Liliana Andrade - Multi-Processor System-on-Chip 1
Здесь есть возможность читать онлайн «Liliana Andrade - Multi-Processor System-on-Chip 1» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Multi-Processor System-on-Chip 1
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Multi-Processor System-on-Chip 1: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Multi-Processor System-on-Chip 1»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Multi-Processor System-on-Chip 1 — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Multi-Processor System-on-Chip 1», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
– an OpenCL device is an offloading target where computations are sent using a command queue;
– an OpenCL device has a global memory allocated and managed by the host application, and shared by the multiple compute units of the OpenCL device;
– an OpenCL compute unit comprises several processing elements (PEs) that share the compute unit local memory;
– each OpenCL PE also has a private memory, and shared access to the device’s global memory without cache coherence across compute units.
The OpenCL sub-devices are defined as non-intersecting sets of compute units inside a device, which have dedicated command queues while sharing the global memory.
On the MPPA3 processor, high-performance computing functions are dispatched to partitions composed of one or more compute clusters, each of which is exposed as an OpenCL sub-device. In the port of the PoCL environment, support for OpenCL sub-devices has been developed, while two offloading modes are provided:
LWI(Linearized Work Items): all the work items of a work group are executed within a loop on a single PE. This is the default execution mode of PoCL;
SPMD(Single Program Multiple Data): the work items of a work group are executed concurrently on the PEs of a compute cluster, with the _ _localOpenCL memory space shared by the PEs and located into the SMEM (Figure 2.14).
These mappings of the abstract OpenCL machine elements onto the MPPA3 architecture components are presented in Table 2.4. Although the LWI mode appears better suited to the OpenCL-C kernel code written for GPGPU processors, the SPMD mode is preferred for optimizing performance, as it allows the configuration of most of the compute cluster SMEM as OpenCL local memory shared by the work group.
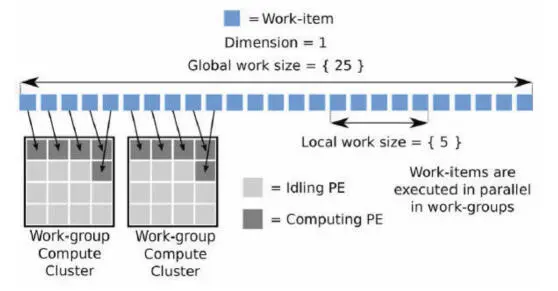
Figure 2.14. OpenCL NDRange execution using the SPMD mode
| OpenCL | Device | Global memory | Sub-device | Compute unit |
| MPPA3 | MPPA processor or | External DDR | Group of | Compute cluster (SPMD) |
| Component | MPPA domain | memory | compute cluster(s) | Processing element (LWI) |
Table 2.4. OpenCL machine elements and MPPA architecture components
Most often, there is a need to port C/C++ code and to access the high-performance features implemented in the GCC compiler for the Kalray VLIW core. Among these, the C named address space extension defined by ISO/IEC TR 18037:2008 is used to annotate objects and addresses that are accessed using non-temporal (L1D cache bypass) and/or non-trapping loads. In order to call the code compiled by GCC and the MPPA communication libraries (Hascoët et al . 2017) from OpenCL-C kernels, the LLVM OpenCL-C compiler and PoCL have been extended to understand function declarations annotated with _ _attribute_ _ ((mppa_native)). Whenever such reference is seen in OpenCL-C source code, the PoCL linking stages assumes that the symbol is resolved, and the MPPA3 compute cluster run-time environment dynamically loads and links the native function, before starting the execution of the kernel.
This native function extension also enables kernels to access other services such as a lightweight lock-free POSIX multi-threading environment, fast inter-PE hardware synchronizations, dynamic local memory allocation and remoting of system calls to the host OS, including FILE I/O.
2.4.2. KaNN code generator
The KaNN (Kalray Neural Network) code generator is a deep learning inference compiler targeting the MPPA3 platform. It takes as input a trained neural network model, described within a standard framework such as Caffe, TensorFlow or ONNX, and produces executable code for a set of compute clusters exposed as an OpenCL sub-device (Figure 2.15). Targeting OpenCL sub-devices allows several model inferences to execute concurrently on a single MPPA3 processor. The KaNN code generator optimizes for batch-1 inference, with the primary objective of reducing latency. At the user’s option, FP32 operators in the original network can be converted to FP16 operators. Integer quantization, such as the one used by TensorFlow Lite, is also supported; however, it must be expressed in the input model. Indeed, such models are assumed to be trained with fake quantization (Jacob et al . 2018), which must match the actual quantization applied during inference.
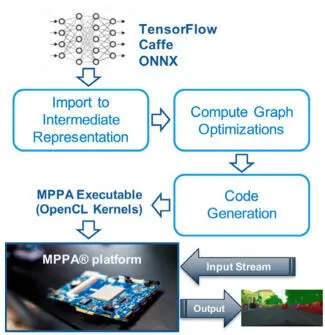
Figure 2.15. KaNN inference code generator workflow
Following the import of the input model into an intermediate representation, optimizations are applied to the compute graph:
– elimination of channel concatenation and slicing copies;
– padding of input activations of convolutional layers;
– folding of batch normalizations, scalings, additions, into a single pointwise fused multiply-add operator;
– fusion of convolutions with ReLU activation functions;
– adaptation of arithmetic representations.
The KaNN code generation scheme performs inference in topological sort order of the (optimized) compute graph, parallelizing the execution of each operator over all the compute clusters of the target sub-device. When executing an operator, its input and output activations are distributed across the target local memories configured as SPM, while the network parameters are read from the (external) DDR memory. Depending on the type of operator (convolutional or fully connected), the spatial dimension sizes and the channel depth, input and output activations are distributed over the compute cluster local memories by splitting either along the spatial dimensions or along the channel dimension (Figure 2.16):
– In case of spatial splitting of the output activations, each compute cluster only accesses an input activation tile and its shadow region, while all the operator parameters are required; these are read once from the DDR memory and multicasted to all the target compute clusters.
– In case of channel splitting of the output activations, the full input layer must be replicated in the local memory of each compute cluster, but only the corresponding slice of parameters is read from the DDR memory.
In all cases, activations are computed once, laid out sequentially along the channel dimension and possibly copied to other local memories.
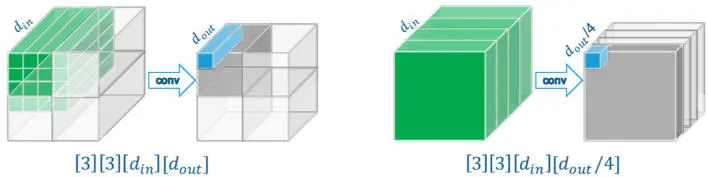
Figure 2.16. Activation splitting across MPPA3 compute clusters
For any compute cluster in the target sub-device, the code generation process defines and implements a local schedule for:
– local memory buffer allocations/deallocations;
– DDR memory read/multicast of parameters;
– execution of operator operations;
– inter-cluster activation exchanges;
– inter-cluster synchronizations.
This process is backed by the computation graph (Figure 2.17) augmented with parameter read tasks (yellow) and activation production tasks (blue).
The results of KaNN code generation is a collection of OpenCL binary kernels, where each kernel interprets the contents of a static data block composed of a sequence of records. Each record contains its length, a native compute function pointer and a structure containing arguments for the compute function. For each record, the OpenCL kernel calls the native compute function with the pointer to the structure. The kernel ends after the interpretation of the last record.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Multi-Processor System-on-Chip 1»
Представляем Вашему вниманию похожие книги на «Multi-Processor System-on-Chip 1» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Multi-Processor System-on-Chip 1» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.