Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
4. M. Franz. Understanding and countering insider threats in software development. In Proceedings of the International MCETECH Conference on e-Technologies , pages 81–90, January 2008.
5. L. Lamport, R. Shostak, and M. Pease. The byzantine generals problem. ACM Transactions on Programming Languages and Systems , 4:382–401, 1982.
6. P. M. Melliar-Smith and B. Randell. Software reliability: The role of programmed exception handling. In Proceedings of an ACM conference on Language design for reliable software , pages 95–100, New York, NY, USA, 1977. ACM.
7. C. P. Pfleeger, S. L. Pfleeger, and J. Margulies. Security in Computing (5th Ed.) . Pearson, 2015.
8. B. Randell and J. Xu. The evolution of the recovery block concept. In Software Fault Tolerance , pages 1–22. John Wiley & Sons Ltd, 1994.
9. J. Shore. Fail fast. IEEE Software , pages 21–25, September/October 2004.
10. A. S. Tanenbaum and M. V. Steen. Distributed Systems: Principles and Paradigms . Prentice Hall, 2nd edition, 2006.
11. A. S. Tanenbaum and D. J. Wetherall. Computer Networks (5th Ed.) . Pearson, 2010.
12. L. Tewksbury, L. Moser, and P. Melliar-Smith. Live upgrade techniques for corba applications. In New Developments in Distributed Applications and Interoperable Systems , volume 70 of IFIP International Federation for Information Processing , pages 257–271. Springer US, 2002.
2
Logging and Checkpointing
Checkpointing and logging are the most essential techniques to achieve dependability in distributed systems [7]. By themselves, they provide a form of fault tolerance that is relatively easy to implement and incurs low runtime overhead. Although some information could be lost (if only checkpointing is used) when a fault occurs and the recovery time after a fault is typically larger than that of more sophisticated fault tolerance approaches, it may be sufficient for many applications. Furthermore, they are used in all levels of dependability mechanisms.
A checkpoint of a distributed system refers to a copy of the system state [7]. If the checkpoint is available after the system fails, it can be used to recover the system to the state when the checkpoint was taken. Checkpointing refers to the action of taking a copy of the system state (periodically) and saving the checkpoint to a stable storage that can survive the faults tolerated.
To recover the system to the point right before it fails, other recovery information must be logged in addition to periodical checkpointing. Typically all incoming messages to the system are logged. Other nondeterministic events may have to be logged as well to ensure proper recovery.
Checkpointing and logging provide a form of rollback recovery [7] because they can recover the system to a state prior to the failure. In contrast, there exist other approaches that accomplish roll-forward recovery, that is, a failed process can be recovered to the current state by incorporating process redundancy into the system. However, roll-forward recovery protocols typically incur significantly higher runtime overhead and demand more physical resources.
2.1 System Model
In this section, we define the system model used in the checkpointing and logging algorithms introduced in this chapter. The algorithms are executed in a distributed system that consists of N number of processes. Processes within the system interact with each other by sending and receiving messages. These processes may also interact with the outside world by message exchanges. The input message to the distributed system from the outside world is often a request message sent by the user of the system. The output message from the system is the corresponding response message. An example distributed system consisting of 4 processes is shown in Figure 2.1.
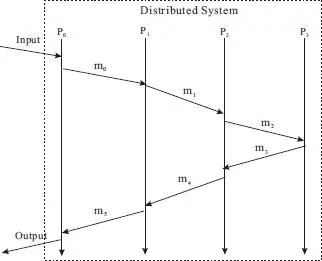
Figure 2.1 An example distributed system.
2.1.1 Fault Model
In such a distributed system, a failure could occur at a process. However, it is assumed that when a process fails, it simply stops execution and loses all its volatile state ( i.e., the fail-stop model [18] is used). In addition, it is assumed that any two processes can establish a reliable connection (such as a TCP connection) for communication. Even though the network may lose messages, the reliable channel can effectively mask such losses. Naturally, the reliable connection ensures the first-in first-out (FIFO) property between the two endpoints of the reliable connection. This assumption also implies that the network does not partition, i.e., it does not prevent two or more processes in the system from interacting with each other for extended period of time.
2.1.2 Process State and Global State
The state of an individual process is defined by its entire address space in an operating system. A generic checkpointing library (such as Condor [23]) normally saves the entire address space as a checkpoint of the process. Of course, not everything in the address space is interesting based on the application semantics. As such, the checkpoint of a process can be potentially made much smaller by exploiting application semantics.
The state of a distributed system is usually referred to as the global state of the system [5]. It is not a simple aggregation of the states of the processes in the distributed system because the processes exchange messages with each other, which means that a process may causally depend on some other processes. Such dependency must be preserved in a global state. Assume that each process in the distributed system takes checkpoints periodically, this implies that we may not be able to use the latest set of checkpoints for proper recovery should the processes fails, unless the checkpointing at different processes are coordinated [5]. To see why, considering the three scenarios illustrated in Figure 2.2where the global state is constructed by using the three checkpoints, C 0, C 1, C 2, taken at processes P 0, P 1, and P 2, respectively.
Figure 2.2(a)shows a scenario in which the checkpoints taken by different processes are incompatible, and hence cannot be used to recover the system upon a failure. Let’s see why. In this scenario, P 0sends a message m 0to P 1, and P 1subsequently sends a message m 1to P 2. Therefore, the state of P 2potentially depends on the state of P 1after it has received m 1, and the state of P 1may depend on that of P 0once it receives m 0. The checkpoint C 0is taken before P 0sends the message m 0to P 1, whereas the checkpoint C 1is taken after P 1has received m 0. The checkpoints are not compatible because C 1reflects the receiving of m 0while C 0does not reflect the sending of m 0, that is, the dependency is broken. Similarly, C 2reflects the receiving of m 1while C 1does not reflect the sending of m 1.
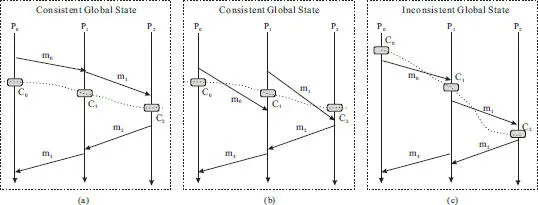
Figure 2.2 Consistent and inconsistent global state examples.
EXAMPLE 2.1
To understand the problem better, consider the following example. Assume that P 0and P 1represent two bank accounts, A and B respectively. The purpose of m 0is to deposite $100 to account B after P 0has debited account A . P 0takes a checkpoint C 0 before the debit operation, and P 1takes a checkpoint C 1 after it has received and processed the deposit request ( i.e., m 0), as illustrated in Figure 2.2(a). If P 0crashes after sending the deposit request ( m 0), and P 1crashes after taking the checkpoint C 1, upon recovery, P 1’s state would reflect a deposit of $100 (from account A ) while P 0’s state would not reflect the corresponding debit operation. Consequently, $100 would appear to have come from nowhere, which obviously is not what had happened. In essence, the global state constructed using the wrong set of checkpoints does not correspond to a state that could have happened since the initial state of the distributed system. Such a global state is referred to as an inconsistent global state.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.