Raquel Bernal - Guía práctica para la evaluación de impacto
Здесь есть возможность читать онлайн «Raquel Bernal - Guía práctica para la evaluación de impacto» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Guía práctica para la evaluación de impacto
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Guía práctica para la evaluación de impacto: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Guía práctica para la evaluación de impacto»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Guía práctica para la evaluación de impacto — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Guía práctica para la evaluación de impacto», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Por ejemplo, suponga un programa para los adultos mayores de grupos vulnerables (económica y socialmente). El programa consiste en la provisión de una suma de dinero mensual que corresponde a un determinado número de salarios mínimos diarios. En los objetivos y lineamientos se establece que el programa está diseñado para proteger a las personas de la tercera edad contra el riesgo económico de la imposibilidad de generar ingresos, disminuir la vulnerabilidad de los adultos mayores de bajos recursos y propiciar su inserción en la comunidad. En este caso, ¿cuál sería la variable de resultado Y ideal si le pidieran evaluar este programa? No es tan sencillo. En principio, podría ser un indicador de salud y nutrición, puesto que el adulto mayor podría estar mejorando su estado nutricional como resultado del aumento en el ingreso del hogar asociado a la participación en el programa. Sin embargo, el adulto mayor podría estar gastando el dinero en cosas diferentes a alimentos, medicamentos u otros elementos asociados con un mejor estado de salud o nutrición, por lo cual la evaluación podría generar una conclusión muy negativa acerca del programa.
Por otra parte, la variable de resultado Y podría ser más bien una medición del estado de ánimo del beneficiario. Si los adultos mayores se sienten olvidados, viven solos en su gran mayoría, tienen estado de salud deficiente, etc., entonces el hecho de que les ofrezcan el programa les puede dar una esperanza, y el impacto podría verse más bien reflejado en un mejor estado de ánimo. Resulta que no es tan sencillo diseñar instrumentos que midan adecuadamente el estado de ánimo de los individuos o el nivel de inserción del individuo en su comunidad. Como se puede apreciar, encontrar una variable de resultado adecuada en este caso es todo un reto para el evaluador. Note, sin embargo, que en principio éste es el resultado de una política cuyo diseño es demasiado general y, por tanto, evaluar los logros de tales intervenciones es generalmente muy difícil. En suma, el evaluador debe tratar de relacionar, de la mejor manera posible, los objetivos , lineamientos y forma de operación del programa, con variables de resultado que se espera que puedan medir de manera relativamente razonable el desempeño del programa.
Bibliografía
Blundell, R. y M. Costa Dias, 2009, “Alternative Approaches to Evaluation in Empirical Microeconomics,” Journal of Human Resources , University of Wisconsin Press, vol. 44(3), 565-540.
Caliendo, M. y S. Kopeinig, 2005, “Some Practical Guidance for the Implementation of Propensity Score Matching”, IZA Discussion Paper Series, No. 1588.
Heckman, J., R. LaLonde y J. Smith, 1999, “The Economics and Econometrics of Active Labor Market Programs,” en O. Ashenfelter y D. Card, capítulo 31, Handbook of Labor Economics , vol. IV, 1865-2073.
Smith, J., 2000, “A Critical survey of Empirical Methods for Evaluating Active Labor Market Policies”, Schweizerische Zeitschrift fr Volkswirthschaft und Statistik , 136(6), 1-22.
Roy, A., 1951, “Some Thoughts on the Distribution of Earnings”, Oxford Economic Papers , 3, 135-145.
Rubin, D., 1974, “Estimating Causal Effects to Treatments in Randomised and Nonradomised Studies”, Journal of Educational Psychology , 66, 688-701.
7Este punto se discute en detalle más adelante en la sección 4.5.
8 Average Treatment Effect.
9 Average Treatment on the Treated.
10 Average Treatment on the Untreated.
11Con excepción de casos en los cuales el tratamiento se haya aplicado de manera aleatoria en la población (ver capítulo 4).
12Note que para estimar  ATE existe un reto adicional, dado que se requiere de la construcción de los dos resultados contrafactuales (y no sólo uno), E [ Y i(1)| D i= 0] y E [ Y i(0)| D i= 1].
ATE existe un reto adicional, dado que se requiere de la construcción de los dos resultados contrafactuales (y no sólo uno), E [ Y i(1)| D i= 0] y E [ Y i(0)| D i= 1].
13Las variables binarias también se conocen en la literatura como variables dummy , dicótomas o dicotómicas.
14Ver anexo 1.
15Ver anexo 2.
16Ver anexo 3.
17Sistema de Identificación de Potenciales Beneficiarios de Programas Sociales. Es un instrumento desarrollado con el objetivo de focalizar los programas de política pública hacia la población más vulnerable en Colombia. El puntaje Sisbén se construye con base en una encuesta que indaga sobre las características sociodemográficas del hogar, toma valores entre 0 y 100, donde puntajes más bajos indican mayores niveles de pobreza del hogar.
3
SESGO DE SELECCIÓN
Como se detalló en el capítulo anterior, la evaluación de impacto consiste en la estimación de:

donde E [ Y i(1)| D i= 1] es el valor esperado de la variable de resultado entre los participantes en el programa en presencia del programa y E [ Y i(0)| D i= 1], o resultado contrafactual, es el valor esperado de la variable de resultado entre los participantes en ausencia del programa. En otras palabras, evaluar la diferencia entre la variable de resultado entre el grupo de tratados si existe el programa y la variable de resultado entre el grupo de tratados si no se hubiera implementado el programa. Claramente no es posible observar ambos resultados al mismo tiempo. Sin embargo, sí se puede observar la variable de resultado entre un grupo de individuos elegibles que no participan en el programa (o grupo de control), E [ Y i(0)| D i= 0].
El principal reto de la evaluación de impacto es determinar las condiciones bajo las cuales E [ Y i(0)| D i= 0] se puede utilizar como una aproximación válida de E [ Y i(0)| D i= 1] y, por tanto, utilizarse en la ecuación (3.1) para obtener el efecto del programa ATT .
Evidentemente E [ Y i(0)| D i= 0] se podría utilizar como una aproximación adecuada del contrafactual si
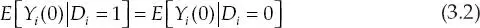
Es decir, si la variable de resultado en ausencia del programa es idéntica para el grupo de individuos tratados ( D = 1) que para el grupo de individuos de control ( D = 0).
El supuesto (3.2) se viola toda vez que la participación en el programa es una elección del individuo elegible. La razón es que los participantes y los no participantes generalmente son diferentes, aun en ausencia del programa, y por tal motivo es precisamente que se observa que unos escogen participar y otros no, aun si todos son elegibles para recibir el tratamiento. Es decir, existen características (observadas y/o no observadas) que causan que unos individuos participen y otros no. Probablemente, las diferencias en estas características entre individuos participantes e individuos no participantes también originen diferencias en la variable de resultado entre un grupo y el otro. Por ende, es muy probable que la variable de resultado del grupo de tratamiento y la variable de resultado del grupo de control sean diferentes, aun si el programa no existiera . Este hecho se conoce como sesgo de selección.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Guía práctica para la evaluación de impacto»
Представляем Вашему вниманию похожие книги на «Guía práctica para la evaluación de impacto» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Guía práctica para la evaluación de impacto» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.