Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
We prove below that the recovery mechanism introduced in section 2.3.2.3guarantees a consistent global state of the distributed system after the recovery of a failed process. The only way the global state of a distributed system becomes inconsistent is when one process records the receipt of a (regular) message that was not sent by any other process ( i.e., the message is an orphan message). We prove that any regular message that is received at a process must have been logged at the sending process. For a pair of nonfailing processes, the correctness of this statement is straightforward because the sending process always logs any message it sends. The interesting case is when a nonfailing process received a regular message that was sent by a process that fails subsequently.
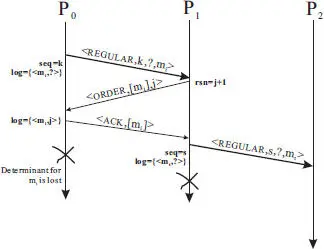
Figure 2.19 Two concurrent failures could result in the loss of determinant information for regular messages.
Let’s assume a process Pi fails and another process Pj receives a regular message sent by Pi prior to the failure, we need to prove that the message must have been logged at Pi either prior to its failure or will have been logged before the end of the recovery.
If Pi checkpointed its state after sending the regular message prior to the failure, the message must have been logged in stable storage and is guaranteed to be recoverable. Otherwise, the message itself would have been lost due the failure because it was logged in volatile memory. However, we prove that the message will be regenerated during the recovery.
According to the protocol, a process cannot send any new regular message before it has received the ACK message for every regular message received. The fact that the message was sent means Pi must have received the ACK message for the regular message that triggered the state interval in which the message was sent. This in turn means that the sending process of the regular message, say Pk must have received the corresponding ORDER message sent by Pi . Hence, upon recovery, Pk will be contacted by Pi and the regular message with a valid rsn value will be retransmitted to Pi . This would ensure the recovering process Pi to reinitiate the state interval in the correct order. The regular message received by Pj will be correctly regenerated and logged at Pi during recovery. This completes our proof.
2.3.2.5 Discussion.
As we have mentioned before, unlike the receiver-based pessimistic logging, performing a local checkpointing at a process does not truncate its message log because the log contains messages sent to other processes and they might be needed for the recovery of these other processes. This is rather undesirable. Not only it means unbounded message log size, but it leads to unbounded recovery time as well.
The sender-based message logging protocol can be modified to at least partially fix the problem. However, it will be at the expense of the locality of local checkpointing. Once a process completes a local checkpoint, it broadcasts a message containing the highest rsn value for the messages that it has executed prior to the checkpoint. All messages sent by other processes to this process that were assigned a value that is smaller or equal to this rsn value can now to purged from its message log (including those in stable storage as part of a checkpoint). Alternatively, this highest rsn value can be piggybacked with each message (regular or control messages) sent to another process to enable asynchronous purging of the logged messages that are no longer needed.
REFERENCES
1. L. Alvisi and K. Marzullo. Message logging: Pessimistic, optimistic, causal, and optimal. IEEE Trans. Softw. Eng. , 24(2):149–159, Feb. 1998.
2. B. K. Bhargava and S.-R. Lian. Independent checkpointing and concurrent rollback for recovery in distributed systems - an optimistic approach. In Symposium on Reliable Distributed Systems , pages 3–12, 1988.
3. B. K. Bhargava, S.-R. Lian, and P.-J. Leu. Experimental evaluation of concurrency checkpointing and rollback-recovery algorithms. In ICDE , pages 182–189. IEEE Computer Society, 1990.
4. A. Borg, W. Blau, W. Graetsch, F. Herrmann, and W. Oberle. Fault tolerance under unix. ACM Trans. Comput. Syst. , 7(1):1–24, Jan. 1989.
5. K. M. Chandy and L. Lamport. Distributed snapshots: determining global states of distributed systems. ACM Trans. Comput. Syst. , 3(1):63–75, Feb. 1985.
6. D. Davis, A. Karmarkar, G. Pilz, S. Winkler, and U. Yalcinalp. Web Services Reliable Messaging (WSReliableMessaging) Version 1.2, OASIS Standard. http://docs.oasis-open.org/ws-rx/wsrm/200702/wsrm-1.2-spec-os.pdf, February 2009.
7. E. N. M. Elnozahy, L. Alvisi, Y.-M. Wang, and D. B. Johnson. A survey of rollback-recovery protocols in message-passing systems. ACM Comput. Surv. , 34(3):375–408, Sept. 2002.
8. O. Etzion and P. Niblett. Event Processing in Action . Manning Publications, 2010.
9. S. Ghemawat, H. Gobioff, and S.-T. Leung. The google file system. SIGOPS Oper. Syst. Rev. , 37(5):29–43, Oct. 2003.
10. J. Gray and P. Kukol. Sequential disk io tests for gbps land speed record. Technical report, Microsoft Research, 2004.
11. Y. Huang and Y.-M. Wang. Why optimistic message logging has not been used in telecommunications systems. In Proceedings of the Twenty-Fifth International Symposium on Fault-Tolerant Computing , FTCS ’95, pages 459–, Washington, DC, USA, 1995. IEEE Computer Society.
12. R. K. Jain. The Art of Computer Systems Performance Analysis: Techniques for Experimental Design, Measurement, Simulation, and Modeling . Wiley, 1991.
13. D. B. Johnson and W. Zwaenepoel. Sender-based message logging. In The 7th annual international symposium on fault-tolerant computing . IEEE Computer Society, 1987.
14. F. Miller, A. Vandome, and J. McBrewster. Standard Raid Levels . Alphascript Publishing, 2009.
15. E. Newcomer and G. Lomow. Understanding SOA with Web Services . Addison-Wesley Professional, 2004.
16. B. Randell. System structure for software fault tolerance. In Proceedings of the international conference on Reliable software , pages 437–449, New York, NY, USA, 1975. ACM.
17. J. H. Saltzer, D. P. Reed, and D. D. Clark. End-to-end arguments in system design. ACM Transactions on Computer Systems , 2(4):277–288, 1984.
18. R. D. Schlichting and F. B. Schneider. Fail-stop processors: an approach to designing fault-tolerant computing systems. ACM Trans. Comput. Syst. , 1(3):222–238, Aug. 1983.
19. A. P. Sistla and J. L. Welch. Efficient distributed recovery using message logging. In Proceedings of the eighth annual ACM Symposium on Principles of distributed computing , PODC ’89, pages 223–238, New York, NY, USA, 1989. ACM.
20. S. W. Smith and D. B. Johnson. Minimizing timestamp size for completely asynchronous optimistic recovery with minimal rollback. In Proceedings of the 15th Symposium on Reliable Distributed Systems , SRDS ’96, pages 66–, Washington, DC, USA, 1996. IEEE Computer Society.
21. R. Strom and S. Yemini. Optimistic recovery in distributed systems. ACM Trans. Comput. Syst. , 3(3):204–226, Aug. 1985.
22. Y. Tamir and C. H. Suin. Error recovery in multicomputers using global checkpoints. In In 1984 International Conference on Parallel Processing , pages 32–41, 1984.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.