Yong Chen - Industrial Data Analytics for Diagnosis and Prognosis
Здесь есть возможность читать онлайн «Yong Chen - Industrial Data Analytics for Diagnosis and Prognosis» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Industrial Data Analytics for Diagnosis and Prognosis
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Industrial Data Analytics for Diagnosis and Prognosis: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Industrial Data Analytics for Diagnosis and Prognosis»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
In
, distinguished engineers Shiyu Zhou and Yong Chen deliver a rigorous and practical introduction to the random effects modeling approach for industrial system diagnosis and prognosis. In the book’s two parts, general statistical concepts and useful theory are described and explained, as are industrial diagnosis and prognosis methods. The accomplished authors describe and model fixed effects, random effects, and variation in univariate and multivariate datasets and cover the application of the random effects approach to diagnosis of variation sources in industrial processes. They offer a detailed performance comparison of different diagnosis methods before moving on to the application of the random effects approach to failure prognosis in industrial processes and systems.
In addition to presenting the joint prognosis model, which integrates the survival regression model with the mixed effects regression model, the book also offers readers:
A thorough introduction to describing variation of industrial data, including univariate and multivariate random variables and probability distributions Rigorous treatments of the diagnosis of variation sources using PCA pattern matching and the random effects model An exploration of extended mixed effects model, including mixture prior and Kalman filtering approach, for real time prognosis A detailed presentation of Gaussian process model as a flexible approach for the prediction of temporal degradation signals Ideal for senior year undergraduate students and postgraduate students in industrial, manufacturing, mechanical, and electrical engineering,
is also an indispensable guide for researchers and engineers interested in data analytics methods for system diagnosis and prognosis.
Industrial Data Analytics for Diagnosis and Prognosis — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Industrial Data Analytics for Diagnosis and Prognosis», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
3 Random Vectors and the Multivariate Normal Distribution
Informally, a random variable can be described as a variable whose value depends on the outcome of a random or chance phenomenon. Some examples of random variables are: the highway MPG of a new car randomly sampled from all cars on sale, the quality measurement of a product randomly sampled from a production line, the temperature measurement at a particular moment and location of a machine where temperature randomly varies over time. Due to the ubiquitous uncertainty and variation existing in industrial systems and processes, most variables of interest in industrial data analytics applications can be considered as random variables. Many industrial data analytics problems involve multiple random variables, which form a vector of random variables, also called as a random vector. In this chapter, we study the concept of random vectors and the multivariate normal distribution, the most commonly used model for a random vector.
3.1 Random Vectors
A random vector is a vector of random variables. Let X=(X1 X2 . . . Xp)T denote a random vector. The mean or expected value of a random vector is the vector of the mean values of each of its elements. The mean vector of Xcan be written as
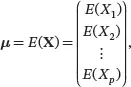
where the univariate mean is defined as
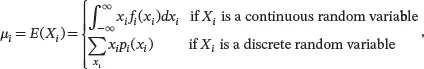
where fi ,( xi ) is the probability density function of Xi if Xi is continuous and pi ( Xi is the probability mass function of Xi if Xi is discrete. The µi is also called the population mean of Xi because it is the mean of Xi over all possible values in the population. Similarly, the mean vector µ is the population mean vector of X.
To further explain the relationship and difference between the population mean and the sample mean introduced in Section 2.2, we first consider a univariate random variable X and its population mean μ . Consider a random sample of observations from the population, say, X 1, X 2,…, Xn . The sample mean 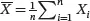 is a random variable because the observations X 1, X 2,…, Xn are all random variables with values varying from sample to sample. For example, let X represent the measured intensity of the current of a wafer produced by a semiconductor manufacturing process. Then we take a random sample of n = 10 wafers from this process and compute the sample mean of the measured intensities of the current and get the result x̄ = 1.02. Now we repeat this process, taking a second sample of n = 10 wafers from the same process and the resulting sample mean is 1.04. The sample means differ from sample to sample because they are random variables. Consequently, the sample mean, and any other function of the random observations, is a random variable. On the other hand, the population mean µ does not depend on the samples and is a (usually unknown) constant. When we take a sample with very large sample size n , the sample mean will be very close to the population mean µ with high probability. As the sample mean X̄ is a random variable, we can evaluate its mean and variance. It is easy to see that E ( X̄ ) = µ and var ( X̄ ) = σ 2/ n , where β 2is the variance of X . An estimator of a parameter is called unbiased if its mean is equal to the true value of the parameter. X̄ is a commonly used estimator of µ because it is unbiased and has a smaller variance for a larger sample size n .
is a random variable because the observations X 1, X 2,…, Xn are all random variables with values varying from sample to sample. For example, let X represent the measured intensity of the current of a wafer produced by a semiconductor manufacturing process. Then we take a random sample of n = 10 wafers from this process and compute the sample mean of the measured intensities of the current and get the result x̄ = 1.02. Now we repeat this process, taking a second sample of n = 10 wafers from the same process and the resulting sample mean is 1.04. The sample means differ from sample to sample because they are random variables. Consequently, the sample mean, and any other function of the random observations, is a random variable. On the other hand, the population mean µ does not depend on the samples and is a (usually unknown) constant. When we take a sample with very large sample size n , the sample mean will be very close to the population mean µ with high probability. As the sample mean X̄ is a random variable, we can evaluate its mean and variance. It is easy to see that E ( X̄ ) = µ and var ( X̄ ) = σ 2/ n , where β 2is the variance of X . An estimator of a parameter is called unbiased if its mean is equal to the true value of the parameter. X̄ is a commonly used estimator of µ because it is unbiased and has a smaller variance for a larger sample size n .
This concept can be extended to a p -dimensional random vector Xwith mean vector µ . Consider a random sample X 1, X 2,…, X n from the population of X. The sample mean vector X̄is a random vector with population mean E ( X̄) = µand population covariance matrix 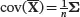 , where Σis the population covariance matrix of X. The population covariance matrix is defined shortly. The sample mean vector X̄is an unbiased estimator of the population mean vector μ.
, where Σis the population covariance matrix of X. The population covariance matrix is defined shortly. The sample mean vector X̄is an unbiased estimator of the population mean vector μ.
The (population) covariance matrix of a random vector Xis defined as
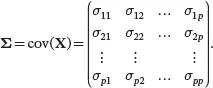
The i th diagonal element of Σis the population variance of X i:
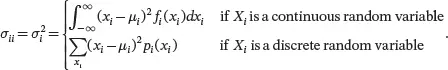
The ( j , k )th off-diagonal element of Σis the population covariance between Xj and Xk :
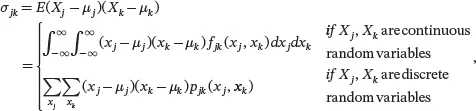
where fjk ( xj , xk ) and pjk ( xj , xk ) are the joint density function and joint probability mass function, respectively, of Xj and Xk . The population covariance measures the linear association between the two random variables. It is clear that σ i = σ kj and the covariance matrix Σis symmetric. The same as the sample covariance matrix, the population covariance matrix Σis always positive semidefinite.
Similar to the population mean, the population variance and covariance can be estimated by the sample variance and covariance introduced in Section 2.2. The sample variance and covariance are both random variables, and are unbiased estimators of the population variance and covariance. Consequently, the sample covariance matrix Sis an unbiased estimator of the population covariance matrix Σ, that is, E ( S) = Σ.
As for the sample covariance, the value of the population covariance of two random variables depends on the scaling, possibly due to the difference of measuring unit of the variables. A scaling-independent measure of the degree of linear association between the random variables Xj and Xk is given by the population correlation:
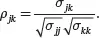
It is clear that ρjk = ρkj . And the population correlation matrix of a random vector Xis a symmetric matrix defined as
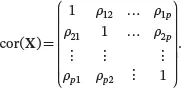
For univariate variables X and Y and a constant c , we have E ( X + Y ) = E ( X ) + E ( Y ) and E ( cX ) = cE ( X ). Similarly, for random vectors Xand Yand a constant matrix C, it can be seen that
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Industrial Data Analytics for Diagnosis and Prognosis»
Представляем Вашему вниманию похожие книги на «Industrial Data Analytics for Diagnosis and Prognosis» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Industrial Data Analytics for Diagnosis and Prognosis» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.