Jose Manuel Ortega Candel - Desarrollo de motores de búsqueda utilizando herramientas open source
Здесь есть возможность читать онлайн «Jose Manuel Ortega Candel - Desarrollo de motores de búsqueda utilizando herramientas open source» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Desarrollo de motores de búsqueda utilizando herramientas open source
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Desarrollo de motores de búsqueda utilizando herramientas open source: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Desarrollo de motores de búsqueda utilizando herramientas open source»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Si desea adquirir los conocimientos necesarios para dominar las principales herramientas open source, las librerías y los frameworks, ha llegado al libro indicado. Este manual le proporciona, desde un enfoque teórico-práctico, todos los conceptos e instrucciones que le permitirán construir desde cero motores de búsqueda utilizando los lenguajes de programación Java y Python.
Gracias a los contenidos del libro:
o Conocerá la estructura y naturaleza de un motor de búsqueda, así como la importancia de los sistemas de búsqueda y recuperación de la información.
o Aprenderá los principales motores de búsqueda open source y su funcionamiento interno.
o Dominará las diferentes herramientas para desarrollar motores de búsqueda utilizando frameworks de desarrollo dentro de los ecosistemas de programación Java y Python.
Además, con el objetivo de obtener el máximo provecho de las herramientas y facilitar el seguimiento de las prácticas del libro, en la primera página se proporciona el acceso al repositorio con el código de los ejemplos desarrollados.
Hágase con el libro y descubra las principales herramientas que todo desarrollador e ingeniero de software debe dominar para desarrollar sus propios motores de búsqueda.
Desarrollo de motores de búsqueda utilizando herramientas open source — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Desarrollo de motores de búsqueda utilizando herramientas open source», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
• Documentos primarios:informes, artículos, páginas web, etc.
• Documentos secundarios:título, autor, resumen, etc.
La necesidad informativa se expresa formalmente mediante una consulta:
• Puede emplear diferentes términos y operadores booleanos.
• Puede realizarse en lenguaje natural.
La recuperación de información se utiliza en muchas de las aplicaciones que encontramos hoy en día, por ejemplo:
• Bibliotecas digitales
• Buscadores de Internet
• Herramientas de búsqueda personal (correos electrónicos, documentos personales, etc.
1.5.1 Extracción de información
La extracción de información es un área de investigación que comprende la intersección entre lingüística computacional, machine learning , data mining , bases de datos y recuperación de información. Se trata de un proceso que consiste en obtener información relevante a partir de un conjunto de documentos. Por tanto, el problema estriba en extraer la información y convertirla en información estructurada para poder buscar, manejar y explotar la información que se desee de forma eficiente.
El objetivo final es elaborar sistemas que permitan encontrar y relacionar información relevante mientras ignoran otras informaciones no relevantes. La relevancia se determina a partir de una serie de guías que permiten especificar con la mayor exactitud posible el tipo de información a extraer.
Desde la perspectiva del procesamiento de lenguaje natural, los sistemas de extracción de información deben trabajar a distintos niveles: desde el reconocimiento de palabras hasta el análisis de frases, y desde el entendimiento a nivel de frase hasta el texto completo. A grandes rasgos, entre las principales tareas relacionadas con la extracción de la información podemos destacar:
• Extracción de entidades y relaciones:
− Entidades:con nombre y genéricas.
− Relaciones:entidades relacionadas de una forma predefinida.
− Eventos:pueden estar compuestos de múltiples relaciones.
• Subtareas comunes en la extracción:
− Preproceso:segmentación de frases, análisis morfológico y sintáctico.
− Creación de reglas y/o patrones de extracción:de forma manual, automática o mixta.
− Aplicación de reglas o patrones de extracción:para extraer nueva información.
− Post-proceso:integración de la información, resolución y desambiguación de términos.
1.5.2 Sistema de búsqueda/respuesta
Un sistema basado en búsqueda/respuesta parte de una consulta expresada en lenguaje natural y debe devolver no un documento que sea relevante (es decir, un documento que contenga la respuesta) sino la propia respuesta (normalmente, un hecho). Proporciona el fragmento de texto en el que se encuentra la respuesta a una pregunta del usuario.
A diferencia de los sistemas de recuperación de la información convencionales que utilizan técnicas estadísticas, los sistemas de búsqueda/respuesta emplean técnicas de PLN (procesamiento de lenguaje natural). Uno de los sistemas de búsqueda/respuesta más conocidos es el correspondiente al START ( natural language question answering system )( figura 1.3).
http://www.ai.mit.edu/projects/infolab/globe.html
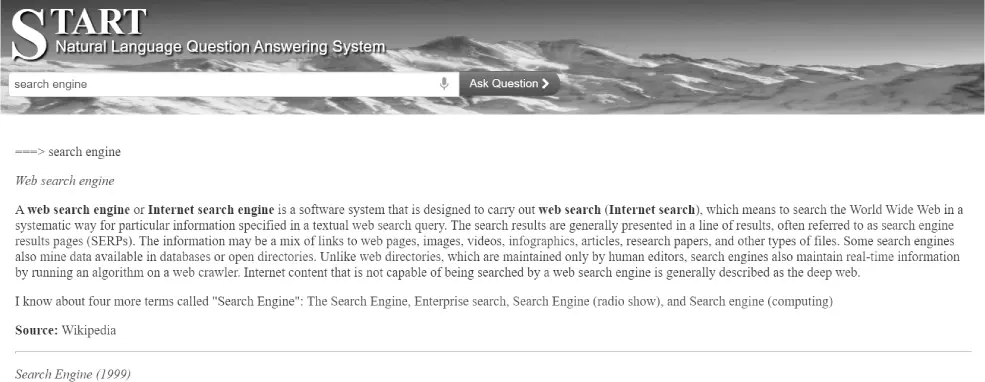
Figura 1.3Sistema START de búsqueda/respuesta.
1.6 MOTORES DE BÚSQUEDA E INDEXADORES
Los sistemas de recuperación de información con índice invertido son sistemas caracterizados por tener una estructura de datos capaz de manejar grandes volúmenes de información orientados a texto. Esta funcionalidad está presente en los motores de búsqueda que se van a analizar en profundidad:
• Apache Lucene( https://lucene.apache.org) es una potente librería de recuperación de información que se basa en la elaboración de un índice invertido como principal estructura especializada en emparejar documentos de texto con términos de consulta. Lucene, al igual que otros motores de búsqueda, se distingue por la escalabilidad, el rápido despliegue, el manejo de grandes volúmenes de datos y la optimización orientada a búsqueda de textos en documentos.
• Apache Solr( https://lucene.apache.org/solr) es una librería open source construida sobre la librería de Lucene, que incluye una interfaz web de administración, API en distintos lenguajes para la realización de consultas y una serie de mejoras funcionales sobre las características base que trae Lucene de serie.
• ElasticSearch( https://www.elastic.co/es/), construido sobre Apache Lucene, ha basado su modelo en una API REST y ha ganado popularidad en los últimos años. Se trata de una plataforma distribuida en tiempo real de búsqueda y análisis:
− ElasticSearch distribuye y organiza la información en clúster de nodos, por lo que lo podemos ejecutar en varios servidores si nuestra aplicación necesita escalar.
− ElasticSearch es un motor de búsqueda que funciona en tiempo real, ya que los datos están indexados. De esta forma, obtenemos respuestas a nuestras consultas de forma mucho más rápida si lo comparamos con otras soluciones.
En la actualidad, es común que las aplicaciones estén respaldadas por una base de datos sobre la que se implementan las búsquedas. Sin embargo, con este enfoque, la implementación de funcionalidades de búsqueda con cierta complejidad puede llegar a ser complicada debido a las limitaciones de las bases de datos. Por ejemplo, las búsquedas pueden no llegar a ser suficientemente eficientes si el volumen de información es muy grande o si la forma en que está estructurada la información no es la adecuada. En escenarios como estos, una plataforma especialmente dedicada a la optimización de las búsquedas puede resultar una alternativa más práctica y eficiente.
Estas plataformas utilizan un modelo de datos orientado a documentosque pueden pensarse como una base de datos de una sola tabla. Un documento es simplemente un conjunto de campos, como una tupla en una tabla de una base de datos, con la diferencia de que cada columna puede ser multivaluada.
Además, permiten la implementación de funcionalidades de búsqueda sobre documentos que facilitan al usuario la localización de recursos de una manera más rápida y organizada. Tomando como referencia la web DB-Engines, podemos ver que la solución más popular hoy en día es ElasticSearch. En el siguiente URL podemos ver los motores de búsqueda más populares:
https://db-engines.com/en/ranking/search+engine
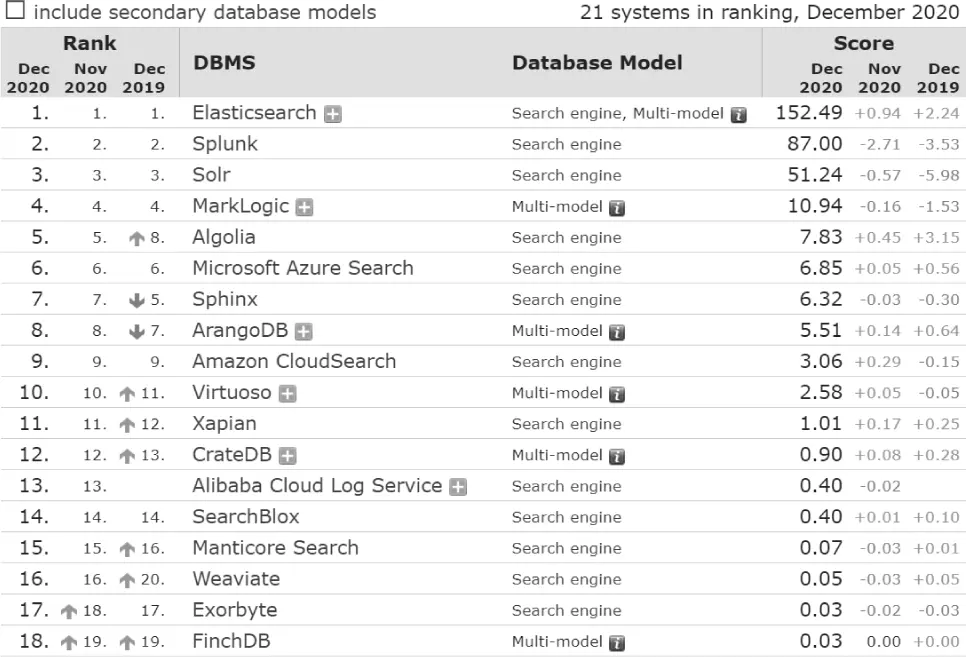
Figura 1.4Listado de motores de búsqueda.
De los motores mostrados en la figura 1.4, analizaremos en profundidad tanto ElasticSearch como Apache Solr (ambos basados en Lucene, que nos permite realizar búsquedas por una gran cantidad de datos de un texto específico). Gracias al motor Lucene sobre el que están implementados, estos motores nos ofrecen capacidades de búsquedas de texto, autocompletado y soporte de geolocalización. Podríamos definir a estos motores de búsqueda como bases de datos NoSQL orientadas a documentos JSON, que pueden ser consultados, creados, actualizados o borrados mediante una API REST.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Desarrollo de motores de búsqueda utilizando herramientas open source»
Представляем Вашему вниманию похожие книги на «Desarrollo de motores de búsqueda utilizando herramientas open source» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Desarrollo de motores de búsqueda utilizando herramientas open source» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.