Liliana Andrade - Multi-Processor System-on-Chip 1
Здесь есть возможность читать онлайн «Liliana Andrade - Multi-Processor System-on-Chip 1» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Multi-Processor System-on-Chip 1
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Multi-Processor System-on-Chip 1: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Multi-Processor System-on-Chip 1»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Multi-Processor System-on-Chip 1 — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Multi-Processor System-on-Chip 1», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:

Figure 2.17. KaNN augmented computation graph
2.4.3. High-integrity computing
High-integrity computing on the MPPA3 processor refers to applications that execute in a physically isolated domain of the processor, whose functions are developed under model-based design and must meet hard real-time constraints. The Research Open-Source Avionics and Control Engineering (ROSACE) case study introduced the model-based design of avionics applications that targeted multi-core platforms (Pagetti et al . 2014). The model-based design for the MPPA processor focuses on mono-periodic and multi-periodic harmonic applications (Figure 2.18) that are described using the Lustre (Halbwachs et al . 1991) or the SCADE Suite 5 synchronous dataflow languages (Graillat et al . 2018, 2019). The execution environment is composed of one or more clusters configured for asymmetric multi-processing ( section 2.3.2), where each core is logically associated with one SMEM bank, and where tasks run to completion.
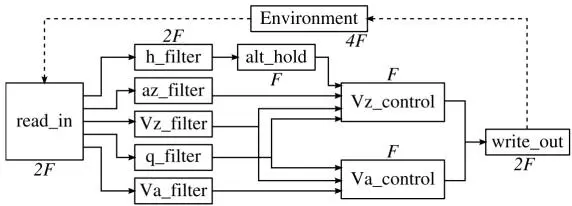
Figure 2.18. ROSACE harmonic multi-periodic case study (Graillat et al. 2018)
The code generation workflow assumes that some nodes of the synchronous dataflow program are identified by the programmer as concurrent tasks, and defines the implicit top-level “root” task. A Lustre or SCADE Suite high-level compiler generates C-code for this set of tasks, communicating and synchronizing through one-to-one channels. Channels correspond to single-producer, single-consumer FIFOs of depth one, whose implementation is abstracted form the task C-code under SEND and RECV macros. The rest of the code generation workflow involves:
– providing workers, each able to execute a set of tasks sequentially;
– scheduling and mapping the set of tasks on the workers;
– implementing the communication channels and their SEND/RECV methods;
– compiling C-code with the CompCert formally verified compiler.
In the MPPA workflow, the workers are the PEs associated with a memory bank.
Timing verification follows the principles of the multi-core response time analysis (MRTA) framework (Davis et al . 2018). Starting from the task graph, its mapping to PEs, and given the worst-case execution time (WCET) of each task in isolation, the multi-core inference analysis (MIA) tool (Rihani et al . 2016; Dupont de Dinechin et al . 2020) refines the execution intervals of each task while updating its WCET for interference on the shared resources. The MIA tool relies on the property that the PEs, the memory hierarchy and the interconnects are timing-compositional. The refined release dates are used to activate a fast hardware release mechanism for each task. A task then executes when its input channels are data-ready (Figure 2.19).
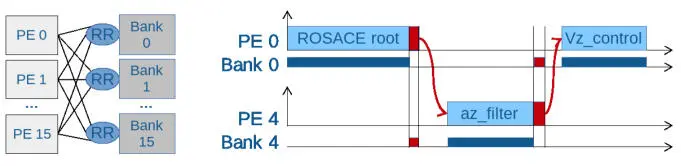
Figure 2.19. MCG code generation of the MPPA processor
2.5. Conclusion
We introduced the third-generation MPPA processor, which implements a many-core architecture that targets intelligent systems, defined as cyber-physical systems enhanced with high-performance machine learning capabilities and strong cyber-security support. As with the GPGPU architecture, the MPPA3 architecture is composed of a number of multi-core compute units that share the processor external memory and I/O through on-chip global interconnects. However, the MPPA architecture is able to host standard software, offers excellent time predictability and provides strong partitioning capabilities. This enables us to consolidate, on a single or dual processor platform, the high-performance machine learning and computer vision functions implied by vehicle perception, the high-integrity functions developed through model-based design, and the cyber-security functions required by secured communications.
2.6. References
Bodin, B., Munier-Kordon, A., and Dupont de Dinechin, B. (2013). Periodic schedules for cyclo-static dataflow. The 11th IEEE Symposium on Embedded Systems for Real-time Multimedia , Montreal, QC, Canada, 105–114.
Bodin, B., Munier-Kordon, A., and Dupont de Dinechin, B. (2016). Optimal and fast throughput evaluation of CSDF. Proceedings of the 53rd Annual Design Automation Conference . Austin, USA, 160:1–160:6.
Brunie, N. (2017). Modified fused multiply and add for exact low precision product accumulation. 24th IEEE Symposium on Computer Arithmetic . London, United Kingdom, 106–113.
Carmichael, Z., Langroudi, H.F., Khazanov, C., Lillie, J., Gustafson, J.L., and Kudithipudi, D. (2019). Performance-efficiency trade-off of low-precision numerical formats in deep neural networks. Proceedings of the Conference for Next Generation Arithmetic . New York, USA, 3:1–3:9.
CAST (2016). Multi-core Processors, Technical Report CAST-32A, FAA [Online]. Available: https://www.faa.gov/aircraft/air_cert/design_approvals/air_software/cast/cast_papers/.
Cavicchioli, R., Capodieci, N., Solieri, M., and Bertogna, M. (2019). Novel methodologies for predictable CPU-To-GPU command offloading. Proceedings of the 31st Euromicro Conference on Real-Time Systems . Stuttgart, Germany, vol. 133 of LIPIcs , 22:1–22:22.
Chung, E., Fowers, J., Ovtcharov, K., Papamichael, M., Caulfield, A., Massengill, T., Liu, M., Ghandi, M., Lo, D., Reinhardt, S., Alkalay, S., Angepat, H., Chiou, D., Forin, A., Burger, D., Woods, L., Weisz, G., Haselman, M., and Zhang, D. (2018). Serving DNNs in real time at datacenter scale with project brainwave. IEEE Micro , 38, 8–20.
CNX (2019). Autoware.AI-Software-Architecture [Online]. Available: https://www.cnx-software.com/wp-content/uploads/2019/02/Autoware.AI-Software-Architecture.png.
Davis, R.I., Altmeyer, S., Indrusiak, L.S., Maiza, C., Nélis, V., and Reineke, J. (2018). An extensible framework for multicore response time analysis. Real-Time Systems , 54(3), 607–661.
de Dinechin, F., Forget, L., Muller, J.-M., and Uguen, Y. (2019). Posits: The good, the bad and the ugly. Proceedings of the Conference for Next Generation Arithmetic . Association for Computing Machinery, New York, USA.
Dupont de Dinechin, B. (2004). From machine scheduling to VLIW instruction scheduling. ST Journal of Research , 1(2).
Dupont de Dinechin, B. (2014). Using the SSA-Form in a code generator. 23rd International Conference on Compiler Construction , vol. 8409 of Lecture Notes in Computer Science , Springer, 1–17.
Dupont de Dinechin, B., and Graillat, A. (2017). Feed-forward routing for the wormhole switching network-on-chip of the kalray MPPA2 processor. Proceedings of the 10th International Workshop on Network on Chip Architectures . Cambridge, USA, 10:1–10:6.
Dupont de Dinechin, B., de Ferrière, F., Guillon, C., and Stoutchinin, A. (2000). Code generator optimizations for the ST120 DSP-MCU core. Proceedings of the 2000 International Conference on Compilers, Architectures and Synthesis for Embedded Systems, CASES , San Jose, USA, 93–102.
Dupont de Dinechin, B., Ayrignac, R., Beaucamps, P., Couvert, P., Ganne, B., de Massas, P. G., Jacquet, F., Jones, S., Chaisemartin, N. M., Riss, F., and Strudel, T. (2013). A clustered manycore processor architecture for embedded and accelerated applications. IEEE High Performance Extreme Computing Conference , Waltham, USA, 1–6.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Multi-Processor System-on-Chip 1»
Представляем Вашему вниманию похожие книги на «Multi-Processor System-on-Chip 1» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Multi-Processor System-on-Chip 1» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.