Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
2.3.1 Pessimistic Logging
The most straightforward implementation of pessimistic logging is to synchronously log every incoming message to stable storage before it is executed at a process. Each process can checkpoint its state periodically at its own pace without the need to coordinate with other processes in the distributed system. Upon recovery from a failure, a process restores its state using the last checkpoint and replays all logged incoming messages to recover itself to the state right before it fails.
EXAMPLE 2.5
Consider the example shown in Figure 2.11. Process P 1crashes after sending message m 8. Process P 2crashes after sending message m 9. Upon recovery, P 1restores its state using the checkpoint C 1,0. Because it will be in the state interval initiated with the receiving of message m 0, messages m 2, m 4, and m 5will be deterministically regenerated. This should not be a problem because the receiving processes should have mechanism to detect duplicates. Subsequently, the logged message m 6is replayed, which triggers a new state interval in which m 8would be deterministically regenerated (and discarded by P 0. Similar, upon recovery, P 2restores its state using the checkpoint C 2,0. The restored state is in the state interval initiated by the receiving of m 1, and message m 3will be deterministically regenerated and sent to P 3. Again, P 3would detect that it is a duplicate and discard it. Furthermore, the logged messages m 4and m 7is replayed, causing the sending of messages m 6and m 9, which will be ignored by P 1and P 3.
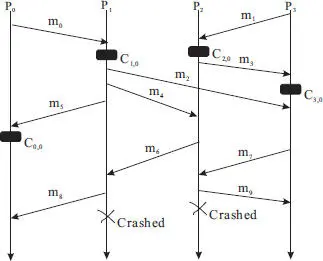
Figure 2.11 An example for pessimistic logging.
Pessimistic logging can cope with concurrent failing and recovery of two or more processes, as illustrated in the example shown in Figure 2.11. Messages received while a process is recovering ( i.e., while it is restoring its state using the latest checkpoint and by replaying all the logged messages), can be buffered and examined when the process completes its recovery. It is possible that while a process is engaging in a recovery, another process fails and recovers itself concurrently, as the above example shows. In this case, P 1would receive a duplicate message ( m 6) regenerated by another recovering process P 2and temporarily buffers it. P 1then would discard it as soon as it is done recovery. Similarly, P 2would receive the duplicate message m 4regenerated by P 1, which will be discarded after the recovery is completed.
2.3.1.1 Benefits of Pessimistic Logging.
It is apparent that pessimistic logging has a number of very desirable characteristics:
◾ Processes do not need to track their dependencies. The relative ordering of the incoming messages to each process is naturally reflected in the log (i.e., during recovery, the messages in the log will be replayed in the order in which they are logged). Hence, the pessimistic logging mechanism is straightforward to implement and less error prone.
◾ Output commit is free with pessimistic logging. This is a great fit for distributed applications that interact with their users frequently.
◾ There is no need to carry out coordinated global checkpointing because by replaying the logged messages, a process can always bring itself to be consistent with other processes in the system. This further reduces the complexity of adding rollback recovery support to applications. Furthermore, a process can decide when it is the best time to take a local checkpoint, for example, when its message log is too big.
◾ Recovery can be done completely locally to the failed processes. The only impact to other processes is the possibility of receiving duplicate messages and discard them. Hence, the recovery is simpler and in general faster than optimistic and causal logging. The localization of failure recovery also means that pessimistic logging supports concurrent failure recovery of multiple processes.
2.3.1.2 Discussion.
There are three issues that warrant additional elaboration: reconnection, message duplicate detection, and atomic message receiving and logging.
Reconnection. A process must be able to cope with temporary connection failures and be ready to accept reconnections from other processes. This is an essential requirement for recoverable distributed system. This calls for a design in which the application logic is independent from the transport level events. This can be achieved by using a event-based [8] or document-based distributed computing architecture such as Web services [15], in conjunction with appropriate exception handling.
Message duplicate detection. As mentioned above, a process must be capable of detecting duplicate messages because it may receive such messages replayed by another process during recovery. Even though transport-level protocols such as TCP have build-in mechanism to detect and discard duplicate messages, such mechanism is irrelevant because it works only within the established connection. During failure recovery, the recovering process will inevitably re-establish the connections to other processes, hence, such mechanism cannot be depend on. Furthermore, not all application-level protocols have duplicate detection support (they often depend on the underlying transport-level protocol to do so). In this case, the application-level protocol must be modified to add the capability of message duplicate detection. For XML-based protocols, such as SOAP [15], it is straightforward to do so by introducing an additional header element that carries a tuple, where the sender-id is a unique identifier for the sending process and sequence-number is the sequence number of the message issued by the sending process. The sequence number establishes the order in which the message is sent by a process Pi to another process Pj . It must start from an initial sequence number (assigned to the first message sent) known to both processes and continuously incremented for each additional message sent without any gap. The Web Services Reliable Messaging standard [6] specifies a protocol that satisfies the above requirement.
Atomic message receiving and logging. In the protocol description, we implicitly assumed that the receiving of a message and the logging of the same message are carried out in a single atomic operation. Obviously the use of a reliable communication channel alone does not warrant such atomicity because the process may fail right after it receives a message but before it could successfully log the message, in which case, the message could be permanently lost. This issue is in fact a good demonstration of the end-to-end system design argument [17]. To ensure the atomicity of the message receiving and logging, additional application-level mechanism must be used. (Although the atomic receiving and logging can be achieved via special hardware [4], such solution is not practical for most modern systems.)
As shown in Figure 2.12(a), a reliable channel only ensures that the message sent is temporarily buffered at the sending side until an acknowledgement is received in the transport layer. The receiving side sends an acknowledgement as soon as it receives the message in the transport layer. The receiving side buffers the message received until the application process picks up the message. If the application process at the receiving side fails either before it picks up the message, or before it completes logging the message in stable storage, the sending side would receive no notification and the message sent is no longer available.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.