Vahid Mirjalili - Python Machine Learning
Здесь есть возможность читать онлайн «Vahid Mirjalili - Python Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Python Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Python Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Python Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Modernizado y ampliado para incluir las tecnologías de código abierto más recientes, como scikit-learn, Keras y TensorFlow, este manual proporciona el conocimiento práctico y las técnicas necesarias para crear eficaces aplicaciones de aprendizaje automático y aprendizaje profundo en Python.
El conocimiento y la experiencia únicos de Sebastian Raschka y Vahid Mirjalili presentan los algoritmos de aprendizaje automático y aprendizaje profundo, antes de continuar con temas avanzados en análisis de datos.
Combinan los principios teóricos del aprendizaje automático con un enfoque práctico de codificación para una comprensión completa de la teoría del aprendizaje automático y la implementación con Python.
Aprenderás a:
Explorar y entender los frameworks clave para la ciencia de datos, el aprendizaje automático y el aprendizaje profundo
Formular nuevas preguntas sobre datos con modelos de aprendizaje automático y redes neuronales
Aprovechar el poder de las últimas librerías de código abierto de Python para aprendizaje automático
Dominar la implementación de redes neuronales profundas con la librería de TensorFlow
Incrustar modelos de aprendizaje automáticos en aplicacions web accesibles
Predecir resultados objetivos continuos con análisis de regresión
Descubrir patrones ocultos y estructuras en datos con agrupamientos
Analizar imágenes mediante técnicas de aprendizaje profundo
Profundizar en datos de medios sociales y textuales con el análisis de sentimientos
Python Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Python Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
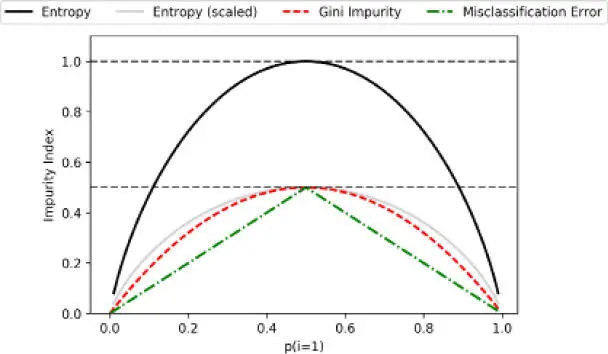
... 'Gini Impurity',
... 'Misclassification Error'],
... ['-', '-', '--', '-.'],
... ['black', 'lightgray',
... 'red', 'green', 'cyan']):
... line = ax.plot(x, i, label=lab,
... linestyle=ls, lw=2, color=c)
>>> ax.legend(loc='upper center', bbox_to_anchor=(0.5, 1.15),
... ncol=5, fancybox=True, shadow=False)
>>> ax.axhline(y=0.5, linewidth=1, color='k', linestyle='--')
>>> ax.axhline(y=1.0, linewidth=1, color='k', linestyle='--')
>>> plt.ylim([0, 1.1])
>>> plt.xlabel('p(i=1)')
>>> plt.ylabel('Impurity Index')
>>> plt.show()
El gráfico obtenido a partir del código anterior es el siguiente:
Crear un árbol de decisión
Los árboles de decisión pueden generar límites de decisión complejos dividiendo el espacio de características en rectángulos. Sin embargo, debemos ir con cuidado puesto que cuanto más profundo es el árbol de decisión, más complejo es el límite de decisión, el cual puede caer fácilmente en el sobreajuste. Con scikit-learn, vamos a entrenar un árbol de decisión con una profundidad máxima de 3, utilizando la entropía como criterio para la impureza. Aunque podríamos desear un escalado de características por motivos de visualización, ten en cuenta que dicho escalado de características no es obligatorio para los algoritmos de árboles de decisión. El código es el siguiente:
>>> from sklearn.tree import DecisionTreeClassifier
>>> tree = DecisionTreeClassifier(criterion='gini',
... max_depth=4,
... random_state=1)
>>> tree.fit(X_train, y_train)
>>> X_combined = np.vstack((X_train, X_test))
>>> y_combined = np.hstack((y_train, y_test))
>>> plot_decision_regions(X_combined,
... y_combined,
... classifier=tree,
... test_idx=range(105, 150))
>>> plt.xlabel('petal length [cm]')
>>> plt.ylabel('petal width [cm]')
>>> plt.legend(loc='upper left')
>>> plt.show()
Después de ejecutar el código de ejemplo, obtenemos los límites de decisión típicos de eje paralelo del árbol de decisión:

Una buena característica de scikit-learn es que después del entrenamiento nos permite exportar el árbol de decisión como un archivo .dot, que podemos visualizar con el programa GraphViz, por ejemplo.
Este programa está disponible de forma gratuita en http://www.graphviz.orgy es compatible con Linux, Windows y macOS. Además de GraphViz, utilizaremos una librería de Python denominada pydotplus, que tiene funciones similares a GraphViz y nos permite convertir archivos de datos .dot en un archivo de imagen de árbol de decisión. Después de instalar GraphViz (siguiendo las instrucciones que encontrarás en http://www.graphviz.org/Download.php), puedes instalar directamente pydotplus mediante el instalador pip, por ejemplo, ejecutando el siguiente comando en tu terminal:
> pip3 install pydotplus
 |
 |
Ten en cuenta que en algunos sistemas deberás instalar los requisitos pydotplus manualmente ejecutando los siguientes comandos:pip3 install graphvizpip3 install pyparsing |  |
El siguiente código creará una imagen de nuestro árbol de decisión en formato PNG en nuestro directorio local:
>>> from pydotplus import graph_from_dot_data
>>> from sklearn.tree import export_graphviz
>>> dot_data = export_graphviz(tree,
... filled=True,
... rounded=True,
... class_names=['Setosa',
... 'Versicolor',
... 'Virginica'],
... feature_names=['petal length',
... 'petal width'],
... out_file=None)
>>> graph = graph_from_dot_data(dot_data)
>>> graph.write_png('tree.png')
Mediante la opción out_file=None, asignamos directamente los datos dot a una variable dot_data, en lugar de escribir un archivo tree.dot intermedio en el disco. Los argumentos para filled, rounded, class_names y feature_names son opcionales pero hacen que el archivo de imagen resultante sea más atractivo visualmente al añadir color, redondear los bordes del cuadro, mostrar el nombre de la mayoría de las etiquetas de clase para cada nodo y mostrar los nombres de las características en el criterio de división. Estos ajustes dan como resultado la siguiente imagen de árbol de decisión:
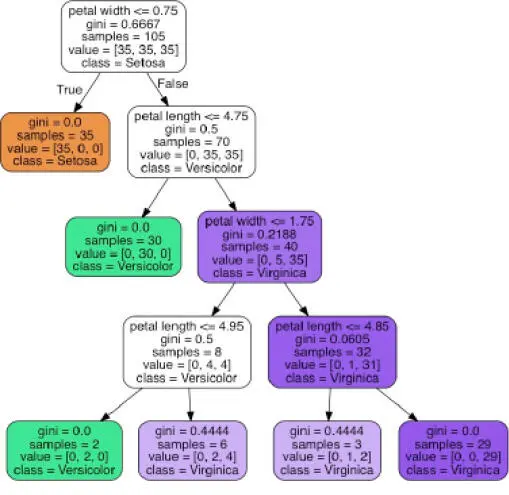
Si observamos la imagen del árbol de decisión, podemos trazar fácilmente las divisiones que el árbol de decisión ha determinado a partir de nuestro conjunto de datos de entrenamiento. Hemos empezado con 105 muestras en la raíz y las hemos dividido en dos nodos hijo con 35 y 70 muestras, mediante el corte anchura del pétalo ≤ 0.75 cm. Tras la primera división, podemos ver que el nodo hijo de la izquierda ya es puro y solo contiene muestras de la clase Iris-setosa (impureza de Gini = 0). Las otras divisiones a la derecha se utilizan para separar las muestras de la clase Iris-versicolor y Iris-virginica class.
Si observamos este árbol, y el gráfico de la región de decisión del árbol, vemos que el árbol de decisión ha hecho un buen trabajo separando las clases de flor. Desafortunadamente, por ahora scikit-learn no implementa ninguna funcionalidad para podar posteriormente de forma manual un árbol de decisión. Sin embargo, podríamos retomar nuestro ejemplo anterior, cambiar la max_depth de nuestro árbol de decisión a 3 y compararlo con nuestro modelo actual. Pero dejaremos este ejercicio para aquellos lectores más interesados.
Combinar árboles de decisión múltiples mediante bosques aleatorios
Los bosques aleatorios, o random forests, han ganado una gran popularidad entre las aplicaciones de aprendizaje automático durante la última década debido a su excelente rendimiento de clasificación, su escalabilidad y su facilidad de uso. De forma intuitiva, un bosque aleatorio se puede considerar como un conjunto de árboles de decisión. La idea que hay detrás de un bosque aleatorio es promediar árboles de decisión múltiples (profundos) que individualmente sufren una elevada varianza para crear un modelo más robusto que tenga un mejor rendimiento de generalización y sea menos susceptible al sobreajuste. El algoritmo del bosque aleatorio se puede resumir en cuatro sencillos pasos:
1.Dibuja una muestra bootstrap aleatoria de tamaño n (elige al azar muestras n del conjunto de entrenamiento con reemplazo).
2.Crea un árbol de decisión a partir de la muestra bootstrap. Para cada nodo:
a.Selecciona al azar características d sin reemplazo.
b.Divide el nodo utilizando la característica que proporciona la mejor división según la función objetivo; por ejemplo, maximizando la ganancia de información.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Python Machine Learning»
Представляем Вашему вниманию похожие книги на «Python Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Python Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.