Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Upon taking a local checkpoint, a process starts logging messages, if any, arrived at each incoming channel. The process stops logging messages for a channel as soon as it has received a Marker message from that channel. The messages logged will become the state for each channel. For P 0, the channel state consists of a message m 0. For P 1, the channel state consists of a message m 1. The channel state for P 2is empty because it did not receive any message prior to the receipt of the Marker message from each of its incoming channels. Note that the regular message received (such as m 0or m 1) is executed immediately, which is drastically different from the Tamir and Sequin global checkpointing protocol.
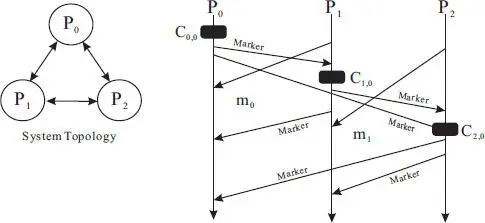
Figure 2.8 Normal operation of the Chandy and Lamport global snapshot protocol in an example three-process distributed system.
2.2.4 Discussion
The two global checkpointing protocols introduced in this section share a number of similarities.
◾ Both rely on virtually the same system model, and use a special control message to propagate and coordinate the global checkpointing.
◾ They both recognize the need to capture the channel state to ensure the recoverability of the system.
◾ The mechanism to capture the channel state is virtually the same for both protocols, as shown in Figure 2.9.– In both protocols, a process starts logging messages (for the channel state) for each channel upon the initiation of the global checkpoint (at the initiator) or upon the receipt of the first control message (i.e., the Marker message in the Chandy and Lamport protocol and the CHECKPOINT message in the Tamir and Sequin protocol).– In both protocols, the process stops logging messages and conclude the channel state for each channel when it receives the control message in that channel.
◾ The communication overhead of the two protocols is identical (i.e., the same number of control messages is used to produce a global checkpoint).
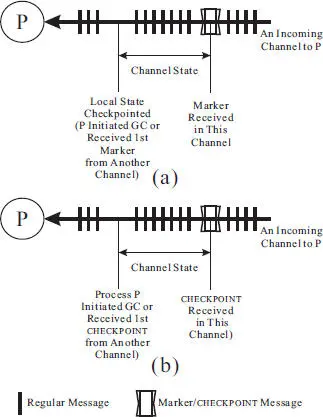
Figure 2.9 A comparison of the channel state definition between (a) the Chandy and Lamport distributed snapshot protocol and (b) the Tamir and Sequin global checkpointing protocol.
The two protocols also differ in their strategies in producing a global checkpoint.
◾ The Tamir and Sequin protocol is more conservative in that a process suspends its normal execution as soon as it learns that a global checkpointing round has started. In light of the Chandy and Lamport protocol, the suspension of normal execution could have been avoided during a global checkpointing round.
◾ The reason for the blocking design in the Tamir and Sequin protocol is that a process captures the channel states prior to taking a local checkpoint. While capturing the channel state, a process cannot execute the regular messages received because doing so would alter the process state, thereby potentially rendering the global checkpoint inconsistent. On the other hand, in the Chandy and Lamport protocol, a process captures the channel state after it has taken a local checkpoint, thereby enabling the execution of regular messages without the risk of making the global checkpoint inconsistent.
◾ The Tamir and Sequin protocol is more complete and robust because it ensures the atomicity of the global checkpointing round. Should a failure occurs, the current round would be aborted. The Chandy and Lamport protocol does not define any mechanism to ensure such atomicity. Presumably, the mechanisms defined in the Tamir and Sequin protocol can be incorporated to improve the Chandy and Lamport protocol.
2.3 Log Based Protocols
Checkpoint-based protocols only ensure to recover the system up to the most recent consistent global state that has been recorded and all executions happened afterwards, if any, are lost. Logging can be used to recover the system to the state right before the failure, provided that the piecewise deterministic assumption is valid. In log based protocols, the execution of a process is modeled as consecutive state intervals [21]. Each state interval is initiated by a nondeterministic event (such as the receiving of a message) or the initialization of the process, and followed by a sequence of deterministic state changes. As long as the nondeterministic event is logged, the entire state interval can be replayed.
As an example, three state intervals are shown in Figure 2.10. The first state interval starts at the initialization of the process Pi and ends right before it executes the first message, m 1received. Note that the sending of message m 0is not considered a nondeterministic event. The second state interval is initiated by the receiving event of message m 1and ends prior to the receipt of m 3. Similarly, the third state interval starts with the receiving event of m 3and ends prior to the receipt of m 5.
In the remaining of this section, we assume that the only type of nondeterministic events is the receiving of application messages. Therefore, logging is synonymous with message logging.
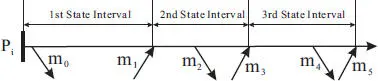
Figure 2.10 Example state intervals.
For all practical purposes, logging is always used in conjunction with checkpointing to enjoy two benefits:
1 It limits the recovery time because to recover from a failure the process can be restarted from its last checkpoint (instead from its initial state) and its state can be recovered prior to the failure by replaying the logged nondeterministic events.
2 It limits the size of the log. By taking a checkpoint periodically, the logged events prior to the checkpoint can be garbage collected.
Logging protocols can be classified into three types [7]:
◾ Pessimistic logging. A message received is synchronously logged prior to its execution.
◾ Optimistic logging. To reduce the latency overhead, the nondeterministic events are first stored in volatile memory and logged asynchronously to stable storage. Consequently, the failure of a process might result in permanent loss of some messages, which would force a rollback to a state earlier than the state when the process fails.
◾ Causal logging. The nondeterministic events (and their determinant, such as delivery order of messages received at a process) that have not yet logged to stable storage are piggybacked with each message sent. With the piggy-backed information, a process can have access all the nondeterministic events that may have causal effects on its state, thereby enabling a consistent recovery of the system upon a failure.
In both optimistic logging [21, 19, 20] and causal logging protocols [1], the dependency of the processes has to be tracked and sufficient dependency information has to be piggybacked with each message sent. This not only increases the complexity of the logging mechanisms, but most importantly, makes the failure recovery more sophisticated and expensive because the recovering process has to find a way to examine its logs and determines if it is missing any messages and often causes cascading recovery operations at other processes.
On the other hand, pessimistic logging protocols are much simpler in their design and implementation and failure recovery can be made much faster [11] (specific advantages will be elaborated in section 2.3.1below). Therefore, our discussion will focus on the pessimistic logging techniques and there will be no further elaboration on optimistic and causal logging.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.