Liliana Andrade - Multi-Processor System-on-Chip 1
Здесь есть возможность читать онлайн «Liliana Andrade - Multi-Processor System-on-Chip 1» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Multi-Processor System-on-Chip 1
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Multi-Processor System-on-Chip 1: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Multi-Processor System-on-Chip 1»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Multi-Processor System-on-Chip 1 — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Multi-Processor System-on-Chip 1», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
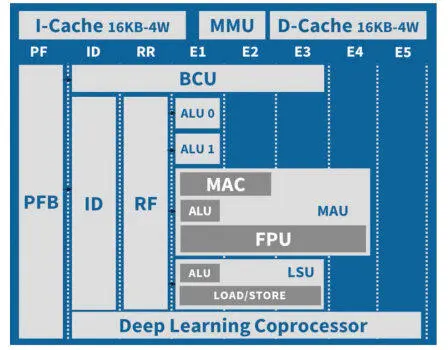
Figure 2.10. VLIW core instruction pipeline
Based on previous compiler design experience with different types of VLIW architectures (Dupont de Dinechin et al . 2000, 2004), a Fisher-style VLIW architecture has been selected, rather than an EPIC-style VLIW architecture (Table 2.3). The main features of the Kalray VLIW architecture are as follows: – Partial predication: fully predicated architectures are expensive with regard to instruction encoding, while control speculation of arithmetic instructions performs better than if-conversion when applicable. Moreover, conditional SELECT operations are equivalent to CMOV operations with operand renaming constraints (Dupont de Dinechin 2014). Then, if-conversion only needs to be supported by conditional load/store and CMOV instructions on scalar and vector operands.
Table 2.3. Types of VLIW architectures
| Classical VLIW architecture | EPIC VLIW architecture |
| SELECT operations on Boolean operand | Fully predicated ISA |
| Conditional load/store/floating-point operations | Advanced loads (data speculation) |
| Dismissible loads (control speculation) | Speculative loads (control speculation) |
| Clustered register files and function units | Polycyclic/multiconnect register files |
| Multi-way conditional branches | Rotating registers |
| Compiler techniques | |
| Trace scheduling | Modulo scheduling |
| Partial predication | Full predication |
| Main examples | |
| Multiflow TRACE processors | Cydrome Cydra-5 |
| HP Labs Lx / STMicroelectronics ST200 | HP-Intel IA64 |
| Philips TriMedia | Texas Instruments VelociTI |
– Dismissible loads: these instructions enable control speculation of load instructions by suppressing exceptions on address errors, and by ensuring that no side-effects occur in the I/O areas. Additional configuration in the MMU refine their behavior on protection and no-mapping exceptions.
– No rotating registers: rotating registers rename temporary variables defined inside software pipelines, whose schedule is built while ignoring register antidependences. However, rotating registers add significant ISA and implementation complexity, while temporary variable renaming can be done by the compiler.
– Widened memory access: widening the memory accesses on a single port is simpler to implement than multiple memory ports, especially when memory address translation is implied. This simplification enables, in turn, the support of misaligned memory accesses, which significantly improves compiler vectorization opportunities.
– Unification of the scalar and SIMD data paths around a main register file of 64×64-bit registers, for the same motivations as the POWER vector-scalar architecture (Gschwind 2016). Operands for the SIMD instructions map to register pairs (16 bytes) or to register quadruples (32 bytes).
2.3.4. Coprocessor
On the MPPA3 processor, each VLIW core is paired with a tightly coupled coprocessor for the mixed-precision matrix multiply-accumulate operations of deep learning operators (Figure 2.11). The coprocessor operates on a dedicated data path that includes a 48 × 256-bit register file. Within the six-issue VLIW core architecture, one issue lane is dedicated to the coprocessor arithmetic instructions, while the branch and control unit (BCU) may also execute data transfer operations between the coprocessor registers and the VLIW core general-purpose registers. Finally, the coprocessor leverages the 256-bit LSU of the VLIW core to transfer data blocks from/to the SMEM, at the rate of 32 bytes per clock cycle. It then uses these 32-byte data blocks as left and right operands of matrix multiply-accumulate operations.
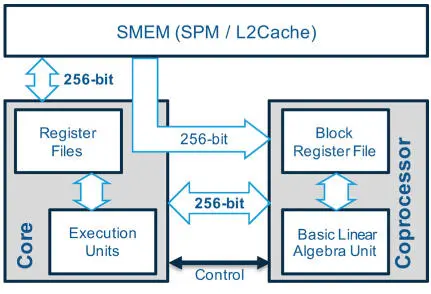
Figure 2.11. Tensor coprocessor data path
The coprocessor data path is designed by assuming that the activations and weights, respectively, have row-major and column-major layout in memory, in order to avoid the complexities of Morton memory indexing (Rovder et al . 2019). Due to the mixed-precision arithmetic, matrix operands may take one, two or four consecutive registers, with element sizes of one, two, four and eight bytes. In all cases, the coprocessor operations interpret matrix operands as having four rows and a variable number of columns, depending on the number of consecutive registers and the element size. In order to support this invariant, four 32-byte “load-scatter” instructions are provided to coprocessor registers. A load-scatter instruction loads 32 consecutive bytes from memory, interprets these as four 64-bit (8 bytes) blocks and writes each block into a specified quarter of each register that composes the destination operand (Figure 2.12). After executing the four load-scatter variants, a 4 × P submatrix of a matrix with row-major order in memory is loaded into a coprocessor register quadruple.
The coprocessor implements matrix multiply-accumulate operations on INT8.32, INT16.64 and FP16.32 arithmetic 1 . The coprocessor is able to multiply-accumulate 4 × 8 by 8 × 4 8-bit matrices into a 4 × 4 32-bit matrix (128 MAC operations per clock cycle), held in two consecutive registers (Figure 2.13). The 8 × 4 8-bit matrix operand is actually a 4 × 8 operand that is transposed at the input port of the multiply-accumulate operation. The coprocessor may also perform multiply-accumulate operations of two 4 × 4 16-bit matrices into a 4 × 4 64-bit matrix (64 MAC operations per clock cycle), held in four consecutive registers. Finally, the coprocessor supports multiply-accumulate of two 4 × 4 FP16 matrices into a 4 × 4 FP32 matrix, but performed by four successive operations 2 (16 FMA operations per clock cycle). The FP16.32 matrix operations actually compute exact four-deep dot products with accumulation, by applying Kulisch’s principles on an 80+ϵ accumulator (Brunie 2017).
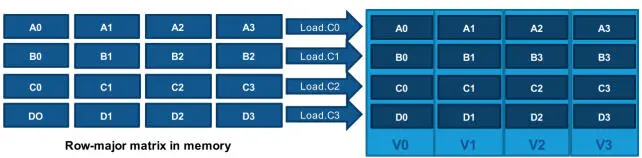
Figure 2.12. Load-scatter to a quadruple register operand
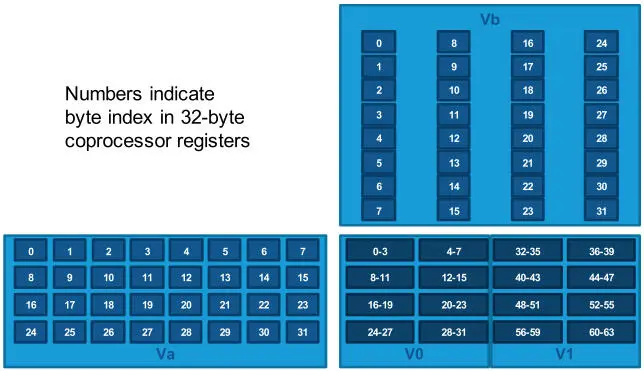
Figure 2.13. INT8.32 matrix multiply-accumulate operation
2.4. The MPPA3 software environments
2.4.1. High-performance computing
The programming environment used for high-performance computing on the MPPA3 processor is derived from the Portable Computing Language (PoCL) project 3 , which proposes an open-source implementation of the OpenCL 1.2 standard 4 with support for some of the OpenCL 2.0 features. The OpenCL-C kernels are compiled with LLVM, which has been retargeted for this purpose to the Kalray VLIW core. In OpenCL, a host application offloads computations to an abstract machine:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Multi-Processor System-on-Chip 1»
Представляем Вашему вниманию похожие книги на «Multi-Processor System-on-Chip 1» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Multi-Processor System-on-Chip 1» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.