Liliana Andrade - Multi-Processor System-on-Chip 1
Здесь есть возможность читать онлайн «Liliana Andrade - Multi-Processor System-on-Chip 1» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Multi-Processor System-on-Chip 1
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Multi-Processor System-on-Chip 1: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Multi-Processor System-on-Chip 1»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Multi-Processor System-on-Chip 1 — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Multi-Processor System-on-Chip 1», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Efficient execution of the dot-product operations requires not only proper vector MAC instructions, but also sufficient memory bandwidth to feed operands to these MAC instructions, as well as ways to avoid overhead for performing address updates, data size conversions, etc. For these purposes, the ARC EM9D processor provides XY memory with advanced address generation. Simply, the XY architecture provides up to three logical memories that the processor can access concurrently, as illustrated in Figure 1.6. The processor can access memory through a regular load, store instruction or enable a functional unit to perform memory accesses through address generation units (AGUs). An AGU can be set up with an address pointer to data in one of the memories and a prescription, or modifier, to update this address pointer in a particular way when a data access is performed through the AGU. After the setup, the AGUs can be used in instructions for directly accessing operands and storing results from/to memory. No explicit load or store instructions need to be executed for these operands and results. Typically, an AGU is set up before a software loop and then used repeatedly as data is traversed inside the loop.
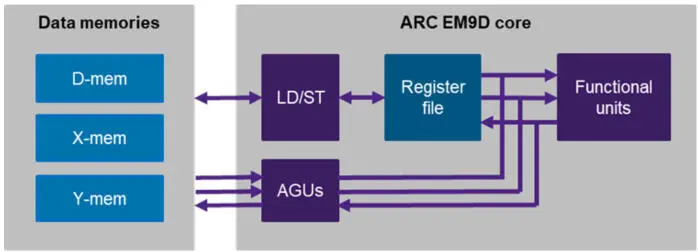
Figure 1.6. ARC EM9D processor with XY memory and address generation units
The AGUs support the following features relevant to machine learning inference:
– multiple modifiers per address pointer, which allow different schemes for address pointer updates to be prescribed and used. For example, a 2D access pattern can be supported by having one modifier prescribing a small horizontal stride within a row in the input map and another modifier prescribing a large stride to move the pointer to the next row in the input map;
– data size conversions, which allow, for example, 2x8-bit data to be expanded on the fly for use as a 2x16-bit vector operand. No extra instructions for unpacking and sign extension are required;
– replications, which allow data values to be replicated on the fly into vectors. For example, a single weight value may be replicated into a 2x16 vector for use in the VMAC instruction as discussed above.
In summary, the use of XY memory and AGUs enables very efficient code as no instructions are needed to load and store data, perform pointer math, or convert and rearrange data. All of these are performed implicitly while accessing data through the AGUs, with up to three memory accesses per cycle. In the next section, we present code examples that illustrate the use of the processor’s XY memory and AGUs for machine learning inference.
Most other embedded processors have to issue explicit load and store instructions to perform accesses to memory. In a single-issue processor, the execution of these instructions may consume a significant portion of the available cycles, effectively reducing the throughput in MACs/cycle. Multi-issue processors, such as VLIW processors, aim to perform the load and store operations in parallel to compute operations (such as the MACs) to increase throughput. However, since wide instructions have to be used, this comes at the price of larger code size and higher power consumption in the instruction memory.
1.3.3. A software library for machine learning inference
After selecting the right processor, the next question is how to arrive at an efficient software implementation of the targeted machine learning inference application. For this purpose, we present a library of reusable software modules to show how these are implemented efficiently on the ARC EM9D processor.
Table 1.2. Supported kernels in the embARC MLI library
| Group | Kernels | Description |
| Convolution | 2D convolution Depthwise 2D convolution | Convolve input features with a set of trained weights |
| Pooling | Average pooling Max pooling | Pool input features with a function |
| Recurrent and Core | Basic RNN Long-Short Term Memory (LSTM) Fully connected | Recurrent and fully connected kernels |
| Transform (Activation) | ReLU (Relu1, Relu6, Leaky ReLU, ..) Sigmoid and TanH SoftMax | Transform each element of input according to a particular non-linear function |
| Element-wise | Addition, subtraction, multiplication maximum, minimum | Apply multi-operand function element-wise to several inputs |
| Data Manipulation | Permute Concatenation Padding 2D | Move or extend input data by a specified pattern |
The embARC machine learning inference (MLI) library (embARC Open Software Platform 2019) is a set of C functions and associated data structures for building neural networks. Library functions, also called kernels , implement the processing associated with a complete layer in a neural network, with multidimensional input/output maps represented as tensor structures. Thus, a neural network graph can be implemented as a series of MLI function calls. Table 1.2 lists the currently supported MLI kernels, organized into six groups. For each kernel, there can be multiple functions in the library, including functions specifically optimized to support particular data types, weight kernel sizes and strides. In addition, helper functions are provided; these include operations such as data type conversion, data pointing and other operations not directly involved in the kernel functionality.
A notable feature of the embARC MLI library is the explicit support for recurrent layers. Sequential data series from sensors such as microphones or accelerometers are frequently used in the IoT domain. As explained above, RNNs maintain the state while processing sequences of inputs, thereby having the ability to recognize patterns across time. They have proven their effectiveness and are widely used in state-of-the-art solutions, such as speech applications (Amodei et al . 2016).
Data representation is an important part of the MLI definition. Despite the large variety of kernels, the data directly involved in the calculations has common properties. Deep learning frameworks therefore typically employ a unified data representation. For example, TensorFlow works with tensors, while Caffe uses similar objects called “blobs”. Such objects represent multidimensional arrays of the proper sizes and may include additional data, such as links to related objects, synchronization primitives, etc. Similarly, mli_tensor is a universal data container in MLI. It is a lightweight tensor that contains the necessary elements for describing the data: a pointer to the data buffer, its capacity, shape, rank and data format-specific values. A kernel may take multiple tensors as inputs for producing an output tensor. For example, the 2D convolution kernel has three input tensors: the input map, the weights and the biases. All kernel-specific parameters, such as stride and padding for a convolution kernel, or the new order of dimensions for a permute kernel, are grouped into configuration structures. This data representation has several advantages:
– it provides a simple and clear interface for the functions;
– it allows the same interface to be used for several versions of one kernel;
– it matches well with layered neural networks, enabling ease of use and natural library extensibility.
The embARC MLI library uses signed fixed-point data types based on the Q-notation ( Q Number Format 2019). Tensor structures with 8-bit and 16-bit data types are supported, both for input/output data and weights. When building an application, we should select the data types that provide sufficiently accurate results for each layer in the neural network. In addition to supporting kernels with the same data type (either 16-bit or 8-bit) for both data and weights, the MLI library also provides kernels with 16-bit data and 8-bit weights, in order to provide more flexibility for accuracy-vs-memory trade-offs.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Multi-Processor System-on-Chip 1»
Представляем Вашему вниманию похожие книги на «Multi-Processor System-on-Chip 1» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Multi-Processor System-on-Chip 1» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.