Yong Chen - Industrial Data Analytics for Diagnosis and Prognosis
Здесь есть возможность читать онлайн «Yong Chen - Industrial Data Analytics for Diagnosis and Prognosis» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Industrial Data Analytics for Diagnosis and Prognosis
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Industrial Data Analytics for Diagnosis and Prognosis: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Industrial Data Analytics for Diagnosis and Prognosis»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
In
, distinguished engineers Shiyu Zhou and Yong Chen deliver a rigorous and practical introduction to the random effects modeling approach for industrial system diagnosis and prognosis. In the book’s two parts, general statistical concepts and useful theory are described and explained, as are industrial diagnosis and prognosis methods. The accomplished authors describe and model fixed effects, random effects, and variation in univariate and multivariate datasets and cover the application of the random effects approach to diagnosis of variation sources in industrial processes. They offer a detailed performance comparison of different diagnosis methods before moving on to the application of the random effects approach to failure prognosis in industrial processes and systems.
In addition to presenting the joint prognosis model, which integrates the survival regression model with the mixed effects regression model, the book also offers readers:
A thorough introduction to describing variation of industrial data, including univariate and multivariate random variables and probability distributions Rigorous treatments of the diagnosis of variation sources using PCA pattern matching and the random effects model An exploration of extended mixed effects model, including mixture prior and Kalman filtering approach, for real time prognosis A detailed presentation of Gaussian process model as a flexible approach for the prediction of temporal degradation signals Ideal for senior year undergraduate students and postgraduate students in industrial, manufacturing, mechanical, and electrical engineering,
is also an indispensable guide for researchers and engineers interested in data analytics methods for system diagnosis and prognosis.
Industrial Data Analytics for Diagnosis and Prognosis — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Industrial Data Analytics for Diagnosis and Prognosis», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
3.4 Hypothesis Testing on Mean Vectors
In this section, we study how to determine if the population mean μis equal to a specific value μ 0when the observations follow a normal distribution. We start by reviewing the hypothesis testing results for univariate data. Suppose X 1, X 2,…, Xn are a random sample of independent univariate observations following the normal distribution N ( μ , σ 2). The test on μ is formulated as
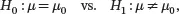
where H 0is the null hypothesis and H 1is the (two-sided) alternative hypothesis. For this test, we use the following test statistic:
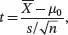 (3.18)
(3.18)
where X̄ is the sample mean 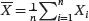 and s 2is the sample variance
and s 2is the sample variance 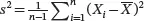 . The sample mean X̄ follows N ( μ , σ 2/ n ) and ( n − 1) s 2/σ 2follows a χ 2distribution with n − 1degrees of freedom. Consequently, under H 0the t statistic in ( 3.18) follows a Student’s t -distribution with n − 1degrees of freedom. We reject H 0at significance level α and conclude that μ is not equal to μ 0if | t |> t α/2,n−1, where t α/2,n−1denotes the upper 100( α /2)th percentile of the t -distribution with n − 1 degrees of freedom. Intuitively, | t |> t α/2,n−1indicates that we only have a small probability to observe | t | if we sample from the Student’s t -distribution with n − 1 degrees of freedom. Thus, it is very likely the null hypothesis H 0is not correct and we should reject H 0.
. The sample mean X̄ follows N ( μ , σ 2/ n ) and ( n − 1) s 2/σ 2follows a χ 2distribution with n − 1degrees of freedom. Consequently, under H 0the t statistic in ( 3.18) follows a Student’s t -distribution with n − 1degrees of freedom. We reject H 0at significance level α and conclude that μ is not equal to μ 0if | t |> t α/2,n−1, where t α/2,n−1denotes the upper 100( α /2)th percentile of the t -distribution with n − 1 degrees of freedom. Intuitively, | t |> t α/2,n−1indicates that we only have a small probability to observe | t | if we sample from the Student’s t -distribution with n − 1 degrees of freedom. Thus, it is very likely the null hypothesis H 0is not correct and we should reject H 0.
The test based on a fixed significance level α , say α = 0.05, has the disadvantage that it gives the decision maker no idea about whether the observed value of the test statistic is just barely in the rejection region or if it is far into the region. Instead, the p -value can be used to indicate how strong the evidence is in rejecting the null hypothesis H 0. The p -value is the probability that the test statistic will take on a value that is at least as extreme as the observed value when the null hypothesis is true. The smaller the p -value, the stronger the evidence we have in rejecting H 0. If the p -value is smaller than α , H 0will be rejected at the significance level of α . The p -value based on the t statistic in ( 3.18) can be found as
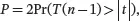
where T ( n − 1) denotes a random variable following a t distribution with n − 1 degrees of freedom.
We can define the 100(1 − α )% confidence interval for μ as
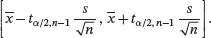
It is easy to see that the null hypothesis H 0is not rejected at level α if and only if μ 0is in the 100(1 − α )% confidence interval for μ . So the confidence interval consists of all those “plausible” values of μ 0that would not be rejected by the test of H 0at level α .
To see the link to the test statistic used for a multivariate normal distribution, we consider an equivalent rule to reject H 0, which is based on the square of the t statistic:
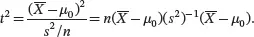 (3.19)
(3.19)
We reject H 0at significance level α if t 2>( t α/2,n−1) 2.
For a multivariate distribution with unknown mean μand known Σ, we consider testing the following hypotheses:
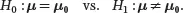 (3.20)
(3.20)
Let X 1, X 2,…, X ndenote a random sample from a multivariate normal population. The test statistic in ( 3.19) can be naturally generalized to the multivariate distribution as
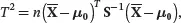 (3.21)
(3.21)
where X̄and Sare the sample mean vector and the sample covariance matrix of X 1, X 2,…, X n. The T 2statistic in ( 3.19) is called Hotelling’s T 2in honor of Harold Hotelling who first obtained its distribution. Assuming H 0is true, we have the following result about the distribution of the T 2-statistic:
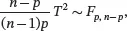
where Fp,n−p denotes the F -distribution with p and n − p degrees of freedom. Based on the results on the distribution of T 2, we reject H 0at the significance level of α if
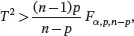 (3.22)
(3.22)
where Fp,n−p denotes the upper (100 α )th percentile of the F -distribution with p and n − p degrees of freedom. The p -value of the test based on the T 2-statistic is
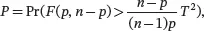
where F ( p , n − p ) denotes a random variable distributed as F p,n−p.
The T 2statistic can also be written as
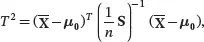
which can be interpreted as the standardized distance between the sample mean X̄and μ0. The distance is standardized by S/ n , which is equal to the sample covariance matrix of X̄. When the standardized distance between X̄and μ0is beyond the critical value given in the right-hand side of ( 3.22), the true mean is not likely equal to be μ0and we reject H 0.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Industrial Data Analytics for Diagnosis and Prognosis»
Представляем Вашему вниманию похожие книги на «Industrial Data Analytics for Diagnosis and Prognosis» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Industrial Data Analytics for Diagnosis and Prognosis» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.