Machine Learning Algorithms and Applications
Здесь есть возможность читать онлайн «Machine Learning Algorithms and Applications» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Machine Learning Algorithms and Applications
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Machine Learning Algorithms and Applications: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Machine Learning Algorithms and Applications»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Machine Learning Algorithms and Applications — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Machine Learning Algorithms and Applications», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
According to a survey mentioned in [9], pollution levels in many cities across the country reduced down drastically only after a few days of imposing lockdown. Also, as discussed in the study [10], lockdown could be the effective alternative measure to be implemented for controlling air pollution.
The results above show us that all these machine learning techniques can be used for prediction and evaluating air pollution thereafter. Implementation details are described in the next section.
1.3 Implementation Details
There are several paradigms that can be implemented to classify the quality of air. The novelty of the application is to predict the future air quality of different places in detail with estimated values of various parameters along with its air quality and AQI. The application is able to visualize data in an efficient and descriptive way which is hard to analyze numerically in its raw form.
1.3.1 Proposed Methodology
Our proposed methodology steps have been discussed as follows:
1. Fetch real-time air quality data through an API of Open Data.
2. Clustering of air quality data based on AQI and assigning classes of air quality from good to severe.
3. Train a Support Vector Machine (SVM) model on the previously clustered data.
4. Train different time series Long Short-Term Memory (LSTM), a Recurrent Neural Network (RNN) model for different places to predict the future air quality of that place based on the previous trend.
5. Assign air quality and AQI to the observed/predicted values of the parameters. AQI is assigned based on the worst 24-hour average of all the parameters.
6. Different visualizations of the past data and future predictions using Heat Maps, Graphs, etc.
7. Compare variations in different parameters contributing toward air pollution at different places.
8. Provide a user-friendly web app to predict and analyze air quality.
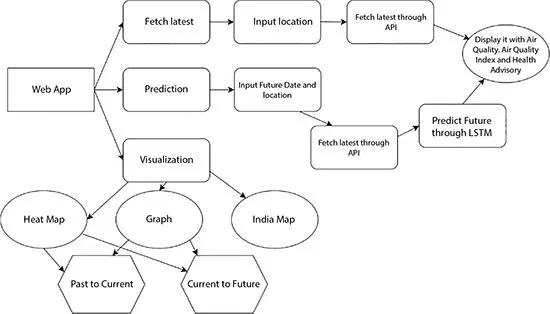
Figure 1.1 Workflow of the application.
Figure 1.1shows the detailed description of the working of the application. The latest data for specific location/place is fetched using Restful API in JSON format from the Open Data Repository. Prediction is also done for the future air quality using the past values. The predicted data is displayed with an adequate message through the web app to the user. Visualization involved displaying the results in human understandable format. For that, Heat Maps were generated and appropriate messages were displayed based on the WHO guidelines. The results were also displayed through graphs to show connectivity between different values. Finally, the outputs were also displayed on the Indian map.
1.3.2 System Specifications
Main hardware requirements are high computational power CPU such as an i5/i7 Intel processor or equivalent. The system must be able to fulfill both primary and secondary high memory requirements approximately around 50-GB HDD and 4–8 GB of RAM. Main software requirements consist of any open source operating system, Python language with dependencies like scikit-learn, and other packages and libraries like pandas, numpy, matplotlib, bokeh, flask, tensorflow, and theano.
1.3.3 Algorithms
1. K-Means Clustering: The K-means algorithm takes a set of input values and, based on parameter k, clusters the values into k clusters. The division of values into k clusters is based on a similarity index in which data values having close similarity index are grouped into one cluster and another set of values is grouped into another cluster [11]. Distance measures like Euclidean, Manhattan, and Minkowski are some of the similarity indices that are used for clustering. We have used clustering because our dataset values were to be divided into classes. We choose six classes, viz., Good, Satisfactory, Moderately Polluted, Poor, Very Poor, and Severe.
2. Support Vector Machine Algorithm (SVMA) for Prediction: SVMAs are an age old excellent algorithms in use for solving classification and regression problems. SVM provides a supervised learning model and is used to analyze the patterns in the data. In SVM, a linear model is applied to convert non-linear class boundaries to linear classes. This is done by reducing the high-dimensional feature vector space. Kernel selection is an integral part of SVMs. Different kernels exist and we have used linear and Radial Basis Function (RBF) for our experiments. The outputs have been discussed under results. Two major kinds of SVM considered are therefore linear-based modeling and non-linear based modeling.
3. Recurrent Neural Network LSTM Algorithm (LSTM-RNN): Contemporary Neural Networks such as Feed Forward Neural Networks (FFNNs) are different from Recurrent Neural Networks (RNNs) because they are trained on labeled data and forward feed is used till prediction error gets minimized.
RNNs are different from FFNNs because the output or result received at stage t − 1 impacts the output or result received at stage t . In RNN, there are two input values: first one being the present input value and second one being the recent past value. Both inputs are used to compute the new output.
Figure 1.2shows the simple form of RNN. For a hidden state (h t) which is non-linear transformation in itself, it can be computed using a combination of linear input value (I t) and recent hidden past value (h t− 1). From the figure, it can be observed that the output result is computable using the present dependent hidden state h t. The output O tholds dependence on probability p twhich was computed using a function called softmax. Softmax was only computed in the last layer of RNN-based classification before the final result was received.
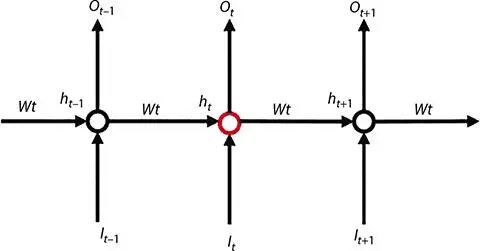
Figure 1.2 Basic steps of recurrent neural network.
Since RNN in itself suffers from two gradient problems of vanishing gradients and exploding gradients, therefore there have been two modifications to the basic RNN. Gates have been provided to control the impact of the multiplying factor that is majorly responsible for increase (explosion) in gradient (multiplying factor if larger than one) or decrease (vanishing) in gradient (multiplying factor if less than one). We now have LSTM and Gated Recurrent Unit (GRU). LSTM has been used in our work [12].
Because we were trying to predict future values based on present and past pollution data values that were in time series and had lags, therefore LSTM suited our use case. LSTM learns from the historical data to not only classify but also to process the results and predict the future scores without getting affected by gradient incumbencies.
1.3.4 Control Flow
In terms of control flow, the working of our model can be explained with respect to training model and testing model:
1. Training Model: As the first step of the training model, the data is fetched from the OpenAQ Open Data Community and is pre-processed to remove any kind of noise from the data. The cleaned world data is passed for K-means clustering. Before setting the number of clusters required to classify the data we measured Silhouette coefficient to determine the optimal number of clusters required. On the second hand, the cleaned single place data is passed to the LSTM for different places. The output of the world data clustering and LSTM training of single place data is passed to measure the performance using MAE and RMSE values. Also, the world data after clustering is assigned labels using the AQI table. The labeled data is then split into testing data and training data. SVM training is done with values of parameters as input and air quality as output. At the end, 10-fold cross-validations were done and performances were measured using confusion matrix, precision and recall parameters.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Machine Learning Algorithms and Applications»
Представляем Вашему вниманию похожие книги на «Machine Learning Algorithms and Applications» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Machine Learning Algorithms and Applications» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.