Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
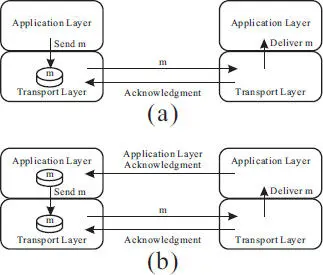
Figure 2.12 Transport level (a) and application level (b) reliable messaging.
To ensure application level reliable messaging, the sending process must store a copy of the message sent (in the application level) for possible retransmission until it receives an explicit acknowledgment message from the receiving process in the application level, as shown in Figure 2.12(b). Such an application level reliable messaging protocol does exist in some distributed computing paradigm, such as Web services [6]. Incidentally, the sender-based message logging protocol [13], to be introduced in a later subsection, incorporates a similar mechanism, albeit for a slightly different purpose.
We should note that the use of such an application level reliable messaging protocol is essential not only to ensure the atomicity of message receiving and logging, but also to facilitate the distributed system to recover from process failures (for example, the failure of the process at one end point of a transport level connection, which would cause the breakage of the connection, would have no negative impact on the process at the other end of the connection, and a process is always ready to reconnect if the current connection breaks).
Furthermore, the use of an application level reliable messaging protocol also enables the following optimization: a message received can be executed immediately and the logging of the message in stable storage can be deferred until another message is to be sent [13]. This optimization has a number of benefits, as shown in Figure 2.13:
◾ Message logging and message execution can be done concurrently (illustrated in Figure 2.13(a)), hence, minimizing the latency impact due to logging.
◾ If a process sends out a message after receiving several incoming messages, the logging of such messages can be batched in a single I/O operation (illustrated in Figure 2.13(b)), further reducing the logging latency.
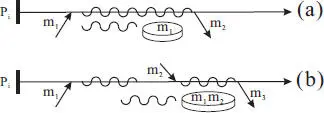
Figure 2.13 Optimization of pessimistic logging: (a) concurrent message logging and execution (b) logging batched messages.
2.3.1.3 Pessimistic Logging Cost.
While much research efforts have been carried out to design optimistic and causal logging to avoid or minimize the number of logging operations (on disks) assuming that synchronous logging would incur significant latency overhead [1, 19, 20, 21] . In this section, we present some experimental results to show that such assumption is often unwarranted. The key reason is that it is easy to ensure sequential disk I/Os by using dedicated disks. It is common nowadays for magnetic disks to offer a maximum sustained data rate of 100MB or more per second. Such transfer rate is approaching or exceeding the effective bandwidth of Gigabit Ethernet networks. Furthermore, with the increasing availability (and reduced cost) of semiconductor solid state disks, the sequential disk I/Os can be made even faster and the latency for random disk I/Os can be dramatically reduced. By using multiple logging disks together with disk striping, Gigabytes per second I/Os have been reported [10].
In the experiment, a simple client-server Java program is used where the server process logs every incoming request message sent by the client and issues a response to the client. The response message is formed by transforming the client’s request and it carries the same length as the request. The server node is equipped with a 2nd generation core i5 processor running the Windows 7 Operating system. The client runs on an iMac computer in the same local area network connected by a Gigabit Ethernet switch. The server node has two hard drives, one traditional magnetic hard drive with a spindle speed of 7,200 RPM, and the other a semiconductor solid state drive. In each run, 100,000 iterations were performed. The logging latency (at the server) and the end-to-end latency (at the client) are measured.
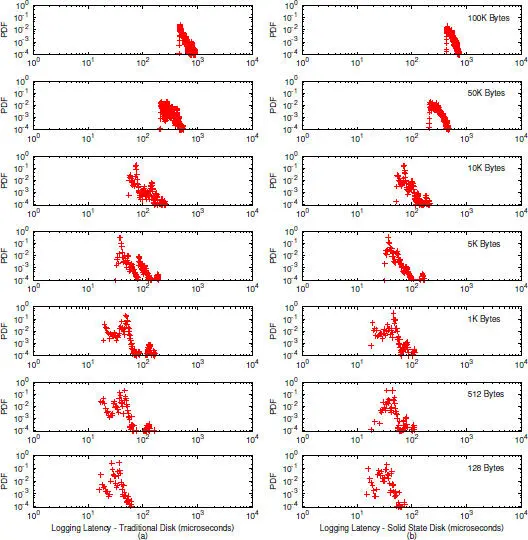
Figure 2.14 Probability density function of the logging latency.
Figure 2.14shows the logging latency for various message sizes using the traditional disk (on the left), and the solid state disk (on the right), respectively. The experimental results are presented here in the form of a sequence of probability density functions (PDF) [12] of the logging latency for various message lengths. The PDFs give much more details on the cost of logging operation than a simple average value. As can be seen, on both the solid state disk and the traditional disk, the far majority of the logging operation (for each incoming message) can be completed within 1000 μ s for messages as large as 100KB, which means the logging can be done with a rate of over 100MB per second, approaching the advertised upper limit of the data transfer rate of traditional disks. For small messages, the logging can be done within 100 μ s.
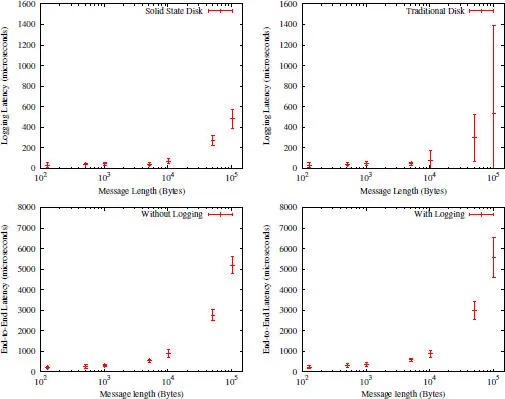
Figure 2.15 A summary of the mean logging latency and mean end-to-end latency under various conditions.
It is somewhat surprising to see that the performance on the solid state disk is not significantly better than that on the traditional disk, especially for small messages. For large messages, the solid state disk does make the logging operations more predictable in its latency, that is, the standard deviation [12] is much smaller than that on the traditional disk, as can be seen in Figure 2.15.
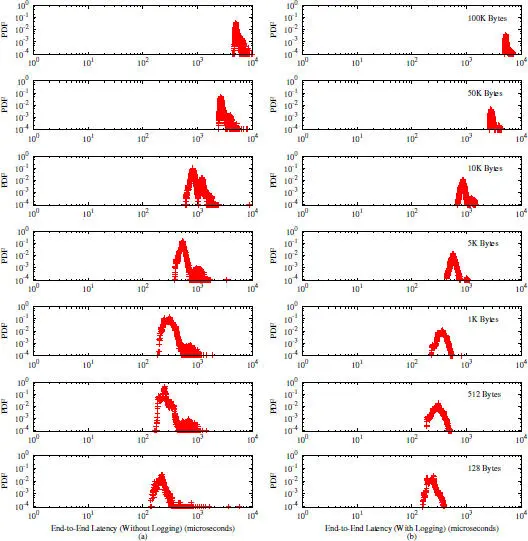
Figure 2.16 Probability density function of the end-to-end latency.
The end-to-end latency results shown in Figure 2.16prove that indeed the pessimistic logging contributes very moderate (often less than 10%) overhead to the performance of the system as observed by the client. For messages of up to 100KB, the end-to-end latency with and without pessimistic logging falls within 10 ms . For small messages, the end-to-end latency can go down as low as about 100 μ s. In all circumstances, the end-to-end latency is significantly larger than the logging latency. For the message size of 100KB, the oneway transfer latency over the network is estimated to be around 2600 μ s (half of the end-to-end latency without logging). This implies that the network manages to offer slightly under 40MB per second transfer rate.
2.3.2 Sender-Based Message Logging
For distributed applications that do not wish to log messages synchronously in stable storage, the sender-based message logging protocol [13] can be used to achieve limited degree of robustness against process failures. The basic idea of the sender-based message logging protocol is to log the message at the sending side in volatile memory. Should the receiving process fail, it could obtain the messages logged at the sending processes for recovery. To avoid restarting from the initial state after a failure, a process can periodically checkpoint its local state and write the message log in stable storage (as part of the checkpoint) asynchronously.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.