Jose Manuel Ortega Candel - Desarrollo de motores de búsqueda utilizando herramientas open source
Здесь есть возможность читать онлайн «Jose Manuel Ortega Candel - Desarrollo de motores de búsqueda utilizando herramientas open source» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Desarrollo de motores de búsqueda utilizando herramientas open source
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Desarrollo de motores de búsqueda utilizando herramientas open source: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Desarrollo de motores de búsqueda utilizando herramientas open source»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Si desea adquirir los conocimientos necesarios para dominar las principales herramientas open source, las librerías y los frameworks, ha llegado al libro indicado. Este manual le proporciona, desde un enfoque teórico-práctico, todos los conceptos e instrucciones que le permitirán construir desde cero motores de búsqueda utilizando los lenguajes de programación Java y Python.
Gracias a los contenidos del libro:
o Conocerá la estructura y naturaleza de un motor de búsqueda, así como la importancia de los sistemas de búsqueda y recuperación de la información.
o Aprenderá los principales motores de búsqueda open source y su funcionamiento interno.
o Dominará las diferentes herramientas para desarrollar motores de búsqueda utilizando frameworks de desarrollo dentro de los ecosistemas de programación Java y Python.
Además, con el objetivo de obtener el máximo provecho de las herramientas y facilitar el seguimiento de las prácticas del libro, en la primera página se proporciona el acceso al repositorio con el código de los ejemplos desarrollados.
Hágase con el libro y descubra las principales herramientas que todo desarrollador e ingeniero de software debe dominar para desarrollar sus propios motores de búsqueda.
Desarrollo de motores de búsqueda utilizando herramientas open source — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Desarrollo de motores de búsqueda utilizando herramientas open source», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Además, el proceso de indexación puede mejorar el rendimiento de las consultas, ya que los datos necesarios para satisfacer las necesidades de la consulta existen en el propio índice y se reduce al máximo el tamaño de los archivos; por lo tanto, se reducen también las operaciones de lectura y escritura sobre el disco.
En el proceso de indexación, para agilizar la búsqueda de grandes cantidades de datos es necesario hacer uso de índices, ya que estos mejoran la velocidad de las operaciones, de modo que el acceso a la información es más rápido.
Cuando el número de archivos a buscar es potencialmente de gran tamaño, o la cantidad de consultas de búsqueda por realizar es considerable, el problema de búsqueda a menudo se divide en dos tareas: la indexación y la búsqueda. La etapa de indexación analizará el contenido de todos los archivos y creará una lista de los términos de búsqueda, a menudo llamada índice. En la etapa de búsqueda, al realizar una consulta específica, esta se realiza utilizando el índice en lugar de utilizar el contenido de los documentos originales.
1.4.1 Rendimiento en la indexación de documentos
A la hora de almacenar documentos hay que tener en cuenta que uno de los factores más importantes es el rendimiento. Los factores que afectan al rendimiento son: el número de campos a indexar o almacenar, el número de registros que se introducen, el tamaño de los documentos a indexar y el tipo de documento que se indexa (pdf, txt, xml, etc.).
En este punto, el proceso de indexación trata de reducir al máximo el tamaño de los archivos o tablas de la base de datos, para conseguir la mejor relación entre tiempo de ejecución de las consultas y exhaustividad del fichero inverso. Para ello, vamos a introducir los siguientes conceptos:
• stopwords:se trata de una lista de palabras de uso frecuente que no se tienen en consideración ni en el proceso de indexación ni en el de búsqueda.
• stemming:es un método para obtener la raíz semántica de una palabra. Las palabras se reducen a su raíz o stem (tema).
1.4.2 Stopwords
Las stopwords son palabras que no contienen un significado importante, por lo que no serán utilizadas en las consultas de búsqueda.
Se trata de una técnica de indexación que genera una lista de palabras de uso frecuente que no se tendrán en consideración y que se omitirán tanto en el momento del proceso de indexación como en el proceso de búsqueda. El hecho de que haya palabras que no aparezcan en el índice en una base de datos se debe a que son insignificantes (como los artículos y las preposiciones). Estas palabras son excluidas de las búsquedas para agilizar el proceso de indexar y analizar las páginas web. Algunos ejemplos de estas palabras son: “un”, “y”, “pero”, “cómo”, “o” y “qué”. Los buscadores, en Internet, no pueden impedir el uso de estas palabras; por lo tanto, las ignoran.
1.4.3 Stemming
Stemming es un método que permite reducir una palabra a su raíz o stem . Hay algunos algoritmos de stemming que ayudan en sistemas de recuperación de información. El stemming aumenta el recall, que es una medida sobre el número de documentos que se pueden encontrar con una consulta. Por ejemplo, una consulta sobre “bibliotecas” también encontrará documentos en los que solo aparezca “bibliotecario”, porque el stem de las dos palabras es el mismo (“biblioteca”).
Esta técnica se suele utilizar cuando queremos que un término pueda reducirse a su común denominador, y permitirá la recuperación de todos los documentos cuyas palabras tengan la misma raíz común (por ejemplo: catálogo, catálogos, catalogación, catalogador, catalogar, catalogando, catalogado).
1.5 RECUPERACIÓN DE LA INFORMACIÓN
La recuperación de información, o information retrieval, es una disciplina que se encarga de estudiar las técnicas para buscar información dentro de documentos que no se encuentran organizados o cuando, debido a la gran cantidad de documentos, resulta difícil buscar de forma manual.
Los sistemas para la recuperación de información están formados por diferentes mecanismos, que son los que permiten realizar las búsquedas, y un spider o crawler, que es el que se encarga de recorrer la web siguiendo los enlaces que va encontrando en las páginas o documentos. Este recorrido puede realizarse tanto en profundidad como a lo ancho y, generalmente, este tipo de programas suelen estar alojados en ordenadores con gran capacidad de memoria y CPU.
Los documentos encontrados en la web son analizados por el crawler, que les da un formato común. Después, estos documentos se almacenan en alguna estructura de datos, que puede ser un sistema relacional en forma de índices para su rápido acceso. En este proceso se realiza un análisis de cada una de las páginas o documentos encontrados y, por cada palabra encontrada, se guarda la referencia del documento donde se encuentra.
Cuando el usuario escribe el criterio a buscar, los resultados se muestran de forma ordenada según una relevancia que se calcula teniendo en cuenta el modelo de recuperación utilizado.
Este último componente también se comunica con el mecanismo de formulación de consulta, que es el que utiliza los términos introducidos por el usuario y los convierte en los términos que están almacenados en el índice. De esta forma, realiza una recuperación de todos los documentos que presentan estos términos, ordenándolos por la relevancia asociada a cada documento.
A partir de una colección de documentos, se seleccionan aquellos relacionados con una pregunta de un usuario a través de un conjunto de palabras claves. La recuperación de información tiene las siguientes características:
• La información es una pieza fundamental en todos los procesos de nuestra sociedad.
• El desarrollo de las tecnologías de la información (TI) ha permitido crear sistemas y servicios de información cada vez más ágiles.
• El desarrollo de las comunicaciones ha permitido el acceso a información desde cualquier sitio de forma remota.
• Hoy en día disponemos de gran cantidad de repositorios y documentación en Internet.
A continuación, se muestran los principales pasos para la recuperación de la información ( figura 1.2):
1. Obtener representación de los documentos.Generalmente, los documentos se presentan utilizando un conjunto más o menos grande de términos índice. La elección de dichos términos es el proceso más complicado.
2. Identificar la necesidad informativa del usuario.Se trata de obtener la representación de esa necesidad y plasmarla formalmente en una consulta acorde con el sistema de recuperación.
3. Búsqueda de documentos que satisfagan la consulta.Consiste en comparar las representaciones de documentos y la representación de la necesidad informativa para seleccionar los documentos pertinentes.
4. Presentación de los resultados al usuario.Puede ser desde una breve identificación del documento hasta el texto completo.
5. Evaluación de los resultados. Para determinar si son acordes con la necesidad informativa.
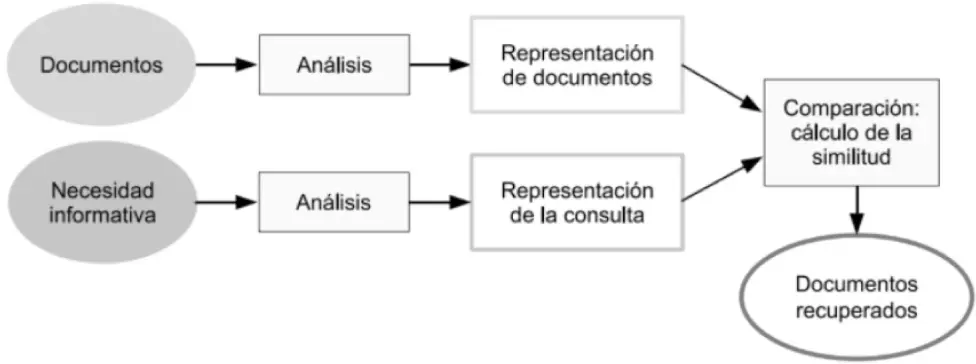
Figura 1.2Pasos para un proceso de recuperación de información.
Los sistemas de recuperación basados en términos índice se apoyan en la idea fundamental de que tanto el contenido de los documentos como la necesidad informativa del usuario pueden representarse con términos índice, lo cual permite agrupar diferentes documentos para representar un concepto. Los documentos se pueden clasificar, a grandes rasgos, en dos categorías:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Desarrollo de motores de búsqueda utilizando herramientas open source»
Представляем Вашему вниманию похожие книги на «Desarrollo de motores de búsqueda utilizando herramientas open source» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Desarrollo de motores de búsqueda utilizando herramientas open source» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.