Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Next, let’s look at a scenarios (shown in Figure 2.2(b)) in which the set of checkpoints can be used to properly recover the system to an earlier state prior to the failure. The checkpoint ( C 0) taken by P 0reflects the sending event of m 0. The checkpoint C 1is taken by P 1after it has received m 0, therefore, the dependency on P 0is captured by C 1. Similarly, the dependency of P 2on P 1is also preserved by the checkpoint C 2taken by P 2. Such a global state is an example of consistent global state. Of course, the execution after the checkpoints, such as the sending and receiving of m 2and m 3, will be lost upon recovery.
The scenario described in Figure 2.2(c)is the most subtle one. In this scenario, P 0takes a checkpoint after it has sent message m 0while P 1takes a checkpoint before it receives m 0but after it has sent m 1, and P 2takes a checkpoint before it receives m 1. This means that the checkpoint C 0reflects the state change resulting from sending m 0whereas C 1does not incorporate the state change caused by the receiving of m 0. Consequently, this set of checkpoints cannot be used to recover the system after a failure because m 0and m 1would have been lost. However, the global state reconstructed by using such a set of checkpoints would still be qualified as a consistent global state because it is one such that it could have happened, i.e., messages m 0and m 1are still in transit to their destinations. To accommodate this scenario, an additional type of states, referred to as channel state, is introduced as part of the distributed system state [5].
To define the channel state properly, it is necessary to provide a more rigorous (and abstract) definition of a distributed system. A distributed system consists of two types of components [5]:
◾ A set of N processes. Each process, in turn, consists of a set of states and a set of events. One of the states is the initial state when the process is started. Only an event could trigger the change of the state of a process.
◾ A set of channels. Each channel is a uni-directional reliable communication channel between two processes. The state of a channel is the set of messages that are still in transit along the channel (i.e., they have not yet been received by the target process). A TCP connection between two processes can be considered as two channels, one in each direction.
A pair of neighboring processes are always connected by a pair of channels, one in each direction. An event (such as the sending or receiving of a message) at a process may change the state of the process and the state of the channel it is associated with, if any. For example, the injection of a message into a channel may change the state of the channel from empty to one that contains the message itself.
Using this revised definition, the channel states in the third scenario would consist of the two in-transit messages m 0and m 1. If the channel states can be properly recorded in addition to the checkpoints in this scenario, the recovery can be made possible ( i.e., m 0will be delivered to P 1and m 1will be delivered to P 2during recovery).
2.1.3 Piecewise Deterministic Assumption
Checkpoint-based protocols only ensure to recover the system up to the most recent consistent global state that has been recorded and all executions happened afterwards, if any, are lost. Logging can be used to recover the system to the state right before the failure, provided that all events (that could potentially change the state of the processes) are logged and the log is available upon recovery. This is what is referred to as the piecewise deterministic assumption [21]. According to this assumption, all nondeterministic events can be identified and sufficient information (referred to as a determinant [1]) must be logged for each event. The most obvious example of nondeterministic events is the receiving of a message. Other examples include system calls, timeouts, and the receipt of interrupts. In this chapter, we typically assume that the only nondeterministic events are the receiving of a message. Note that the sending of a message is not a deterministic event, i.e., it is determined by a nondeterministic event or the initial state of the process [7].
2.1.4 Output Commit
A distributed system usually receives message from, and sends message to, the outside world, such as the clients of the services provided by the distributed system. Once a message is sent to the outside world, the state of the distributed system may be exposed to the outside world. If a failure occurs, the outside world cannot be relied upon for recovery. Therefore, to ensure that the recovered state is consistent with the external view, sufficient recovery information must be logged prior to the sending of a message to the outside world. This is what so called the output commit problem [21].
2.1.5 Stable Storage
An essential requirement for logging and checkpointing protocols is the availability of stable storage. Stable storage can survive process failures in that upon recovery, the information stored in the stable storage is readily available to the recovering process. As such, all checkpoints and messages logged must be stored in stable storage.
There are various forms of stable storage. To tolerate only process failures, it is sufficient to use local disks as stable storage. To tolerate disk failures, redundant disks (such as RAID-1 or RAID-5 [14]) could be used as stable storage. Replicated file systems, such as the Google File Systems [9], can be used as more robust stable storage.
2.2 Checkpoint-Based Protocols
Checkpoint-based protocols do not rely on the piecewise deterministic assumption, hence, they are simpler to implement and less restrictive (because the developers do not have to identify all forms of nondeterministic events and log them properly). However, a tradeoff is that the distributed systems that choose to use checkpoint-based protocols must be willing to tolerate loss of execution unless a checkpoint is taken prior to every event, which is normally not realistic.
2.2.1 Uncoordinated Checkpointing
Uncoordinated checkpointing, where each process in the distributed system enjoys full autonomy and can decide when to checkpoints, even though appears to be attractive, is not recommended for two primary reasons.
First, the checkpoints taken by the processes might not be useful to reconstruct a consistent global state. In the worst case, the system might have to do a cascading rollback to the initial system state (often referred to as the domino effect [16]), which completely defeats the purpose of doing checkpointing. Consider the following example.
EXAMPLE 2.2
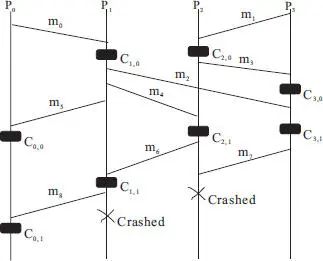
Figure 2.3 An example of the domino effect in recovery with uncoordinated checkpointing.
In the example illustrated in Figure 2.3, process P 1crashed after it has sent message m 8to P 0, but before it has a chance to take a checkpoint. The last checkpoint taken by P 1is C 1,1. Furthermore, P 2also crashed concurrently. Now, let’s examine the impact of the failure of P 1and P 2:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.