Machine Learning Algorithms and Applications
Здесь есть возможность читать онлайн «Machine Learning Algorithms and Applications» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Machine Learning Algorithms and Applications
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Machine Learning Algorithms and Applications: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Machine Learning Algorithms and Applications»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Machine Learning Algorithms and Applications — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Machine Learning Algorithms and Applications», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
The resolution of the digital data that is fed into the CNN model is another reason to perform segment the background before the class of eggs is determined. The eggs are of the size around 32 × 32 pixels after scanning, while the entire sheet of silkworm eggs is of the size 5008 × 6984 pixels (in our experiment). If the entire sheet was fed to the CNN model with an input image size of 32 × 32 pixels with a sliding window method, then the model must classify 35M images that would be computationally expensive for a system without GPU support.
To overcome this issue, the FB CNN model was trained with an input data of 128 × 128 pixels, three-channel RGB image that was fed to the core CNN model, as shown in Figure 2.3, to provide categorical output using the softmax activation function. Some of the corresponding specifications of the FB CNN model are provided in Table 2.1along with accuracy scores. Using a 128 × 128 pixel input to the FB CNN model, the entire silkworm egg sheet is divided into square grids of 128 × 128 with a stride of 128, resulting in an image set of 2K images that must be processed for categorical results as foreground or background class. Figure 2.4represents the segmentation of the entire silkworm egg sheet, where the foreground (presence of egg) and background (absence of egg) are represented by a green color (pixels) and red color, respectively. Further processing is only carried out for pixels represented in green color that minimizes computational time and increase final accuracy as background pixels are dropped out of the data processing cycle.
Table 2.1 Specifications of foreground-background (FB) segmentation CNN model.
| Input image | Activation/output | Training samples | Test samples | Validation samples | Test loss | Accuracy on the test set | Accuracy on the validation set |
| 128 × 128 | SoftMax 2 class-(0/1) | 142 × 10 3 | 64.3 × 10 3 | 9.6 × 10 3 | 0.1242 | 96.1554% | 96.6422% |
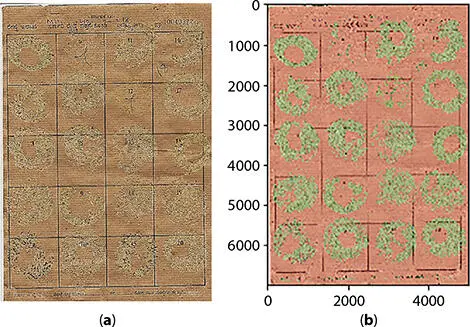
Figure 2.4 Foreground-background segmentation of entire silkworm egg sheet (a) (input) and (b) (output).
2.3.3 Egg Location Predictor
After segmentation of egg pixels from background pixels, the next step is to determine the location of the eggs. Many CNN models have been introduced such as Fast-RCNN [13] and YOLO [14] to predict the location of the object using the Intersect over Union method. There are two main reasons for not considering well-known techniques to locate the eggs. Firstly, in these methods the object/ROI dimensions are over 100 × 100, irregular in size, and the method has been trained for different bounding box dimensions. These techniques become unacceptable to determine the location of the egg, as the eggs have an average size of 28 × 28 pixels to 36 × 36 pixels. Moreover, the shape of the egg remains similar with minor deformation that can be neglected; hence, training for different dimension bounding box will not yield any good result. Secondly, these methods have the limitation of how many similar class objects can be recognized within a single bounding box, which are two objects for YOLO [14]. Since the eggs are small, many eggs will be present within a 100 × 100 grid image that may belong to the same class and hence may not be detected.
The specification of the egg location predictor CNN model is represented in Table 2.2, where the input to the core CNN model has been changed to 32 × 32 pixels, three-channel RGB image. Here, the output is a regression that provides the location of the egg center ( x, y ) rather than a bounding box (four corner points). The training dataset consists of both the class images, i.e., hatched eggs and unhatched eggs. The positive samples consist of images where an individual egg is visible completely, while the negative samples consist of eggs that are partially visible and have multiple egg entries. Figure 2.5represents the classifier model that is trained to determine positive and negative samples, and the positive samples are later trained to predict the egg center location in terms of pixel values. Further, during the practical application, the center location of the egg predicted is used to crop a single egg data to be fed into a classifier that determines the class of the selected egg into HC or UHC. Figure 2.6represents an overall result of locating egg centers using egg location predictor CNN model for one of the test data sheets where all egg centers are marked with a blue dot. A sliding window of (32 × 32) with a stride of (4, 4) was used to achieve the results.
2.3.4 Predicting Egg Class
The sliding window method is used to generate input images, and a single egg may be represented by many image windows each of size 32 × 32. Euclidean distance equation,  , was used to select the egg center by combining all the egg location predictions that fall within a certain user-defined distance limit. ( x 1, y 1) and ( x 2, y 2) are the reference pixel and pixel under consideration. Since the egg diameter is well within the range of 28 to 32 pixels, a distance limit is set that is equal to the radius of the egg, i.e., 16 pixels. Any center locations that fall within this limit are considered to be representing same egg and hence combined to generate single egg location that can be then cropped by using Equations (2.4)to (2.7), where ( xa, ya ) are the resulting egg location after averaging all predicted egg locations that fall within distance limits. ( x, y ) pixel is the original location while w, h represents the width and height of the image to be cropped that is equal to 32 pixels. The resulting images are fed into the egg class predictor CNN model, which provides categorical data to distinguish the input image into class HC or UHC. The specification of the egg class predictor CNN model is represented in Table 2.3.
, was used to select the egg center by combining all the egg location predictions that fall within a certain user-defined distance limit. ( x 1, y 1) and ( x 2, y 2) are the reference pixel and pixel under consideration. Since the egg diameter is well within the range of 28 to 32 pixels, a distance limit is set that is equal to the radius of the egg, i.e., 16 pixels. Any center locations that fall within this limit are considered to be representing same egg and hence combined to generate single egg location that can be then cropped by using Equations (2.4)to (2.7), where ( xa, ya ) are the resulting egg location after averaging all predicted egg locations that fall within distance limits. ( x, y ) pixel is the original location while w, h represents the width and height of the image to be cropped that is equal to 32 pixels. The resulting images are fed into the egg class predictor CNN model, which provides categorical data to distinguish the input image into class HC or UHC. The specification of the egg class predictor CNN model is represented in Table 2.3.
(2.4) 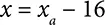
(2.5) 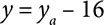
(2.6) 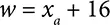
(2.7) 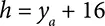
Table 2.2 Specifications of egg location CNN model.
| Input image | Activation/output | Training samples | Test samples | Validation samples | Test loss | Validation loss |
| 32 × 32 | Regression Center of the egg ( x, y ) | 439 × 10 3 | 51.6 × 10 3 | 25.8 × 10 3 | 0.5488 | 0.5450 |
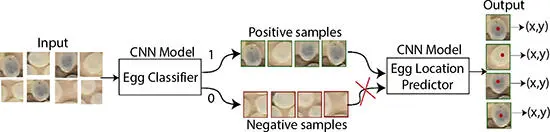
Figure 2.5 CNN training model to predict egg location in terms of pixel values.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Machine Learning Algorithms and Applications»
Представляем Вашему вниманию похожие книги на «Machine Learning Algorithms and Applications» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Machine Learning Algorithms and Applications» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.