Samprit Chatterjee - Handbook of Regression Analysis With Applications in R
Здесь есть возможность читать онлайн «Samprit Chatterjee - Handbook of Regression Analysis With Applications in R» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Handbook of Regression Analysis With Applications in R
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Handbook of Regression Analysis With Applications in R: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Handbook of Regression Analysis With Applications in R»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
andbook and reference guide for students and practitioners of statistical regression-based analyses in R
Handbook of Regression Analysis
with Applications in R, Second Edition
The book further pays particular attention to methods that have become prominent in the last few decades as increasingly large data sets have made new techniques and applications possible. These include:
Regularization methods Smoothing methods Tree-based methods In the new edition of the
, the data analyst’s toolkit is explored and expanded. Examples are drawn from a wide variety of real-life applications and data sets. All the utilized R code and data are available via an author-maintained website.
Of interest to undergraduate and graduate students taking courses in statistics and regression, the
will also be invaluable to practicing data scientists and statisticians.
Handbook of Regression Analysis With Applications in R — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Handbook of Regression Analysis With Applications in R», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Figure 1.2gives a graphical representation of least squares that is based on Figure 1.1. Now the true regression line is represented by the gray line, and the solid black line is the estimated regression line, designed to estimate the (unknown) gray line as closely as possible. For any choice of estimated parameters 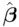 , the estimated expected response value given the observed predictor values equals
, the estimated expected response value given the observed predictor values equals
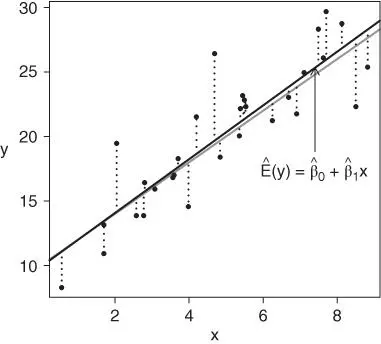
FIGURE 1.2: Least squares estimation for the simple linear regression model, using the same data as in Figure 1.1. The gray line corresponds to the true regression line, the solid black line corresponds to the fitted least squares line (designed to estimate the gray line), and the lengths of the dotted lines correspond to the residuals. The sum of squared values of the lengths of the dotted lines is minimized by the solid black line.
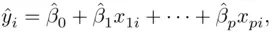
and is called the fitted value. The difference between the observed value 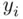 and the fitted value
and the fitted value 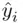 is called the residual, the set of which is represented by the signed lengths of the dotted lines in Figure 1.2. The least squares regression line minimizes the sum of squares of the lengths of the dotted lines; that is, the ordinary least squares (OLS) estimates minimize the sum of squares of the residuals.
is called the residual, the set of which is represented by the signed lengths of the dotted lines in Figure 1.2. The least squares regression line minimizes the sum of squares of the lengths of the dotted lines; that is, the ordinary least squares (OLS) estimates minimize the sum of squares of the residuals.
In higher dimensions ( 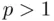 ), the true and estimated regression relationships correspond to planes (
), the true and estimated regression relationships correspond to planes ( 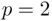 ) or hyperplanes (
) or hyperplanes ( 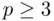 ), but otherwise the principles are the same. Figure 1.3illustrates the case with two predictors. The length of each vertical line corresponds to a residual (solid lines refer to positive residuals, while dashed lines refer to negative residuals), and the (least squares) plane that goes through the observations is chosen to minimize the sum of squares of the residuals.
), but otherwise the principles are the same. Figure 1.3illustrates the case with two predictors. The length of each vertical line corresponds to a residual (solid lines refer to positive residuals, while dashed lines refer to negative residuals), and the (least squares) plane that goes through the observations is chosen to minimize the sum of squares of the residuals.
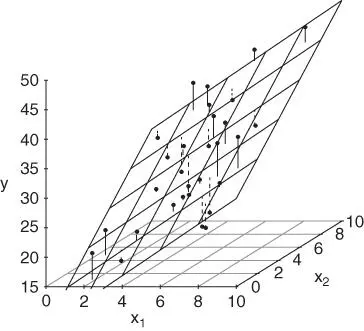
FIGURE 1.3: Least squares estimation for the multiple linear regression model with two predictors. The plane corresponds to the fitted least squares relationship, and the lengths of the vertical lines correspond to the residuals. The sum of squared values of the lengths of the vertical lines is minimized by the plane.
The linear regression model can be written compactly using matrix notation. Define the following matrix and vectors as follows:
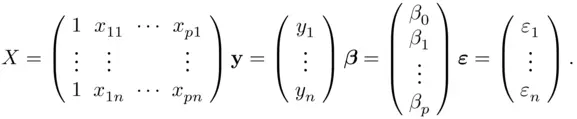
The regression model (1.1)is then
(1.3) 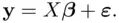
The normal equations [which determine the minimizer of 1.2] can be shown (using multivariate calculus) to be
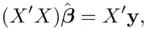
which implies that the least squares estimates satisfy
(1.4) 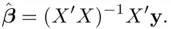
The fitted values are then
(1.5) 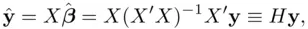
where 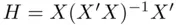 is the so‐called “hat” matrix (since it takes
is the so‐called “hat” matrix (since it takes 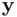 to
to 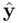 ). The residuals
). The residuals 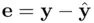 thus satisfy
thus satisfy
(1.6) 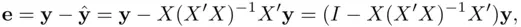
or
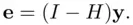
1.2.3 ASSUMPTIONS
The least squares criterion will not necessarily yield sensible results unless certain assumptions hold. One is given in (1.1)— the linear model should be appropriate. In addition, the following assumptions are needed to justify using least squares regression.
1 The expected value of the errors is zero ( for all ). That is, it cannot be true that for certain observations the model is systematically too low, while for others it is systematically too high. A violation of this assumption will lead to difficulties in estimating . More importantly, this reflects that the model does not include a necessary systematic component, which has instead been absorbed into the error terms.
2 The variance of the errors is constant ( for all ). That is, it cannot be true that the strength of the model is greater for some parts of the population (smaller ) and less for other parts (larger ). This assumption of constant variance is called homoscedasticity, and its violation (nonconstant variance) is called heteroscedasticity. A violation of this assumption means that the least squares estimates are not as efficient as they could be in estimating the true parameters, and better estimates are available. More importantly, it also results in poorly calibrated confidence and (especially) prediction intervals.
3 The errors are uncorrelated with each other. That is, it cannot be true that knowing that the model underpredicts (for example) for one particular observation says anything at all about what it does for any other observation. This violation most often occurs in data that are ordered in time (time series data), where errors that are near each other in time are often similar to each other (such time‐related correlation is called autocorrelation). Violation of this assumption means that the least squares estimates are not as efficient as they could be in estimating the true parameters, and more importantly, its presence can lead to very misleading assessments of the strength of the regression.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Handbook of Regression Analysis With Applications in R»
Представляем Вашему вниманию похожие книги на «Handbook of Regression Analysis With Applications in R» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Handbook of Regression Analysis With Applications in R» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.