Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
◾ The most recent checkpoint at P0, C0,1, cannot be used because it is inconsistent with C1,1. Therefore, P0 would have to rollback to C0,0.
◾ The most recent checkpoint at P1, C1,1, cannot be used because it is inconsistent with C2,1, i.e., C1,1 reflected the receiving of m6 but C2,1 does not reflect the sending of m6. This means that P1 would have to rollback to C1,0.
◾ Unfortunately, C2,1 is not consistent with C1,0 because it recorded the receiving of m4 while C1,0 does not reflect the sending of m4. This means P2 would have to rollback to C2,0.
◾ This in turn would make it impossible to use any of the two checkpoints, C3,1 or C3,0, at P3. This would result in P3 rolling back to its initial state.
◾ The rollback of P3 to its initial state would cause the invalidation of C2,0 at P2 because it reflects the state change resulted from the receiving of m1, which is not reflected in the initial state of P3. Therefore, P2 would have to be rolled back to its initial state too.
◾ The rollback of P1 to C1,0 would invalidate the use of C0,0 at P0 because of m5. This means that P0 would have to rollback to its initial state too.
◾ Finally, the rollback of P0 to its initial state would invalidate the use of C1,0 at P1, thereby forcing P1 to rollback to its initial state. Consequently, the distributed system can only recover to its initial state.
Second, to enable the selection of a set of consistent checkpoints during recovery, the dependency of the checkpoints has to be determined and recorded together with each checkpoint. This would incur additional overhead and increase the complexity of the implementation [2]. As a result, the uncoordinated checkpointing is not as simple as and not as efficient as one would have expected [3].
2.2.2 Tamir and Sequin Global Checkpointing Protocol
In this coordinated checkpointing protocol due to Tamir and Sequin [22], one of the processes is designated as the coordinator and the remaining processes are participants. The coordinator must know all other processes in the system. The coordinator uses a two-phase commit protocol to ensure that not only the checkpoints taken at individual processes are consistent with each other, the global checkpointing operation is carried out atomically, that is, either all processes successfully create a new set of checkpoints or they abandon the current round and revert back to their previous set of checkpoints. The objective of the first phase is to create a quiescent point of the distributed system, thereby ensuring the consistency of the individual checkpoints. The second phase is to ensure the atomic switchover from the old checkpoint to the new one. When a participant fails to respond to the coordinator in a timely fashion, the coordinator aborts the checkpointing round.
2.2.2.1 Protocol Description.
The finite state machine specifications for the coordinator and the participant are provided in Figure 2.4and Figure 2.5, respectively. Note that in the finite state machine specification for the coordinator as shown in Figure 2.4, the normal state is shown twice, once at the beginning (as ‘init’) and the other at the end, for clarity.
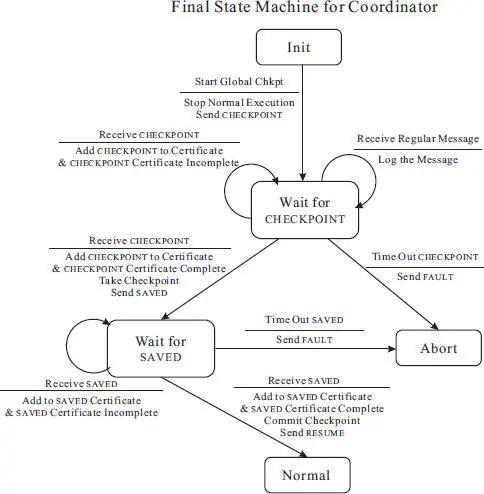
Figure 2.4 Finite state machine specification for the coordinator in the Tamir and Sequin checkpointing protocol.
More detailed explanation of the protocol rule for the coordinator and the participant is given below. In the description of the protocol, the messages exchanged between the processes in between two rounds of global checkpointing are referred to regular messages (and the corresponding execution is termed as normal execution), to differentiate them from the set of control messages introduced by the protocol for the purpose of coordination:
– CHECKPOINT message. It is used to initiate a global checkpoint. It is also used to establish a quiescent point of the distributed system where all processes have stopped normal execution. Figure 2.5 Finite state machine specification for the participant in the Tamir and Sequin checkpointing protocol.
– SAVED message. It is used for a participant to inform the coordinator that it has done a local checkpoint.
– FAULT message. It is used to indicate that a timeout has occurred and the current round of global checkpointing should be aborted.
– RESUME message. It is used by the coordinator to inform the participants that they now can resume normal execution.
Rule for the coordinator:
◾ At the beginning of the first phase, the coordinator stops its normal execution (including the sending of regular messages) and sends a CHECKPOINT message along each of its outgoing channel.
◾ The coordinator then waits for the corresponding CHECKPOINT message from all its incoming channels.– While waiting, the coordinator might receive regular messages. Such messages are logged and will be appended to the checkpoint of its state. This can only happen from an incoming channel from which the coordinator has not received the CHECKPOINT message.– The coordinate aborts the checkpointing round if it fails to receive the CHECKPOINT message from one or more incoming channels within a predefined time period.
◾ When the coordinator receives the CHECKPOINT message from all its incoming channels, it proceeds to take a checkpoint of its state.
◾ Then, the coordinator waits for a SAVED notification from every process (other than itself) in the distributed system. It aborts the checkpointing round if it fails to receive the SAVED message from one or more incoming channels within a predefined time period. It does so by sending a FAULT message along each of its outgoing channel. Note that it is impossible for the coordinator to receive any regular message at this stage.
◾ When the coordinator receives the SAVED notification from all other processes, it switches to the new checkpoint, and sends a RESUME message along each of its outgoing channel.
◾ The coordinator then resumes normal execution.
Rule for the participant:
◾ Upon receiving a CHECKPOINT notification, the participant stops its normal execution and in turn sends a CHECKPOINT message along each of its outgoing channel.
◾ The participant then waits for the corresponding CHECKPOINT message from all its incoming channels.– While waiting, the participant might receives regular messages. Such messages are logged and will be appended to the checkpoint of its state. Again, this can only happen from an incoming channel from which the participant has not received the CHECKPOINT message.– The participant aborts the checkpointing round by sending a FAULT message along each of its outgoing channel if it fails to receive the CHECKPOINT message from one or more incoming channels within a predefined time period.
◾ Once the participant has collected the set of CHECKPOINT messages, it takes a checkpoint of its state.
◾ The participant then sends a SAVED message to its upstream neighbor (from which the participant receives the first CHECKPOINT message), and waits for a RESUME message.
◾ Upon receiving a SAVED message (from one of its downstream neighbors), it relays the message to its upstream neighbor.
◾ When it receives a RESUME message, it propagates the message along all its outgoing channels except the one that connects to the process that sends it the message. The participant then resumes normal execution.
EXAMPLE 2.3
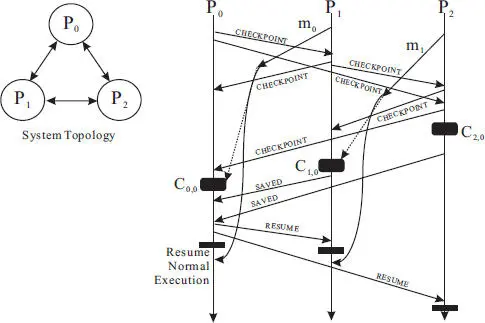
Figure 2.6 Normal operation of the Tamir and Sequin checkpointing protocol in an example three-process distributed system.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.