Daniel J. Denis - Applied Univariate, Bivariate, and Multivariate Statistics
Здесь есть возможность читать онлайн «Daniel J. Denis - Applied Univariate, Bivariate, and Multivariate Statistics» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Applied Univariate, Bivariate, and Multivariate Statistics
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Applied Univariate, Bivariate, and Multivariate Statistics: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Applied Univariate, Bivariate, and Multivariate Statistics»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
contains an accessible introduction to statistical modeling techniques commonly used in the social and behavioral sciences. The text offers a blend of statistical theory and methodology and reviews both the technical and theoretical aspects of good data analysis.
Featuring applied resources at various levels, the book includes statistical techniques using software packages such as R and SPSS®. To promote a more in-depth interpretation of statistical techniques across the sciences, the book surveys some of the technical arguments underlying formulas and equations. The thoroughly updated edition includes new chapters on nonparametric statistics and multidimensional scaling, and expanded coverage of time series models. The second edition has been designed to be more approachable by minimizing theoretical or technical jargon and maximizing conceptual understanding with easy-to-apply software examples. This important text:
Offers demonstrations of statistical techniques using software packages such as R and SPSS® Contains examples of hypothetical and real data with statistical analyses Provides historical and philosophical insights into many of the techniques used in modern social science Includes a companion website that includes further instructional details, additional data sets, solutions to selected exercises, and multiple programming options Written for students of social and applied sciences,
offers a text to statistical modeling techniques used in social and behavioral sciences.
Applied Univariate, Bivariate, and Multivariate Statistics — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Applied Univariate, Bivariate, and Multivariate Statistics», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
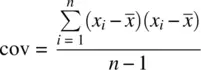
But what is this covariance? If we rewrite the numerator as 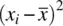 instead of
instead of 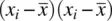 , it becomes clear that the covariance of a variable with itself is nothing more than the usual variancefor that variable. Hence, to better understand the covariance, it is helpful to start with the variance, and then realize that instead of computing the cross‐product of a variable with itself, the covariance computes the cross‐product of a variable with a secondvariable.
, it becomes clear that the covariance of a variable with itself is nothing more than the usual variancefor that variable. Hence, to better understand the covariance, it is helpful to start with the variance, and then realize that instead of computing the cross‐product of a variable with itself, the covariance computes the cross‐product of a variable with a secondvariable.
We compute the covariance between parent height and child height in Galton's data:
> attach(Galton) > cov(parent, child) [1] 2.064614
We have mentioned that the covariance is a measure of linear relationship. However, sample covariances from data set to data set are not comparable unless one knows more of what went into each specific computation. There are actually three things that can be said to be the “ingredients” of the covariance. The first thing it contains is a measure of the cross‐product, which represents the degree to which variables are linearly related. This is the part in our computation of the covariance that we are especially interested in. However, other than concluding a negative, zero, or positive relationship, the size of the covariance does not by itself tell us the degreeto which two variables are linearly related.
The reason for this is that the size of covariance will also be impacted by the degree to which there is variability in x iand the degree to which there is variability in y i. If either or both variables contain sizeable deviations of the sort 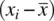 or
or 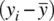 , then the corresponding cross‐products
, then the corresponding cross‐products 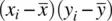 will also be quite sizeable, along with their sum,
will also be quite sizeable, along with their sum, 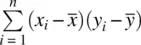 . However, we do not want our measure of relationship to be small or large as a consequence of variability on x ior variability on y i. We want our measure of relationship to be small or large as an exclusive result of covariability, that is, the extent to which there is actually a relationshipbetween x iand y i. To incorporate the influences of variability in x iand y i(one may think of it as “purifying”), we divide the average cross‐product (i.e., the covariance) by the product of standard deviations of each variable. The standardized sample covarianceis thus:
. However, we do not want our measure of relationship to be small or large as a consequence of variability on x ior variability on y i. We want our measure of relationship to be small or large as an exclusive result of covariability, that is, the extent to which there is actually a relationshipbetween x iand y i. To incorporate the influences of variability in x iand y i(one may think of it as “purifying”), we divide the average cross‐product (i.e., the covariance) by the product of standard deviations of each variable. The standardized sample covarianceis thus:
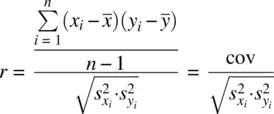
The standardized covariance is known as the Pearson product‐moment correlation coefficient, or simply r , which is a biasedestimator of its population counterpart, ρ xy, except when ρ xyis exactly equal to 0. The bias of the estimator r can be minimized by computing an adjustment found in Rencher (1998, p. 6), originally proposed by Olkin and Pratt (1958):
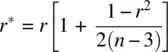
Because the correlation coefficient is standardized, we can place lower and upper bounds on it. The minimum the correlation can be for any set of data is −1.0, representing a perfect negative relationship. The maximum the correlation can be is +1.0, representing a perfect positive relationship. A correlation of 0 represents the absence of a linearrelationship. For further discussion on how the Pearson correlation can be a biased estimate under conditions of nonnormality (and potential solutions), see Bishara and Hittner (2015).
One can gain an appreciation for the upper and lower bound of r by considering the fact that the numerator, which is an average cross‐product, is being divided by another product, that of the standard deviations of each variable. The denominator thus can be conceptualized to represent the total amount of cross‐product variation possible, that is, the “base,” whereas the numerator represents the total amount of cross‐product variation actually existing between the variables because of a linear relationship. The extent to which cov xyaccounts for all of the possible “cross‐variation” in 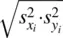 is the extent to which r will approximate a value of |1| (either positive or negative, depending on the direction of the relationship). It thus stands that cov xycannot be greater than the “base” to which it is being compared (i.e.,
is the extent to which r will approximate a value of |1| (either positive or negative, depending on the direction of the relationship). It thus stands that cov xycannot be greater than the “base” to which it is being compared (i.e.,  ). In the language of sets, cov xymust be a subsetof the larger set represented by
). In the language of sets, cov xymust be a subsetof the larger set represented by 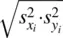 .
.
It is important to emphasize that a correlation of 0 does not necessarily represent the absenceof a relationship. What it does represent is the absence of a linearone. Neither the covariance or Pearson's r capture nonlinear relationships, and so it is possible to have very strong relations in a sample or population yet still obtain very low values (even zero) for the covariance or Pearson r . Always plot your data to see what is going on before drawing any conclusions. Correlation coefficients should never be presented without an accompanying plot to characterize the form of the relationship.
We compute the Pearson correlation coefficient on Galton's data between childand parent:
> cor(child, parent) [1] 0.4587624
We can test it for statistical significance by using the cor.testfunction:
> cor.test(child, parent) Pearson's product-moment correlation data: child and parent t = 15.7111, df = 926, p-value < 2.2e-16 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.4064067 0.5081153 sample estimates: cor 0.4587624
We can see that observed t is statistically significant with a computed 95% confidence interval having limits 0.41 to 0.51, indicating that we can be 95% confident that the true parameter lies approximately between the limits of 0.41 and 0.51. Using the package ggplot2(Wickham, 2009), we plot the relationship between parent and child (with a smoother):
Интервал:
Закладка:
Похожие книги на «Applied Univariate, Bivariate, and Multivariate Statistics»
Представляем Вашему вниманию похожие книги на «Applied Univariate, Bivariate, and Multivariate Statistics» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Applied Univariate, Bivariate, and Multivariate Statistics» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.