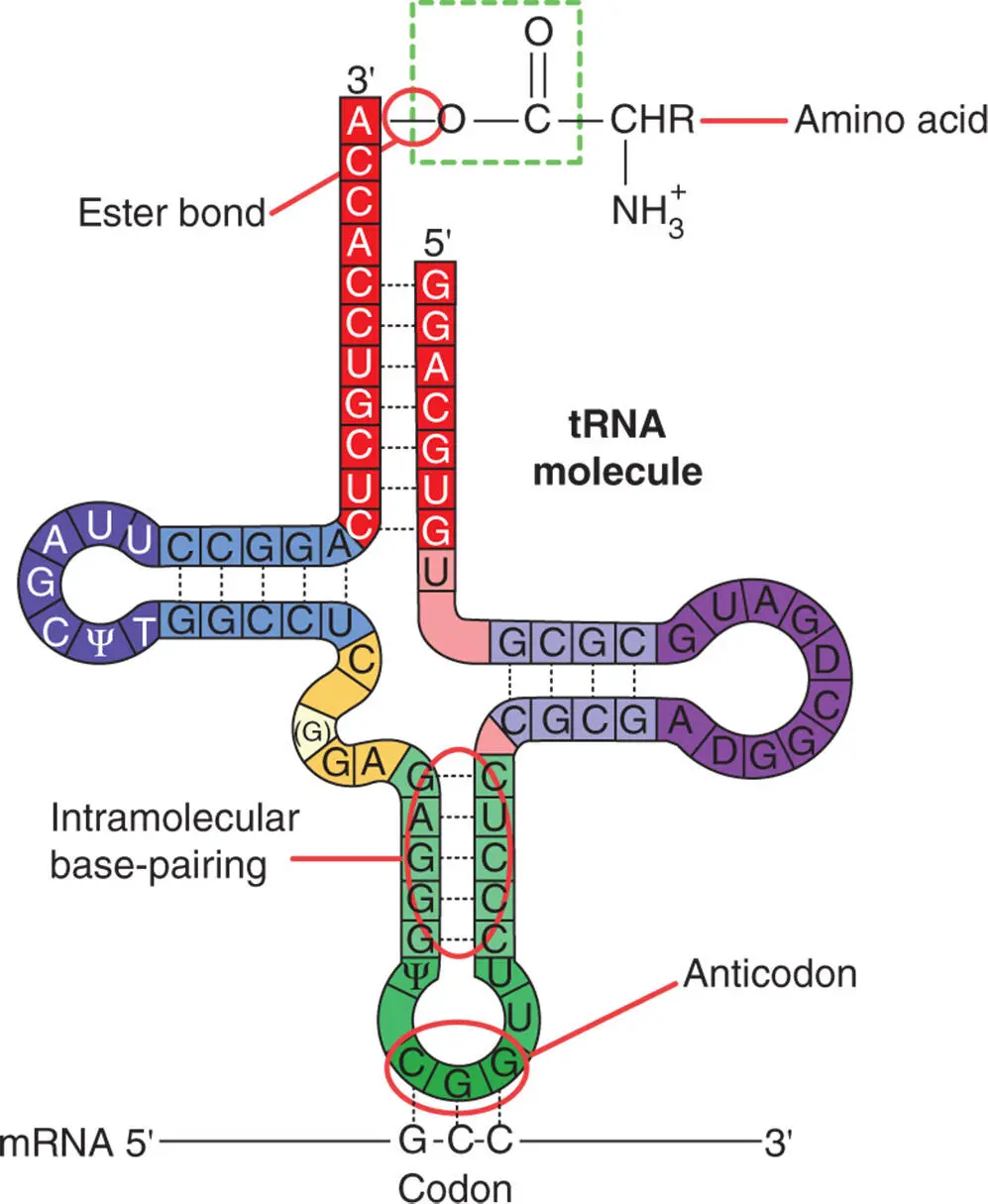
Figure 5.11 The structure of t-RNA. The amino acid is attached at the top of the molecule. The diagram also illustrates the codon-anticodon binding occurring at the bottom of the molecule.
Source: Reproduced with permission of John Wiley & Sons, Ltd.
If we think about this quantitatively, we can immediately see that each codon can code for 64 combinations. There are three positions in each codon, and we already know that at each of these positions there are four possible bases: G, C, A, and U. This gives us 4 × 4 × 4 = 64 possible combinations for each three-letter codon. But we already saw in the previous chapter that there are generally only 20 amino acids used by life. As a result, there is redundancy. Each amino acid can be coded for by more than one codon. We call this the “degeneracy of the genetic code.” Figure 5.12 shows the mRNA codons and their corresponding amino acids. If you look at this table, you can see that each amino acid generally has more than one codon. Apart from the amino acid tryptophan (which just has one codon), all other amino acids have at least two, and many of them have four codons.
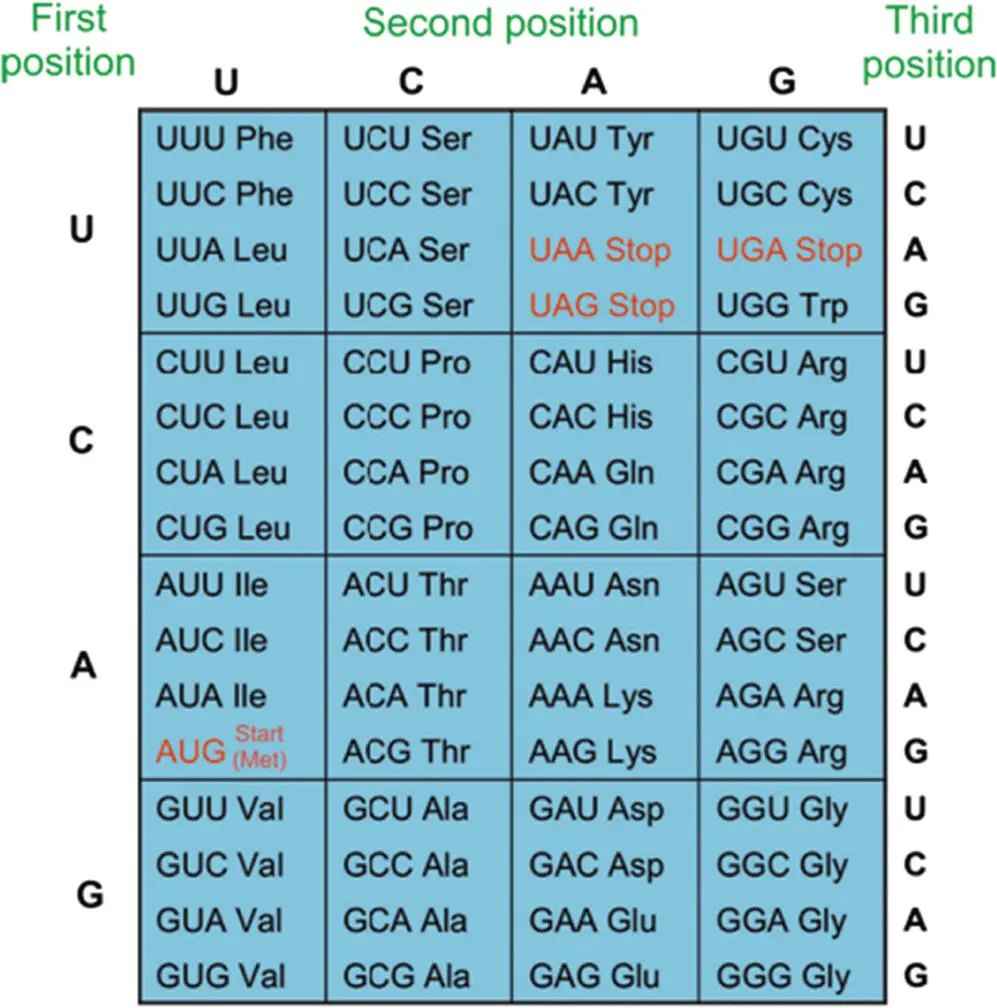
Figure 5.12 The table of codons of mRNA corresponding to amino acids. The amino acids are shown with their three-letter designation (see Appendix A6). Note the degeneracy of the code. Apart from small variations in different species, this table is universal across life, one line of evidence that all known life on Earth derives from a common origin.
Discussion Point: Why Is There Degeneracy in the Genetic Code?
The degeneracy of the genetic code ( genetic degeneracy) results from a simple consideration of the mathematics of the genetic code. As the code uses base pairs, which allow the DNA molecule to be opened down the middle and two identical helices to be synthesized, it necessarily has an even number of bases. Consider a genetic code with only two bases. If it had a codon with three positions, like our own code, it would produce 2 × 2 × 2 = 8 possible amino acids. This is not enough to code for the 20 amino acids required by the life that we know. The only way such a two-base genetics could produce enough codes to have 20 amino acids would be to have five positions on a codon to produce: 2 × 2 × 2 × 2 × 2 = 32 codes, leaving a degeneracy of 10 (assuming that we use one codon as a Start and one as a Stop codon). You can also consider a code with six bases instead of four. If it had only two bases in a codon, it would give 6 × 6 = 36 codes, which is enough to code for the amino acids known in life, with 16 places left over for redundancy. The main point to realize here is that in whatever way we make the genetic code, we end up with either too few codes, or some left over, in other words degeneracy. Another interesting consideration is that a code with only two bases would have a very limited repertoire of coding. The DNA molecule might have to be longer, or there would need to be more of it, to code for the same information in terrestrial life. A greater number of bases than our four bases (such as six or eight) leads to other potential problems, such as a greater frequency in mismatches between bases. It may not be chance that our code has four bases – perhaps it represents a process of biochemical optimization. What do you think?
Some codons code for the instruction to Stop reading and one of them (AUG – a methionine) to Start reading the mRNA strand.
Each amino acid brought to the mRNA in this way forms a peptide bond with the existing chain, and so as new tRNAs bind to the mRNA, a polypeptide or protein is synthesized, with the ribosome continuing to move along the mRNA strand. Thus, the mRNA sequence has been translated into the primary protein sequence. This primary sequence folds together to make the three-dimensional structure of a useful functioning protein.
The sequence of bases that codes for a single protein is called a gene, and we call the entire complement of genes within an organism its genome. The genome size varies enormously between organisms. The human genome contains about 3240 million bases (megabases or Mb; sometimes also written as megabase pairs or Mbp) of DNA, bacteria have up to about 13 Mb of DNA depending on the species, and they typically have about 4000 genes. The smallest genome of a free-living self-replicating organism belongs to Carsonella ruddii , which lives within the psyllids, a family of sap-feeding insects. It has a genome of just 160 000 bases (kilobases or kb or kbp) of DNA and 182 protein-coding genes. The smallest flu virus (which cannot replicate on its own) has only 11 genes. Although genome size is very loosely linked to complexity (bacteria tend to have smaller genomes than animals), this relationship is by no means reliable. Some protozoa(single-celled eukaryotes) have larger genomes than humans. This great difference between the genome sizes of organisms is called the C-value paradox. The “C” refers the quantity of DNA in the genome, which early researchers thought must be related to complexity.
Some of the DNA in an organism is referred to as non-coding DNA, as it has no known translation into protein. The amount of this non-coding DNA varies between species. In bacteria, it can be around 2%, and in humans it is 98.5%. Sometimes called junk DNA, this is a misnomer, since it is becoming increasingly understood that a proportion of this DNA has biochemical functions, for example producing RNA molecules including ribosomes, or encoding viral DNA. Some of the sequences are pseudogenes. These are sequences that code for proteins that are not produced by the cell or are replicas of other genes that are not functional. Much of the so-called C-value paradox is explained by non-coding DNA.
The process of reading DNA to RNA to protein is sometimes called the “central dogma of molecular biology” (Figure 5.13). The word “dogma” is always a troubling word in science, but the overall scheme broadly shows the two fundamental steps of reading the genetic code. The word dogma was used to capture the observation that once genetic information is turned into protein, it cannot go in the reverse direction. The information in protein is not transferred back into nucleic acid in any known life.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Astrobiology»
Представляем Вашему вниманию похожие книги на «Astrobiology» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Astrobiology» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.