Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
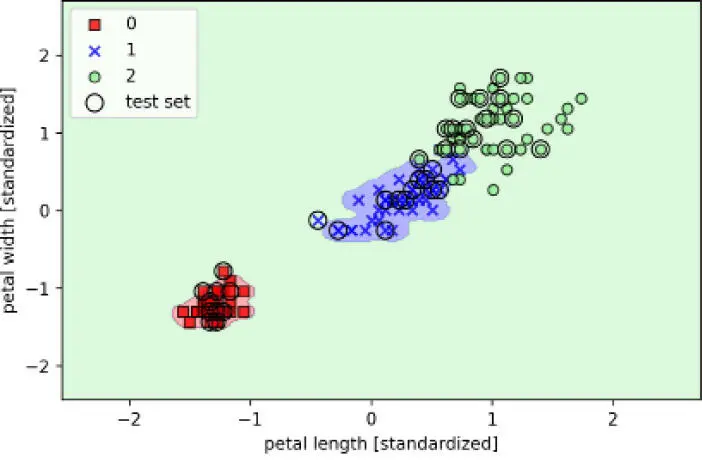
Aunque el modelo ajusta muy bien el conjunto de datos de entrenamiento, dicho clasificador probablemente tendrá un error de generalización elevado sobre los datos no vistos. Esto demuestra que el parámetro 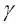 también juega un papel importante en el control del sobreajuste.
también juega un papel importante en el control del sobreajuste.
Aprendizaje basado en árboles de decisión
Los árboles de decisión son atractivos modelos si nos preocupamos de la interpretabilidad. Como su nombre sugiere, podemos pensar en este modelo como en una descomposición de nuestros datos mediante la toma de decisiones basada en la formulación de una serie de preguntas.
Vamos a considerar el siguiente ejemplo en el cual utilizamos un árbol de decisión para decidir sobre la realización de una actividad en un día en concreto:
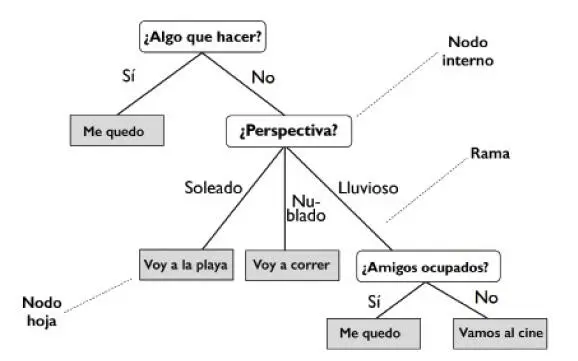
Si nos basamos en las características de nuestro conjunto de datos de entrenamiento, el modelo de árbol de decisión aprende una serie de preguntas para deducir las etiquetas de clase de las muestras. Aunque la imagen anterior muestra un concepto de árbol de decisión basado en variables categóricas, este mismo concepto se puede aplicar si nuestras características son números reales, como en el conjunto de datos Iris. Por ejemplo, podríamos simplemente definir un valor de corte a lo largo del eje de características anchura del sépalo y formular una pregunta binaria del tipo: «¿La anchura del sépalo es ≥ 2.8 cm?».
Utilizando el algoritmo de decisión, empezamos en la raíz del árbol y dividimos los datos en la característica que resulta en la mayor Ganancia de la información (IG, del inglés Information Gain), que explicaremos con más detalle en la siguiente sección. En un proceso iterativo, podemos repetir este procedimiento de división en cada nodo hijo hasta que las hojas sean puras. Esto significa que las muestras de cada nodo pertenecen todas a la misma clase. A la práctica, esto puede producir un árbol muy profundo con muchos nodos, que puede provocar fácilmente sobreajuste. Por lo tanto, una buena opción es podar el árbol ajustando un límite para su profundidad máxima.
Maximizar la ganancia de información: sacar el mayor partido de tu inversión
Con el fin de dividir los nodos en las características más informativas, debemos definir una función objetivo que deseamos optimizar mediante el algoritmo de aprendizaje del árbol. En este caso, nuestra función objetivo es maximizar la ganancia de información en cada división, que definimos de la siguiente forma:
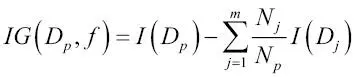
En este caso, f es la característica para realizar la división; 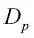 y
y 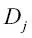 son el conjunto de datos del nodo padre y del nodo hijo j; I es nuestra medida de impureza;
son el conjunto de datos del nodo padre y del nodo hijo j; I es nuestra medida de impureza; 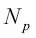 es el número total de muestras en el nodo padre; y
es el número total de muestras en el nodo padre; y 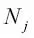 es el número de muestras en el nodo hijo j. Como podemos ver, la ganancia de información es simplemente la diferencia entre la impureza del nodo padre y la suma de las impurezas del nodo hijo: cuanto menor es la impureza de los nodos hijos, mayor es la ganancia de información. Sin embargo, por simplicidad y para reducir el espacio de búsqueda combinatoria, la mayoría de las librerías (incluida scikit-learn) implementan árboles de decisión binarios. Esto significa que cada nodo padre se divide en dos nodos hijos,
es el número de muestras en el nodo hijo j. Como podemos ver, la ganancia de información es simplemente la diferencia entre la impureza del nodo padre y la suma de las impurezas del nodo hijo: cuanto menor es la impureza de los nodos hijos, mayor es la ganancia de información. Sin embargo, por simplicidad y para reducir el espacio de búsqueda combinatoria, la mayoría de las librerías (incluida scikit-learn) implementan árboles de decisión binarios. Esto significa que cada nodo padre se divide en dos nodos hijos, 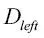 y
y 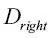 :
:
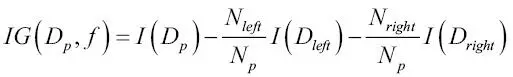
Ahora, las tres medidas de impurezas o criterios de división que normalmente se utilizan en los árboles de decisión binarios son impureza de Gini ( 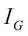 ), entropía (
), entropía ( 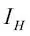 ) y error de clasificación (
) y error de clasificación ( 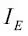 ). Vamos a empezar con la definición de entropía para todas las clases no-vacías (
). Vamos a empezar con la definición de entropía para todas las clases no-vacías ( 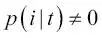 ):
):
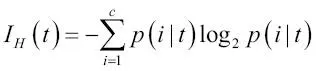
En este caso, 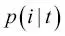 es la proporción de las muestras que pertenecen a la clase c para un determinado nodo t. La entropía es, por tanto, 0 si todas las muestras en un nodo pertenecen a la misma clase, y la entropía es máxima si tenemos una distribución de clases uniforme. Por ejemplo, en un ajuste de clases binario, la entropía es 0 si
es la proporción de las muestras que pertenecen a la clase c para un determinado nodo t. La entropía es, por tanto, 0 si todas las muestras en un nodo pertenecen a la misma clase, y la entropía es máxima si tenemos una distribución de clases uniforme. Por ejemplo, en un ajuste de clases binario, la entropía es 0 si 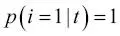 o
o 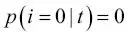 . Si las clases están distribuidas uniformemente con
. Si las clases están distribuidas uniformemente con 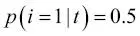 y
y 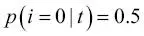 , la entropía es 1. Así, podemos decir que los criterios de la entropía intentan maximizar la información mutua en el árbol.
, la entropía es 1. Así, podemos decir que los criterios de la entropía intentan maximizar la información mutua en el árbol.
De forma intuitiva, la impureza de Gini se puede entender como un criterio para minimizar la probabilidad de clasificación errónea:
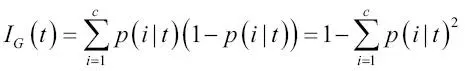
De forma similar a la entropía, la impureza de Gini es máxima si las clases están perfectamente mezcladas; por ejemplo, en un ajuste de clase binaria ( 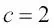 ):
):
Интервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.