Liliana Andrade - Multi-Processor System-on-Chip 1
Здесь есть возможность читать онлайн «Liliana Andrade - Multi-Processor System-on-Chip 1» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Multi-Processor System-on-Chip 1
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Multi-Processor System-on-Chip 1: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Multi-Processor System-on-Chip 1»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Multi-Processor System-on-Chip 1 — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Multi-Processor System-on-Chip 1», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The MPPA software development tools and run-time environments conform to CPU standards, particularly the availability of C/C++/OpenMP programming environments, supported by POSIX operating systems and RTOSes. As these standards target multi-core shared memory architectures, there is an opportunity for higher-level application code generators to automate code and data distribution across the multiple compute units and the local memories of a many-core processor. For the MPPA3 processor, this opportunity is realized in cases of deep learning model inference, as well as of model-based software development using synchronous-reactive languages.
2.1. Introduction
Cyber-physical systems (CPSs) are characterized by software that interacts with the physical world, often with time-sensitive safety-critical physical sensing and actuation (Lee et al . 2017). Applications such as aircraft pilot support or automated driving systems require more than what classical CPSs provide. More specifically, application functionality increasingly relies on machine learning techniques, while cyber-security requirements have become significantly more stringent. We refer to CPSs enhanced with high-performance machine learning capabilities and strong cyber-security support as “intelligent systems”. Given the state of CMOS computing technology (Kanduri et al . 2017), providing the processing performances required by intelligent systems while meeting the size, weight and power (SWaP) constraints of embedded systems can only be achieved by parallel computing and the specialization of processing elements. For example, automated driving systems targeting L3/L4 SAE J3016 levels of automation are estimated to require over 150 TOPS of deep learning inference in vehicle perception functions, while motion planning functions would require more than 50 FP32 TFLOPS (Figure 2.5).
In order to address the challenges of high-performance embedded computing with time predictability, Kalray has been refining a many-core architecture called the MPPA (Massively Parallel Processor Array) across three generations. The first-generation MPPA processor was primarily targeting accelerated computing (Dupont de Dinechin et al . 2013), but implemented the first key architectural features for time-critical computing (Dupont de Dinechin et al . 2014). Kalray further improved the second-generation MPPA processor for time predictability (Saidi et al . 2015), providing an excellent target for model-based code generation (Perret et al . 2016; Graillat et al . 2018, 2019). Accurate analysis of network-on-chip (NoC) service guarantees was achieved through a new deterministic network calculus formulation (Dupont de Dinechin and Graillat 2017). Unlike the first-generation MPPA processor that relied on cyclostatic dataflow programming (Bodin et al . 2013, 2016), the second-generation MPPA programming environment was able to support OpenCL and OpenVX applications (Hascoët et al . 2018).
In this chapter, we present the third-generation MPPA processor, manufactured in 16FFC CMOS technology, whose many-core architecture has significantly improved upon the previous ones in the areas of performance, programmability, functional safety and cyber-security. These features are motivated by application cases in defense, avionics and automotive where the high-performance, high-integrity and cyber-security functions can be consolidated onto a single or dual processor configuration. In section 2.2, we discuss many-core architectures and their limitations with regard to intelligent system requirements. In section 2.3, we present the main features of the third-generation MPPA architecture and processor. In section 2.4, we introduce the MPPA3 application software environments.
2.2. Motivations and context
2.2.1. Many-core processors
A multi-core processor refers to a computing device that contains multiple software-programmable processing units (cores with caches). Multi-core processors deployed in desktop computers or data centers have homogeneous cores and a memory hierarchy is composed of coherent caches (Figure 2.1). Conversely, a many-core processor can be characterized by the architecturally visible grouping of cores inside compute units: cache coherence may not extend beyond the compute unit; or the compute unit may provide scratch-pad memory and data movement engines. A multi-core processor scales by replicating its cores, while a many-core processor scales by replicating its compute units. A many-core architecture may thus be scaled to hundreds, if not thousands, of cores.
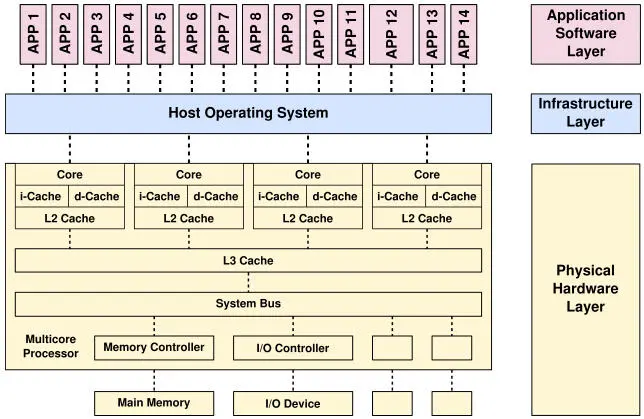
Figure 2.1. Homogeneous multi-core processor (Firesmith 2017)
The GPGPU architecture introduced by the NVIDIA Fermi (Figure 2.2) is a mainstream many-core architecture, whose compute units are called streaming multiprocessors (SMs). Each SM comprises 32 streaming cores (SCs) that share a local memory, caches and a global memory system. Threads are scheduled and executed atomically by “warps”, which are sets of 32 threads dispatched to SCs that execute the same instruction at any given time. Hardware multi-threading enables warp execution switching on each cycle, helping to cover the memory access latencies.
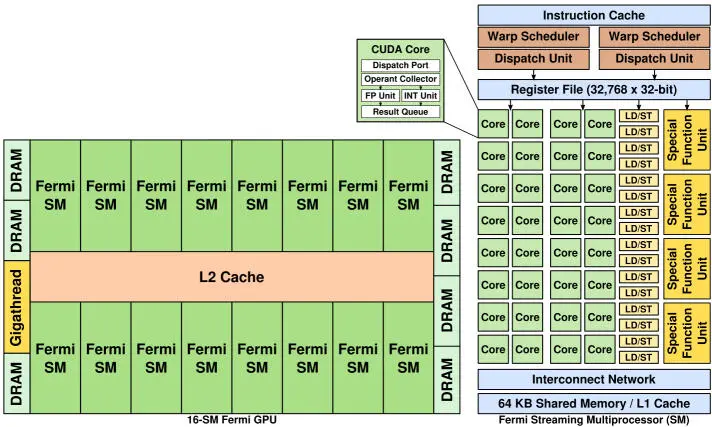
Figure 2.2. NVIDIA fermi GPGPU architecture (Huang et al . 2013)
Although embedded GPGPU processors provide adequate performance and energy efficiency for accelerated computing, their architecture carry inherent limitations that hinder their use in intelligent systems:
– kernel programming environment lacks standard features of C/C++, such as recursion, standard multi-threading or accessing a (virtual) file system;
– performance of kernels is highly sensitive to run-time control flow (because of branch divergence) and data access patterns (because of memory coalescing);
– threads blocks are dynamically allocated to SMs, while warps are dynamically scheduled for execution inside an SM;
– coupling between the host CPU and the GPGPU relies on a software stack that results in long and hard-to-predict latencies (Cavicchioli et al. 2019).
2.2.2. Machine learning inference
The main uses of machine learning techniques in intelligent systems are inference of deep learning networks. When considering deep learning inference acceleration, several architectural approaches appear effective. These include loosely coupled accelerators that implement a systolic data path (Google TPU, NVIDIA NVDLA), coarse-grained reconfigurable arrays (Cerebras WSE) or a bulk-synchronous parallel graph processor (GraphCore IPU). Other approaches tightly couple general-purpose processing units with vector or tensor processing units that share the instruction stream and the memory hierarchy. In particular, the GPGPU architecture has further evolved with the NVIDIA Volta by integrating eight “tensor cores” per SM, in order to accelerate machine learning workloads (Jia et al . 2018). Each tensor core executes mixed-precision matrix multiply-accumulate operations on 4 × 4 matrices. Multiplication operand elements use the IEEE 754 binary 16 floating-point representation (FP16), while the accumulation and result operands use the IEEE 754 binary 16 or binary 32 (FP32) floating-point representation (Figure 2.3).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Multi-Processor System-on-Chip 1»
Представляем Вашему вниманию похожие книги на «Multi-Processor System-on-Chip 1» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Multi-Processor System-on-Chip 1» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.