Liliana Andrade - Multi-Processor System-on-Chip 1
Здесь есть возможность читать онлайн «Liliana Andrade - Multi-Processor System-on-Chip 1» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Multi-Processor System-on-Chip 1
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Multi-Processor System-on-Chip 1: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Multi-Processor System-on-Chip 1»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Multi-Processor System-on-Chip 1 — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Multi-Processor System-on-Chip 1», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The AGUs of the ARC EM9D processor support complex memory access patterns without spending cycles on load and store instructions. We illustrate the benefits of the AGUs with a code example of a fully connected layer. Each output value is calculated using a dot-product operation. We consider the case where inputs are vectors of 16-bit values and weights are vectors of 8-bit values. Typically, this implies the extension of the weight operands to 16-bit values, which takes additional process cycles inside a loop. The ARCv2DSP instruction set architecture (ISA) has several dual-MAC instructions, which allow two multiplications with accumulation in a single cycle (see the left diagram in Figure 1.5). These include 16x8 dual-MAC instructions where one operand is a 2x16-bit vector and the other operand is a 2x8-bit vector, which allows direct use of the 8-bit data. The assembly code in Figure 1.7, generated from high-level C-code, shows that this yields a zero-overhead loop with a loop body of just one DMAC instruction and a throughput of two 16x8 MACs/cycle. In addition to the dual-MAC, the DMAC instruction also performs two memory reads and two pointer updates through the two AGUs.
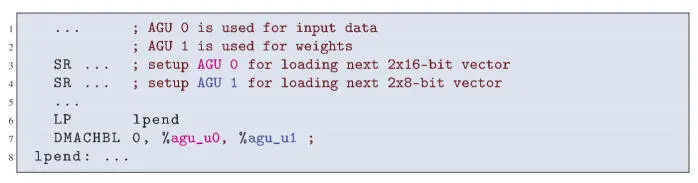
Figure 1.7. Assembly code generated from MLI C-code for a fully connected layer with 16-bit input data and 8-bit weights
Similar optimizations using dual-MAC instructions are used for other kernels, including RNN kernels and some convolution kernels. However, this approach is not convenient for all cases. As an example, we consider a depthwise convolution for a channel–height–width (CHW) data layout with a 3x3 weight kernel size. This type of layer applies a 2D convolution to each input channel separately. Dual-MAC instructions cannot be used optimally here, due to the odd weight kernel size and the short MAC series for calculating an output value. If the convolution stride parameter is equal to 1, then neighboring input data elements are used for the calculation of neighboring output values. This implies that we can calculate two output values simultaneously using VMAC instructions that use two accumulators (see the right diagram in Figure 1.5), as shown in the generated assembly code in Figure 1.8. The VMAC instructions each perform two 16x16 MACs as well as two memory reads, sign extension and replication of the 8-bit value accessed through AGU 2 and two pointer updates.
This example demonstrates the flexibility of AGUs for complex data addressing patterns, including 2D accesses using two modifiers for the input data as well as sign extension and replication of weights. A typical approach for calculating convolution layers, for example, as popularized by Caffe, is to use additional image-to-column (im2col) transformations. Although such transformations are helpful on some processors as they simplify subsequent calculations for performing the convolutions, this comes at a price of a significant overhead for performing these transformations. The advanced AGUs, as used in Figure 1.8, make these transformations obsolete, thereby supporting efficient embedded implementations.
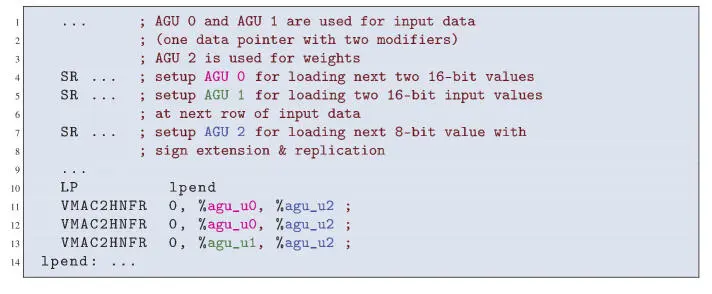
Figure 1.8. Assembly code generated from MLI C-code for 2D convolution of 16-bit input data and 8-bit weights
From the user’s point of view, the embARC MLI library provides ease of use, allowing the construction of efficient machine learning inference engines without requiring in-depth knowledge of the processor architecture and software optimization details. The embARC MLI library provides a broad set of optimized functions, so that the user can concentrate on the application and write embedded code using familiar high-level constructs for machine learning inference.
1.3.4. Example machine learning applications and benchmarks
The embARC MLI library is available from embarc.org(embARC Open Software Platform 2019), together with a number of example applications that demonstrate the usage of the library, such as:
– CIFAR-10 low-resolution object classifier: CNN graph;
– face detection: CNN graph;
– human activity recognition (HAR): LSTM-based network;
– keyword spotting: graph with CNN and LSTM layers trained on the Google speech command dataset.
The CIFAR-10 (Krizhevsky 2009) example application is based on the Caffe (Jia et al . 2014) tutorial. The CIFAR-10 dataset is a set of 60,000 low-resolution RGB images (32x32 pixels) of objects in 10 classes, such as “cat”, “dog” and “ship”. This dataset is widely used as a “Hello World” example in machine learning and computer vision. The objective is to train the classifier using 50,000 of these images, so that the other 10,000 images of the dataset can be classified with high accuracy. We used the CIFAR-10 CNN graph in Figure 1.9 for training and inference. This graph matches the CIFAR-10 graph from the Caffe tutorial, including the two fully connected layers towards the end of the graph.

Figure 1.9. CNN graph of the CIFAR-10 example application
We used the CIFAR-10 example application with 8-bit for both feature data and weights to benchmark the performance of machine learning inference on the ARC EM9D processor. The code of this CIFAR-10 application, built using the embARC MLI library, is illustrated in Figure 1.10.
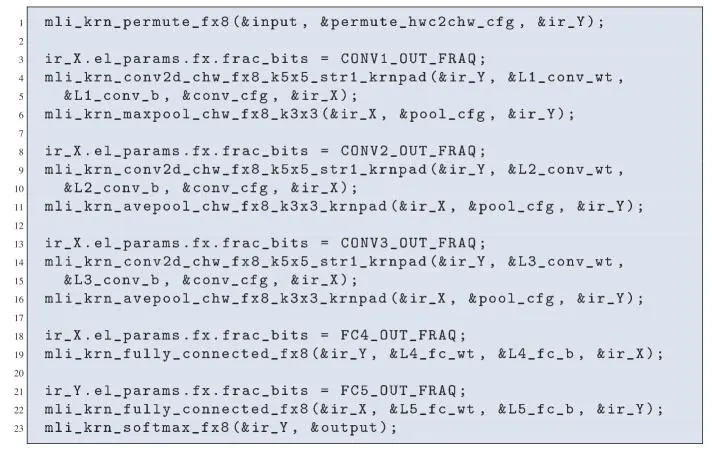
Figure 1.10. MLI code of the CIFAR-10 inference application
As the code in Figure 1.10 shows, each layer in the graph is implemented by calling a function from the embARC MLI library. Before executing the first convolution layer, we call a permute function from the embARC MLI library to transform the RGB image into CHW format so that neighboring data elements are from the same color plane. The code further shows that a ping-pong scheme with two buffers, ir_X and ir_Y, is used for buffering input and output maps.
A very similar CIFAR-10 CNN graph has been used by others for benchmarking machine learning inference on their embedded processors, with performance numbers published in (Lai et al . 2018) and (Croome 2018). Table 1.3 presents the model parameters of the CIFAR-10 CNN graph that we used, with performance data for the ARC EM9D processor and two other embedded processors presented in Table 1.4.
Table 1.3. Model parameters of the CIFAR-10 CNN graph
| # | Layer type | Weights tensor shape | Output tensor shape | Coefficients |
| 0 | Permute | – | 3 × 32 × 32 | 0 |
| 1 | Convolution | 32 × 3 × 5 × 5 | 32 × 32 × 32 (32K) | 2400 |
| 2 | Max Pooling | – | 32 × 16 × 16 (8K) | 0 |
| 3 | Convolution | 32 × 32 × 5 × 5 | 32 × 16 × 16 (8K) | 25600 |
| 4 | Avg Pooling | - | 32 × 8 × 8 (2K) | 0 |
| 5 | Convolution | 64 × 32 × 5 × 5 | 64 × 8 × 8 (4K) | 51200 |
| 6 | Avg Pooling | – | 64 × 4 × 4 (1K) | 0 |
| 7 | Fully-connected | 64 × 1024 | 64 | 65536 |
| 8 | Fully-connected | 10 × 64 | 10 | 640 |
The performance data for processor A is published in (Lai et al . 2018) in terms of milliseconds for a processor running at a clock frequency of 216 MHz. The cycle counts for processor A in Table 1.4 have been calculated by multiplying the published millisecond numbers with this clock frequency. The CIFAR-10 CNN graph reported in (Lai et al . 2018) has the same convolution and pooling layers as listed in Table 1.3, but uses a single fully connected layer with a 4x4x64x10 filter shape to directly transform the 64x4x4 input map into 10 output values. This modification of the Caffe CNN graph reduces the size of the weight data considerably, but requires retraining of the graph. The impact on the total cycle count is marginal.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Multi-Processor System-on-Chip 1»
Представляем Вашему вниманию похожие книги на «Multi-Processor System-on-Chip 1» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Multi-Processor System-on-Chip 1» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.