Wenbing Zhao - From Traditional Fault Tolerance to Blockchain
Здесь есть возможность читать онлайн «Wenbing Zhao - From Traditional Fault Tolerance to Blockchain» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:From Traditional Fault Tolerance to Blockchain
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
From Traditional Fault Tolerance to Blockchain: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «From Traditional Fault Tolerance to Blockchain»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
This book intentionally includes traditional fault tolerance techniques so that readers can appreciate better the huge benefits brought by the blockchain technology and why it has been touted as a disruptive technology, some even regard it at the same level of the Internet. This book also expresses a grave concern on using traditional consensus algorithms in blockchain because with the limited scalability of such algorithms, the primary benefits of using blockchain in the first place, such as decentralization and immutability, could be easily lost under cyberattacks.
From Traditional Fault Tolerance to Blockchain — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «From Traditional Fault Tolerance to Blockchain», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Furthermore, in the original sender-based message logging protocol [13] , the regular message and the ordering message must be retransmitted after a timeout before the expected acknowledgment message is received. With the use of reliable channels, such proactive retransmission becomes unnecessary because the only scenario in which a retransmission is necessary is when a process fails, in which case, the retransmission will be triggered by the recovery mechanism (more in section 2.3.2.3).
The use of a mature reliable communication protocol such as TCP in distributed applications is more desirable because the application developers can focus on the application logic and application-level messaging reliability without worrying about issues such as achieving high throughput and doing congestion control.
EXAMPLE 2.6
In the example shown in Figure 2.18, the distributed system consists of three processes. Both the seq counter and rsn counter are initialized to be 0, and the message log is empty at each process. Process P 0first sends a regular message, m 0>, to P 1. Upon sending the message, P 0increments its seq counter to 1 and log the message in its volatile buffer. At this point, the rsn value for the message is unknown, hence it is denoted as a question mark.
On receiving the regular message m 0>, P 1assigns the current rsn counter value, which is 0, to this message indicating its receiving order, increments its rsn counter to 1, and sends P 0an ORDER message m 0],0>. When P 0receives this ORDER message, it updates the entry in its message log to reflect the ordering number for message m 0, and sends an sc ack message, m 0]>, to P 1.
Once receiving the ACK message, P 1is permitted to send a regular message, m 1>, to P 2. The handling of the message and the corresponding ORDER and ACK messages are similar to the previous ones.
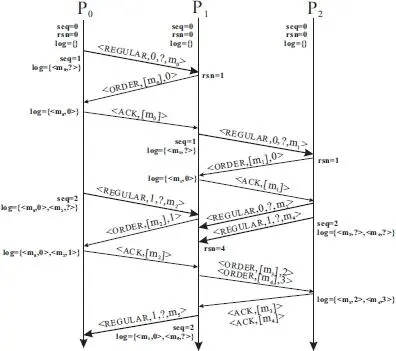
Figure 2.18 An example normal operation of the sender-based logging protocol.
Subsequently, P 0and P 2send three regular messages m 2, m 3, m 4, nearly concurrently to P 0. P 1assigns 1 as the rsn value for the first of the three messages (for m 2) and sends an ordering message to P 0, and assigns 2 and 3 for the two back-to-back regular messages (for m 3and m 4) from P 2. For the two messages from P 2, P 1can batch the ORDER messages and sends them together to P 2, and P 2can batch the corresponding the ACK messages to P 1too. Upon receiving the ACK messages for all three ORDER messages, P 1sends another regular message containing m 5with sequence number 1, updates the seq counter to 2, and log the message.
2.3.2.3 Recovery Mechanism.
On recovering from a failure, a process first restores its state using the latest local checkpoint, and then it must broadcast a request to all other processes in the system to retransmit all their logged messages that were sent to the process.
Because the checkpoint includes its message log, and the regular messages logged and the corresponding ACK messages might not reach their the destination processes due to the process failure, the recovering process retransmit the regular messages or the ack messages based on the following rule:
◾ If the entry in the log for a message contains no rsn value, then a REGULAR message is retransmitted because the intended receiving process might not have received this message.
◾ If the entry in the log for a message contains a valid rsn value, then an ACK message is sent so that the receiving process can send regular messages.
When a process receives a regular message, it always sends a corresponding ORDER message in response. There are three scenarios:
◾ The message is not a duplicate, in which case, the current rsn counter value is assigned to the message as its receiving order, and the corresponding ORDER message is sent. The process must then wait for the ACK message before it sends any regular message.
◾ The message is a duplicate, and the corresponding rsn value is found in its history list, in which case, an ORDER is message is sent and the duplicate message itself is discarded. The process must then wait for the ACK message before it sends any regular message. Note that it is impossible for the process to have received the corresponding ACK message before because otherwise the recovering process must have logged the rsn value for the regular message.
◾ The message is a duplicate, and there is no corresponding entry in the history list. In this case, the process must have checkpointed its state after receiving the message and it is no longer needed for recovery. As a result, the process sends an ORDER message with a special constant indicating that the message is no longer needed and the sending processing can safely purge the entry from its message log.
The recovering process may receive two types of retransmitted regular messages: (1) those with a valid rsn value, and (2) those without. Because the rsn counter is part of the state checkpointed, the recovering process knows which message is to be executed next. During the recovery, the process executes the retransmitted regular messages with valid rsn values according to the ascending rsn order. This ensures that these messages are replayed in exactly the same order as they were received prior to the failure. During the replay, the process may send regular messages to other processes. Such messages are logged at the recovering process as usual and they are likely to be duplicate. This is not a concern because of the duplicate detection mechanism in place and the duplicate message handling mechanism described above.
After replaying these messages, the process is recovered to a state that is visible to, and consistent with, other processes prior to the failure. For regular messages without rsn values, the recovering process can replay them in an arbitrary order because the process must not have sent any regular message since the receipt of such messages prior to its failure.
2.3.2.4 Limitations and Correctness.
The sender-based message logging protocol described above ensures proper recovery of a distributed system as long as a single failure occurs at a time. That is, after a process fails, no other processes fail until the failed process is fully recovered. Note that the protocol cannot cope with two or more concurrent failures. If two or more failures occur concurrently, the determinant for some regular messages ( i.e., the rsn values) might be lost, which would lead to orphan processes and the cascading rollback ( i.e., the domino effect).
EXAMPLE 2.7
Consider a distributed system consisting of three processes P 0, P 1, and P 2, shown in Figure 2.19. P 0sends P 1a regular message mi >. After the message is fully logged at P 0, P 1sends P 2a message mt >. Then, both P 0and P 1crashed. Upon recovery, although P 0can resend the regular message mi > to P 1, however, the receiving order information rsn is lost due the failures. Hence, it is not guaranteed that P 1could initiate the correct state interval that resulted in the sending of regular message mt >. P 2would become an orphan process and be forced to rollback its state.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «From Traditional Fault Tolerance to Blockchain»
Представляем Вашему вниманию похожие книги на «From Traditional Fault Tolerance to Blockchain» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «From Traditional Fault Tolerance to Blockchain» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.