Jose Manuel Ortega Candel - Desarrollo de motores de búsqueda utilizando herramientas open source
Здесь есть возможность читать онлайн «Jose Manuel Ortega Candel - Desarrollo de motores de búsqueda utilizando herramientas open source» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на испанском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Desarrollo de motores de búsqueda utilizando herramientas open source
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Desarrollo de motores de búsqueda utilizando herramientas open source: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Desarrollo de motores de búsqueda utilizando herramientas open source»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Si desea adquirir los conocimientos necesarios para dominar las principales herramientas open source, las librerías y los frameworks, ha llegado al libro indicado. Este manual le proporciona, desde un enfoque teórico-práctico, todos los conceptos e instrucciones que le permitirán construir desde cero motores de búsqueda utilizando los lenguajes de programación Java y Python.
Gracias a los contenidos del libro:
o Conocerá la estructura y naturaleza de un motor de búsqueda, así como la importancia de los sistemas de búsqueda y recuperación de la información.
o Aprenderá los principales motores de búsqueda open source y su funcionamiento interno.
o Dominará las diferentes herramientas para desarrollar motores de búsqueda utilizando frameworks de desarrollo dentro de los ecosistemas de programación Java y Python.
Además, con el objetivo de obtener el máximo provecho de las herramientas y facilitar el seguimiento de las prácticas del libro, en la primera página se proporciona el acceso al repositorio con el código de los ejemplos desarrollados.
Hágase con el libro y descubra las principales herramientas que todo desarrollador e ingeniero de software debe dominar para desarrollar sus propios motores de búsqueda.
Desarrollo de motores de búsqueda utilizando herramientas open source — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Desarrollo de motores de búsqueda utilizando herramientas open source», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
1.2.3 Esquema flexible
La última característica destacada de los motores de búsqueda es que tienen un esquema flexible. Esto significa que los documentos, en un índice de búsqueda, no necesitan una estructura uniforme. En una base de datos relacional, cada fila de una tabla tiene la misma estructura.
La mayoría de los motores de búsqueda se basan en que los documentos pueden tener diferentes campos y no hay una estructura fija. Piense, por ejemplo, en bases de datos NoSQL orientadas a documentos como Mongo-DB o CouchDB.
El beneficio de disponer de una variedad de opciones para almacenar y procesar datos es que no tiene que encontrar una tecnología única para todos. En la mayoría de los casos, podrá complementar el uso de motores de búsqueda tanto con bases de datos relacionales como con bases de datos NoSQL.
1.3 FUNCIONAMIENTO DE UN MOTOR DE BÚSQUEDA
Un motor de búsqueda es un programa que permite localizar en un conjunto de documentos aquellos relacionados con una palabra o palabras clave seleccionadas. Para ofrecer esta funcionalidad, se exploran los ficheros existentes en el sistema de forma eficiente, registrando información relevante sobre ellos en una base de datos. Esta base de datos es empleada por el motor para permitir a los usuarios realizar consultas y localizar esos documentos de forma más sencilla.
Así pues, para conseguir esta funcionalidad, existen varios componentes principales que permiten al motor de búsqueda realizar estas operaciones:
• Crawler o Spider:así se denomina el proceso que recorre el conjunto de documentos almacenados, ya sea en una máquina o en una red, que recoge los metadatos y la ubicación de los mismos para, posteriormente, guardar un registro de todos ellos y permitir su rápida localización y presentación al usuario. En colecciones de documentos reducidas, esta operación no le supone una gran cargabilidad al proceso. Sin embargo, en entornos como Internet, se precisa de un proceso que esté de forma continuada verificando los enlaces que forman una web, dado que la situación de los elementos es más dinámica y varía con el tiempo.
• Índice:el índice se puede describir como el conjunto de información recopilada por el crawler y que se almacena en un registro; se denomina índice de búsqueda. Estos datos son los que emplea posteriormente el motor para escoger los elementos que cumplen con la petición del usuario a través de las palabras clave que conforman la consulta.
• Algoritmo de ordenación:si el índice es el corazón del motor de búsqueda, el algoritmo de ordenación es el cerebro, ya que es el responsable de recoger los datos del índice de la forma más adecuada posible, devolviendo al usuario los resultados por orden de relevancia. Es interesante que los datos más relevantes sean siempre los primeros en aparecer, según diferentes criterios de ordenación. Se permite que estos criterios, en ocasiones, sean personalizables bajo ciertos requisitos, lo cual dota al algoritmo de cierta flexibilidad y adaptación. Esto permite al motor adaptarse a las necesidades reales del entorno empresarial o del usuario.
De los elementos comentados, el índice se puede considerar como el corazón del motor de búsqueda. El índice y el algoritmo de ordenación empleado son los elementos diferenciadores que actualmente permiten la existencia de una gran diversidad de motores de búsqueda.
1.3.1 Buscadores de directorios
Los buscadores de directorio buscan información sobre contenidos de la página, y los resultados se presentan haciendo referencia a los contenidos y temática del sitio. Los algoritmos para este tipo de motor de búsqueda son más sencillos, y los sitios se presentan como enlaces, los cuales representan los sitios registrados. Estos tipos de buscadores no recorren los sitios web ni almacenan sus contenidos; lo que hacen es registrar algunos de los datos de la página web, como el título y la descripción (que normalmente se introducen en el momento de registrar el sitio en el directorio).
1.3.2 Buscadores jerárquicos
Este tipo de motor de búsqueda recorre las páginas coleccionando información sobre sus contenidos. Cuando se inicia una búsqueda de información concreta en los buscadores, ellos consultan su base de datos y presentan resultados clasificados por su distinción para esa búsqueda concreta. Los buscadores pueden almacenar en sus bases de datos desde la página de entrada de cada web hasta todas las páginas que residan en el servidor, una vez que el buscador la haya reconocido e indexado.
Debido a que los motores de búsqueda contienen millones —y a veces miles de millones— de páginas, muchos motores de búsqueda no solo se centran en el proceso de búsqueda, sino que también muestran los resultados en función de su importancia. Esta importancia de los resultados se determina normalmente mediante el uso de diversos algoritmos.
1.3.3 Spiders (arañas o crawlers)
Spider o araña es el nombre que se le ha dado al componente que se encarga de rastrear la web siguiendo su estructura hipertextual, para almacenar los enlaces en un lugar para su posterior análisis. En muchas ocasiones es llamado también crawler o webcrawler. Cada cierto tiempo, los spiders recorren la web para actualizar los contenidos recopilados con anterioridad; por ejemplo, los sitios de noticias y los blogs que están en constante actualización son analizados frecuentemente por estos programas. Además, los spiders pueden trabajar de forma conjunta, funcionando como una red de spiders, para obtener más documentos y almacenarlos en un repositorio o base de datos.
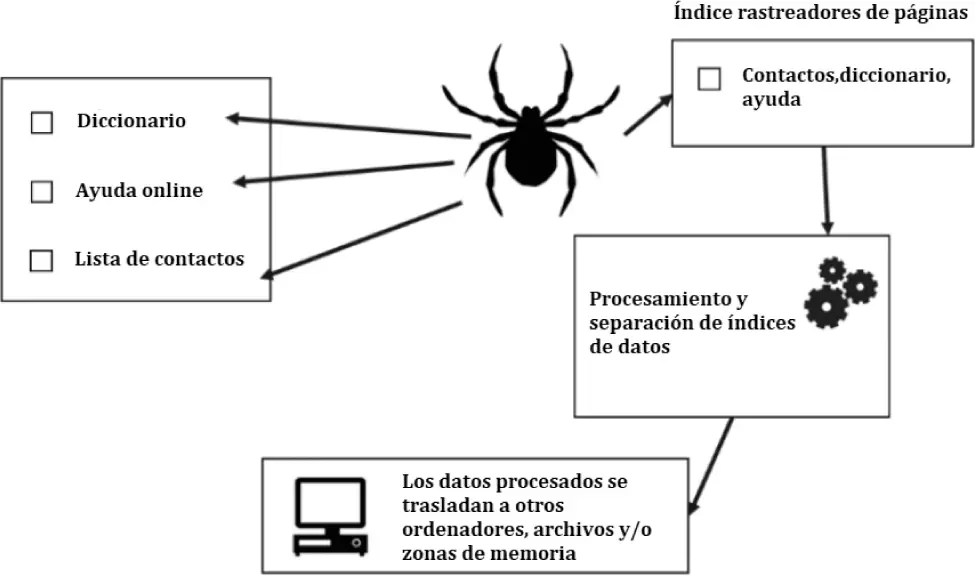
Figura 1.1Funcionalidad de una araña o web crawler.
Como se puede observar en la figura 1.1, la fuente de todos los datos del motor de búsqueda es un crawler, que visita automáticamente las páginas y los índices de sus contenidos. Una vez que una página ha sido rastreada, los datos que contiene se procesan.
Los motores de búsqueda pueden realizar distintos tipos de búsquedas, ya sea por fecha, por un campo específico o por temas; en los siguientes puntos se explican algunos tipos :
• Restringido campo de búsqueda.Permite a los usuarios realizar su búsqueda sobre un determinado campo dentro de un registro almacenado de datos, por ejemplo “Título” o “Autor”.
• Consultas booleanas.Se hace uso de operadores booleanos para aumentar la precisión de una búsqueda.
• Búsqueda de concordancia.Produce una lista alfabética de todas las palabras principales que se encuentran en un texto con su contexto inmediato.
• Búsqueda de proximidad.Incluye solo los documentos que contienen dos o más palabras separadas por un número determinado de palabras.
• Expresión regular.Emplea una sintaxis para realizar consultas más complejas.
• Búsqueda facetada.Consiste en encontrar elementos o contenidos restringiendo el conjunto global de resultados a través de múltiples criterios o facetas, lo cual permitirá realizar la búsqueda mediante cualquier metadato del grafo semántico de una determinada entidad.
1.4 PROCESO DE INDEXACIÓN
El proceso de localizar y recuperar cada contenido de un archivo se conoce como indexación. Una palabra clave, asociada a un identificador de un archivo específico, se incluirá en un índice para, posteriormente, conocer la posición exacta de cada archivo y posibilitar el análisis de frecuencias de cada palabra. La mayoría de las herramientas de acceso a la web están basadas en indexación automática, que no es más que la indexación que se realiza a través de procedimientos algorítmicos.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Desarrollo de motores de búsqueda utilizando herramientas open source»
Представляем Вашему вниманию похожие книги на «Desarrollo de motores de búsqueda utilizando herramientas open source» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Desarrollo de motores de búsqueda utilizando herramientas open source» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.