Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
La idea fundamental que hay detrás de los métodos kernel para tratar datos inseparables lineales como estos es crear combinaciones no lineales de las características originales para proyectarlas hacia un espacio de dimensiones mayores, mediante una función de mapeo 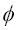 , donde pasen a ser separables lineales. Como se muestra en la siguiente imagen, podemos transformar, mediante la siguiente proyección, un conjunto de datos bidimensional en un nuevo espacio de características tridimensional donde las clases sean separables:
, donde pasen a ser separables lineales. Como se muestra en la siguiente imagen, podemos transformar, mediante la siguiente proyección, un conjunto de datos bidimensional en un nuevo espacio de características tridimensional donde las clases sean separables:
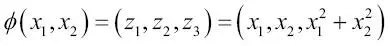
Esto nos permite separar las dos clases que aparecen en el gráfico mediante un hiperplano lineal que se convierte en un límite de decisión no lineal si lo volvemos a proyectar en el espacio de características original:
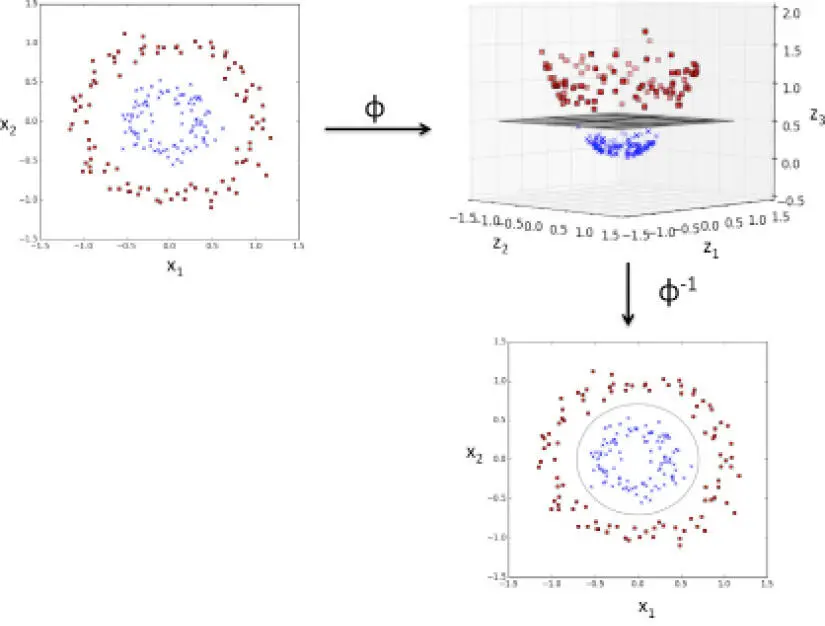
El truco de kernel para encontrar hiperplanos separados en un espacio de mayor dimensionalidad
Para resolver un problema no lineal utilizando una SVM, debemos transformar los datos de entrenamiento en un espacio de características de mayor dimensionalidad mediante una función de mapeo y entrenar un modelo de SVM lineal para clasificar los datos en este nuevo espacio de características. Después, podemos utilizar la misma función de mapeo 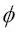 para transformar nuevos datos no vistos y clasificarlos mediante el modelo de SVM lineal.
para transformar nuevos datos no vistos y clasificarlos mediante el modelo de SVM lineal.
Sin embargo, un problema con este enfoque de mapeo es que la construcción de nuevas características es computacionalmente muy costosa, especialmente si tratamos con datos de mayor dimensionalidad. Y aquí es donde el denominado truco de kernel entra en juego. No entraremos mucho en detalle sobre cómo resolver la tarea de programación cuadrática para entrenar un SVM, ya que a la práctica todo cuanto necesitamos es sustituir el producto escalar 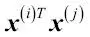 por
por 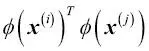 . Con el fin de ahorrarnos el costoso paso de calcular este producto escalar entre dos puntos explícitamente, definimos la denominada función kernel:
. Con el fin de ahorrarnos el costoso paso de calcular este producto escalar entre dos puntos explícitamente, definimos la denominada función kernel: 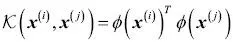 .
.
Uno de los kernels más ampliamente utilizados es la Función de base radial (RBF), también denominada kernel Gaussiana:
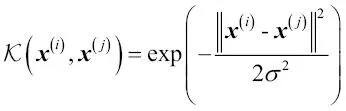
Habitualmente se simplifica como:
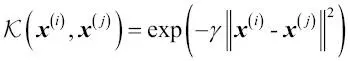
En este caso, 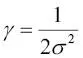 es un parámetro libre que debe ser optimizado.
es un parámetro libre que debe ser optimizado.
Más o menos, el término kernel puede ser interpretado como una función de similitud entre un par de muestras. El signo menos invierte la medida de distancia de una puntuación de similitud y, debido al término exponencial, la puntuación de similitud resultante caerá en un rango entre 1 (para muestras exactamente similares) y 0 (para muestras muy diferentes).
Ahora que ya hemos definido a grandes rasgos cuanto hay detrás del truco de kernel, podemos entrenar una SVM kernelizada que sea capaz de dibujar un límite de decisión no lineal que separe correctamente los datos XOR. En este caso, simplemente utilizamos la clase SVC de scikit-learn que importamos anteriormente y sustituimos el parámetro kernel='linear' por kernel='rbf':
>>> svm = SVC(kernel='rbf', random_state=1, gamma=0.10, C=10.0)
>>> svm.fit(X_xor, y_xor)
>>> plot_decision_regions(X_xor, y_xor, classifier=svm)
>>> plt.legend(loc='upper left')
>>> plt.show()
Como podemos ver en el diagrama resultante, la SVM kernelizada separa los datos XOR relativamente bien:
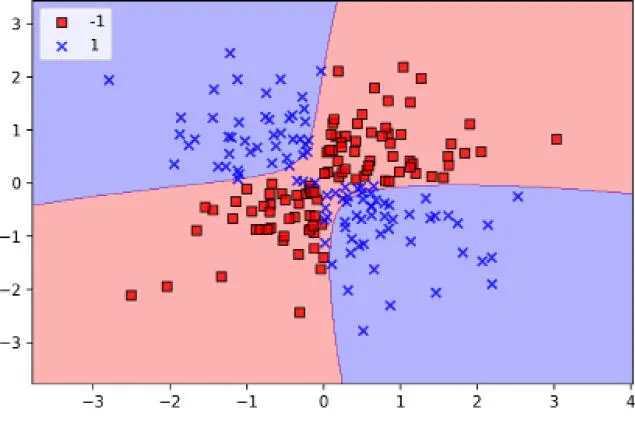
El parámetro 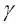 , que ajustamos en gamma=0.1, se puede entender como un parámetro de corte para la esfera Gaussiana. Si aumentamos el valor de , aumentamos la influencia o alcance de las muestras de entrenamiento, lo cual nos lleva a un límite de decisión más ajustado y lleno de baches. Para conseguir una intuición mejor para , vamos a aplicar una SVM kernelizada de RBF a nuestro conjunto de datos de flor Iris:
, que ajustamos en gamma=0.1, se puede entender como un parámetro de corte para la esfera Gaussiana. Si aumentamos el valor de , aumentamos la influencia o alcance de las muestras de entrenamiento, lo cual nos lleva a un límite de decisión más ajustado y lleno de baches. Para conseguir una intuición mejor para , vamos a aplicar una SVM kernelizada de RBF a nuestro conjunto de datos de flor Iris:
>>> svm = SVC(kernel='rbf', random_state=1, gamma=0.2, C=1.0)
>>> svm.fit(X_train_std, y_train)
>>> plot_decision_regions(X_combined_std,
... y_combined, classifier=svm,
... test_idx=range(105,150))
>>> plt.xlabel('petal length [standardized]')
>>> plt.ylabel('petal width [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.show()
Como hemos elegido un valor para relativamente pequeño, el límite de decisión resultante del modelo SVM kernelizado RBF será relativamente suave, como se muestra en la siguiente figura:
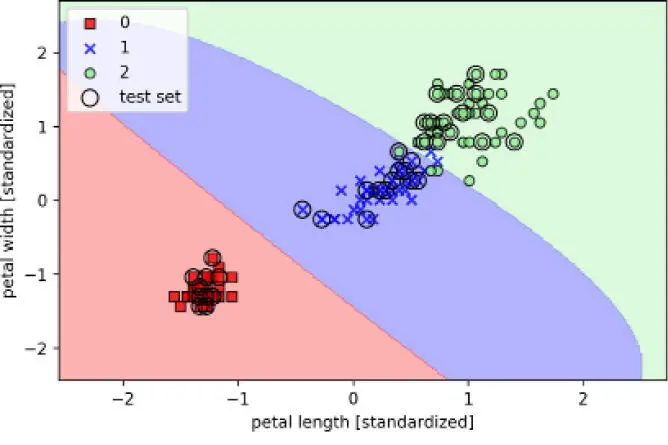
Seguidamente, aumentaremos el valor de y observaremos el efecto en el límite de decisión:
>>> svm = SVC(kernel='rbf', random_state=1, gamma=100.0, C=1.0)
>>> svm.fit(X_train_std, y_train)
>>> plot_decision_regions(X_combined_std,
... y_combined, classifier=svm,
... test_idx=range(105,150))
>>> plt.xlabel('petal length [standardized]')
>>> plt.ylabel('petal width [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.show()
En el gráfico resultante podemos ver que el límite de decisión alrededor de las clases 0 y 1 está mucho más apretado si utilizamos un valor de relativamente grande:
Интервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.