Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
1.1.3.2 Reliability
Reliability is a measure of the system’s capability of providing correct services continuously for a period of time. It is often represented as the probability for the system to do so for a given period of time t , i.e., Reliability = R ( t ). The larger the t , the lower the reliability value. The reliability of a system is proportional to MTTF. The relationship between reliability and availability can be represented as 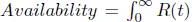 . Reliability is very different from availability. If a system fails frequently but can recover very quickly, the system may have high availability. However, such a system would have very low reliability.
. Reliability is very different from availability. If a system fails frequently but can recover very quickly, the system may have high availability. However, such a system would have very low reliability.
1.1.3.3 Integrity
Integrity refers to the capability of a system to protect its state from being compromised under various threats. In dependable computing research, integrity is typically translated into the consistency of server replicas, if redundancy is employed. As long as the number of faulty replicas does not exceed a pre-defined threshold, the consistency of the remaining replicas would naturally imply the integrity of the system.
1.1.3.4 Maintainability
Maintainability refers to the capability of a system to evolve after it is deployed. Once a software fault is detected, it is desirable to be able to apply a patch that repairs the system without having to uninstall the existing system and then reinstall an updated system. The same patching/software update mechanism may be used to add new features or improve the performance of the existing system. Ideally, we want to be able to perform the software update without having to shutdown the running system (often referred to as live upgrade or live update), which is already a standard feature for many operating systems for patching non-kernal level components. Live upgrade has also be achieved via replication in some distributed systems [12].
1.1.3.5 Safety
Safety means that when a system fails, it does not cause catastrophic consequences, i.e., the system must be fail-safe. Systems that are used to control operations that may cause catastrophic consequences, such as nuclear power plants, or endanger human lives, such as hospital operation rooms, must bear the safety attribute. The safety attribute is not important for systems that are not operating in such environments, such as for e-commerce.
1.2 Means to Achieve Dependability
There are two primary approaches to improving the dependability of distributed systems: (1) fault avoidance : build and use high quality software components and hardware that are less prone to failures; (2) fault detection and diagnosis: while crash faults are trivial to detect, components in a practical system might fail in various ways other than crash, and if not detected, the integrity of the system cannot be guaranteed; and (3) fault tolerance : a system is able to recover from various faults without service interruption if the system employs sufficient redundancy so that the system can mask the failures of a portion of its components, or with minimum service interruption if the system uses less costly dependability means such as logging and checkpointing.
1.2.1 Fault Avoidance
For software components, fault avoidance aims to ensure correct design specification and correct implementation before a distributed system is released. This objective can be achieved by employing standard software engineering practices, for example:
◾ More rigorous software design using techniques such as formal methods. Formal methods mandate the use of formal language to facilitate the validation of a specification.
◾ More rigorous software testing to identify and remove software bugs due to remnant design deficiency and introduced during implementation.
◾ For some applications, it may be impractical to employ formal methods, in which case, it is wise to design for testability [2], for example, by extensively use unit testing that is available in many modern programming languages such as Java and C#.
1.2.2 Fault Detection and Diagnosis
Fault detection is a crucial step in ensuring the dependability of a system. Crash faults are relatively trivial to detect, for example, we can periodically probe each component to check on its health. If no response is received after several consecutive probes, the component may be declared as having crashed. However, components in a system might fail in various ways and they might respond promptly to each probe after they have failed. It is nontrivial to detect such faults, especially in a large distributed system. Diagnosis is required to determine that a fault indeed has occurred and to localize the source of the fault ( i.e., pinpoint the faulty component). To accomplish this, the distributed system is modeled, and sophisticated statistical tools are often used [3]. Some of the approaches in fault detection and diagnosis are introduced in Chapter 3.
A lot of progress has been made in modern programming language design to include some forms of software fault detection and handling, such as unexpected input or state. The most notable example is exception handling. A block of code can be enclosed with a try-catch construct. If an error condition occurs during the execution of the code, the catch block will be executed automatically. Exceptions may also be propagated upward through the calling chain. If an exception occurs and it is not handled by any developer-supplied code, the language runtime usually terminates the process.
The recovery block method, which is designed for software fault tolerance [8], may be considered as an extension of the programming language exception handling mechanism. An important step in recovery blocks is the acceptance testing, which is a form of fault detection. A developer is supposed to supply an acceptance test for each module of the system. When the acceptance test fails, a software fault is detected. Subsequently, an alternate block of code is executed, after which the acceptance test is evaluated again. Multiple alternate blocks of code may be provided to increase the robustness of the system.
1.2.3 Fault Removal
Once a fault is detected and localized, it should be isolated and removed from the system. Subsequently, the faulty component is either repaired or replaced. A repaired or replaced component can be readmitted to the system. To accommodate these steps, the system often needs to be reconfigured. In a distributed system, it is often necessary to have a notion of membership, i.e., each component is aware of a list of components that are considered part of the system and their roles. When a faulty component is removed from the system, a reconfiguration is carried out and a new membership is formed with the faulty component excluded. When the component is repaired or replaced, and readmitted to the system, it becomes part of the membership again.
A special case of fault removal is software patching and updates. Software faults and vulnerabilities may be removed via a software update when the original system is patched. Virtually all modern operating systems and software packages include the software update capability.
1.2.4 Fault Tolerance
Robust software itself is normally insufficient to delivery high dependability because of the possibility of hardware failures. Unless a distributed system is strictly stateless, simply restarting the system after a failure would not automatically restore its state to what it had before the failure. Hence, fault tolerance techniques are essential to improve the dependability of distributed systems to the next level.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.