Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
There are different fault tolerance techniques that can be used to cater to different levels of dependability requirements. For applications that need high availability, but not necessarily high reliability, logging and checkpointing (which is the topic of Chapter 2), which incurs minimum runtime overhead and uses minimum extra resources, might be sufficient. More demanding applications could adopt the recovery oriented computing techniques (which is the topic of Chapter 3). Both types of fault tolerance techniques rely on rollback recovery . After restarting a failed system, the most recent correct state (referred to as a checkpoint) of the system is located in the log and the system is restored to this correct state.
An example scenario of rollback recovery is illustrated in Figure 1.2. When a system fails, it takes some time to detect the failure. Subsequently, the system is restarted and the most recent checkpoint in the log is used to recover the system back to that checkpoint. If there are logged requests, these requests are reexecuted by the system, after which the recovery is completed. The system then resumes handling new requests.
For a distributed system that requires high reliability, i.e., continuous correct services, redundant instances of the system must be used so that the system can continue operating correctly even if a portion of redundant copies (referred to as replicas) fail. Using redundant instances (referred to as replicas) also makes it possible to tolerate malicious faults provided that the replicas fail independently. When the failed replica is repaired, it can be incorporated back into the system by rolling its state forward to the current state of other replicas. This recovery strategy is called rollforward recovery .
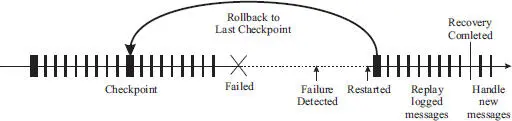
Figure 1.2 The rollback recovery is enabled by periodically taking checkpoints and usually logging of the requests received.
An example scenario of rollforward recovery is shown in Figure 1.3. When the failure of the replica is detected and the replica is restarted (possibly after being repaired). To readmit the restarted replica into the system, a nonfaulty replica takes a checkpoint of its state and transfer the checkpoint to the recovering replica. The restarted replica can rollforward its state using the received checkpoint, which represents the latest state of the system.
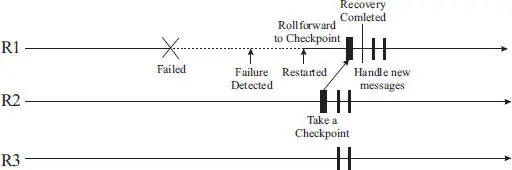
Figure 1.3 With redundant instances in the system, the failure of a replica in some cases can be masked and the system continue providing services to its clients without any disruption.
To avoid common mode failures ( i.e., correlated faults), it helps if each replica could execute a different version of the system code. This strategy is referred to as n-version programming [1]. Program transformation may also be used to achieve diversified replicas with lower software development cost [4]. A special form of n-version programming appears in the recovery block method for software fault tolerance [8]. Instead of using different versions of the software in different replicas, each module of the system is equipped with a main version and one or more alternate versions. At the end of the execution of the main version, an acceptance test is evaluated. If the testing fails, the first alternate version is executed and the acceptance test is evaluated again. This goes on until all alternate versions have been exhausted, in which case, the module returns an error.
1.3 System Security
For a system to be trustworthy, it must be both dependable and secure. Traditionally, dependable computing and secure computing have been studied by two disjoint communities [2]. Only relatively recently, the two communities started to collaborate and exchange ideas, as evidenced by the creation of a new IEEE Transactions on Dependable and Secure Computing in 2004. Traditionally, security means the protection of assets [7]. When the system is the asset to be protected, it includes several major components as shown in Figure 1.4:
◾ Operation. A system is dynamic in that it is continuously processing messages and changing its state. The code as well as the execution environment must be protected from malicious attacks, such as the buffer-overflow attacks.
◾ System state. The system state refers to that in the memory, and it should not be corrupted due to failures or attacks.
◾ Persistent state. System state could be lost if the process crashes and if the process is terminated. Many applications would use files or database systems to store critical system state into stable storage.
◾ Message. In a distributed system, different processes communicate with each other via messages. During transit, especial when over the public Internet, the message might be corrupted. An adversary might also inject fake messages to the system. A corrupted message or an injected message must be rejected.
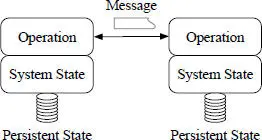
Figure 1.4 Main types of assets in a distributed system.
When we say a system is secure, we are expecting that the system exhibits three attributes regarding how its assets are protected [2]: (1) confidentiality, (2) integrity, and (3) availability. Confidentiality refers to the assurance that the system never reveals sensitive information (system state or persistent state) to unauthorized users. The integrity means that the assets are intact, and any unauthorized modification to the assets, be it the code, virtual memory, state, or message, can be detected. Furthermore, messages must be authenticated prior to being accepted, which would prevent fake messages from being injected by adversaries. The interpretation of availability in the security context is quite different from that in the dependable computing context. Availability here means that the asset is accessible to authorized users. For example, if someone encrypted some data, but lost the security key for decryption, the system is not secure because the data would no longer be available for anyone to access. When combining with dependable computing and in the system context, availability is morphing into that defined by the dependable computing community, that is, the system might be up and running, and running correctly so that an authorized user could access any asset at any time.
An important tool to implement system security is cryptography [11]. Put simply, cryptography is the art of designing ciphers, which scrambles a plaintext in such a way that its meaning is no longer obvious ( i.e., the encryption process) and retrieves the plaintext back when needed ( i.e., the decryption process). The encrypted text is often called cipher text. Encryption is the most powerful way of ensuring confidentiality and it is also the foundation for protecting the integrity of the system. There are two types of encryption algorithms, one is called symmetric encryption, where the same security key is used for encryption and decryption (similar to household locks where the same key is used to lock and unlock), and the other one is called asymmetric encryption, where one key is used to encrypt and a different key is used to decrypt. For symmetric encryption, key distribution is a challenge in a networked system because the same key is needed to do both encryption and decryption. The asymmetric encryption offers the possibility of making the encryption key available to anyone who wishes to send an encrypted message to the owner, as long as the corresponding decryption key is properly protected. Indeed, asymmetric encryption provides the foundation for key distribution. The encryption key is also called the public key because it can be made publicly available without endangering the system security, and the decryption key is called the private key because it must remain private, i.e., the loss of the private key will cripple the security of the entire system if built on top of asymmetric encryption. To further enhance the security of key distribution, a public-key infrastructure is established so that the ownership of the public key can be assured by the infrastructure.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.