Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
3.Repite los pasos 1-2 k veces.
4.Añade la predicción para cada árbol para asignar la etiqueta de clase por mayoría de votos. La mayoría de votos será tratada con más detalle en el Capítulo 7, Combinar diferentes modelos para un aprendizaje conjunto.
Debemos tener en cuenta una ligera modificación en el paso 2 cuando estemos entrenando los árboles de decisión individuales: en lugar de evaluar todas las características para determinar la mejor división para cada nodo, solo consideraremos un subconjunto al azar de ellos.
 |
 |
Si no estás familiarizado con los términos de muestreo con y sin reemplazo, vamos a realizar un simple experimento mental. Supongamos que jugamos a un juego de lotería donde extraemos al azar números de una urna. Empezamos con una urna que contiene cinco únicos números (0, 1, 2, 3 y 4) y sacamos exactamente un número cada vez. En el primer turno, la probabilidad de extraer un número en concreto de la urna sería de 1/5. Ahora bien, en muestreo sin reemplazo no devolvemos el número a la urna después de cada turno. En consecuencia, la probabilidad de extraer un número en concreto del conjunto de los números restantes en la siguiente ronda depende de la ronda anterior. Por ejemplo, si tenemos un conjunto de números 0, 1, 2 y 4, la oportunidad de extraer el número 0 pasa a ser de 1/4 en la siguiente ronda.Sin embargo, en el muestreo aleatorio con reemplazo siempre devolvemos el número extraído a la urna, por lo que las probabilidades de extraer un número en concreto en cada turno no cambian; podemos extraer el mismo número más de una vez. En otras palabras, en el muestreo con reemplazo las muestras (números) son independientes y tienen una covarianza de cero. Por ejemplo, los resultados de cinco rondas de extracción de números al azar serían como los siguientes:•Muestreo aleatorio sin reemplazo: 2, 1, 3, 4, 0•Muestreo aleatorio con reemplazo: 1, 3, 3, 4, 1 |  |
Aunque los bosques aleatorios no ofrecen el mismo nivel de interpretabilidad que los árboles de decisión, sí poseen la gran ventaja de que no debemos preocuparnos demasiado de elegir unos buenos valores de hiperparámetro. Normalmente no es necesario podar el bosque aleatorio, puesto que el modelo conjunto es bastante robusto ante el ruido de los árboles de decisión individuales. El único parámetro que debemos tener en cuenta a la práctica es el número de árboles k (paso 3) que elegimos para el bosque aleatorio. Habitualmente, cuanto más alto es el número de árboles mejor es el rendimiento del bosque aleatorio a expensas de un mayor coste computacional.
Aunque es menos común, otros hiperparámetros del clasificador de bosque aleatorio que pueden ser optimizados –mediante técnicas que trataremos en el Capítulo 5, Comprimir datos mediante la reducción de dimensionalidad– son el tamaño n de la muestra bootstrap (paso 1) y el número de características d que se elige aleatoriamente para cada división (paso 2.1). Mediante el tamaño de muestra n de la muestra bootstrap controlamos la compensación entre varianza y sesgo del bosque aleatorio.
Reducir el tamaño de la muestra bootstrap aumenta la diversidad entre los árboles individuales, puesto que la probabilidad de que una muestra de entrenamiento en concreto esté incluida en la muestra bootstrap es más baja. Así, contraer el tamaño de las muestras bootstrap aumenta la aleatoriedad del bosque aleatorio y esto puede ayudar a reducir el efecto de sobreajuste. Sin embargo, las muestras de bootstrap más pequeñas normalmente tienen como resultado un rendimiento general más bajo del bosque aleatorio, una distancia más pequeña entre el entrenamiento y el rendimiento de prueba y, sobre todo, un rendimiento de prueba más bajo. Inversamente, aumentar el tamaño de la muestra bootstrap aumenta el grado de sobreajuste. Como las muestras bootstrap, y en consecuencia los árboles de decisión individuales, se parecen más entre ellas, aprenden a ajustar el conjunto de datos de entrenamiento original más de cerca.
En la mayoría de las implementaciones, incluyendo la implementación RandomForestClassifier en scikit-learn, el tamaño de la muestra bootstrap se elige para que sea igual al número de muestras del conjunto de entrenamiento original, que normalmente proporciona una buena compensación entre el sesgo y la varianza. Para el número de características d en cada división, deseamos elegir un valor que sea más pequeño que el número total de características en el conjunto de entrenamiento. Un parámetro por defecto razonable que se utiliza en scikit-learn y otras implementaciones es 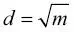 , donde m es el número de características en el conjunto de entrenamiento.
, donde m es el número de características en el conjunto de entrenamiento.
No hace falta que construyamos nosotros mismos el bosque aleatorio a partir de árboles de decisión individuales, puesto que ya existe una implementación en scikit-learn que podemos utilizar:
>>> from sklearn.ensemble import RandomForestClassifier
>>> forest = RandomForestClassifier(criterion='gini',
... n_estimators=25,
... random_state=1,
... n_jobs=2)
>>> forest.fit(X_train, y_train)
>>> plot_decision_regions(X_combined, y_combined,
... classifier=forest, test_idx=range(105,150))
>>> plt.xlabel('petal length')
>>> plt.ylabel('petal width')
>>> plt.legend(loc='upper left')
>>> plt.show()
Después de ejecutar el código anterior, podemos ver las regiones de decisión formadas por el conjunto de árboles en el bosque aleatorio, como se muestra en la siguiente imagen:
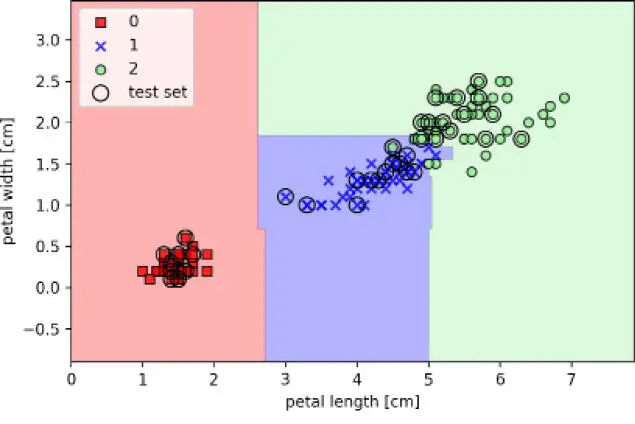
Con el código anterior, hemos entrenado un bosque aleatorio a partir de 25 árboles de decisión con el parámetro n_estimators y hemos utilizado el criterio de entropía como una medida de impureza para dividir los nodos. Aunque estamos cultivando un bosque aleatorio muy pequeño a partir de un conjunto de datos de entrenamiento muy pequeño, con la idea de demostrarlo hemos utilizado el parámetro n_jobs, el cual nos permite paralelizar el entrenamiento del modelo mediante múltiples núcleos de nuestro ordenador (en este caso, dos núcleos).
K-vecinos más cercanos: un algoritmo de aprendizaje vago
El último algoritmo de aprendizaje supervisado que queremos tratar en este capítulo es el clasificador k-vecinos más cercanos (KNN, del inglés k-nearest neighbours), que resulta especialmente interesante porque es fundamentalmente distinto de los algoritmos de aprendizaje que hemos tratado hasta ahora.
El KNN es un ejemplo típico de aprendizaje vago. Se denomina vago no por su aparente simplicidad, sino porque no obtiene ninguna función discriminitiva a partir de los datos de entrenamiento, sino que en su lugar memoriza el conjunto de datos de entrenamiento.
 |
|
Modelos paramétricos frente a no paramétricosLos algoritmos de aprendizaje automático se pueden agrupar en modelos paramétricos y no paramétricos. Con los modelos paramétricos, estimamos parámetros a partir de conjuntos de datos de entrenamiento para aprender una función que pueda clasificar nuevos puntos de datos sin necesidad del conjunto de datos de entrenamiento original. Los ejemplos típicos de modelos paramétricos son el perceptrón, la regresión logística y las SVM lineales. Contrariamente, los modelos no paramétricos no se pueden caracterizar por un conjunto fijo de parámetros, sino por que el número de parámetros crece con los datos de entrenamiento. Dos ejemplos de modelos no paramétricos que ya hemos visto son los árboles de decisión y bosques aleatorios y las SVM kernelizadas.El KNN pertenece a una subcategoría de modelos no paramétricos que se describe como aprendizaje basado en instancias. Los modelos asentados en el aprendizaje basado en instancias se caracterizan por memorizar el conjunto de datos de entrenamiento. El aprendizaje vago es un caso especial de aprendizaje basado en instancias que está asociado con un coste nulo (cero) durante el proceso de aprendizaje. |  |
El algoritmo KNN en sí mismo es bastante sencillo y se puede resumir en los siguientes pasos:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.