Change Detection and Image Time Series Analysis 2
Здесь есть возможность читать онлайн «Change Detection and Image Time Series Analysis 2» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Change Detection and Image Time Series Analysis 2
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Change Detection and Image Time Series Analysis 2: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Change Detection and Image Time Series Analysis 2»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Change Detection and Image Time Series Analysis 2 — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Change Detection and Image Time Series Analysis 2», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
1.2.4.4. Second top-down pass
Finally, based on equation [1.5], the posterior marginal is initialized at the root of the second quad-tree as 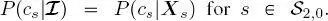 Then, given the probabilities that have been determined or modeled within the previous stages,
Then, given the probabilities that have been determined or modeled within the previous stages, 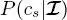 is obtained on all sites
is obtained on all sites 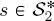 of all other layers through equation [1.5], by sweeping the second quad-tree downward in a second top-down pass.
of all other layers through equation [1.5], by sweeping the second quad-tree downward in a second top-down pass.
1.2.4.5. Generation of the output map
The aforementioned stages lead to the computation of the posterior marginal 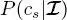 on every site s of the second quad-tree. In principle, site s could directly be given the label
on every site s of the second quad-tree. In principle, site s could directly be given the label 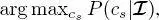 i.e. the label that maximizes
i.e. the label that maximizes 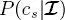 over the set Ω of classes. However, this strategy is often avoided in the literature of hierarchical MRFs because of its computational burden and of the risk of blocky artifacts (Laferté et al. 2000; Voisin et al. 2014). As an alternative, the case-specific formulation of the modified Metropolis dynamics (MMD) algorithm (Berthod et al. 1996), which was combined with MPM in Hedhli et al. (2016) for the case of multitemporal single-sensor classification, is generalized here to the multisensor case. We refer the reader to Hedhli et al. (2016) for more detail. In the case of both proposed methods, after this integrated MPM–MMD labeling, the classification result on the leaves of the second quad-tree provides the output classification map at the finest of the observed resolutions.
over the set Ω of classes. However, this strategy is often avoided in the literature of hierarchical MRFs because of its computational burden and of the risk of blocky artifacts (Laferté et al. 2000; Voisin et al. 2014). As an alternative, the case-specific formulation of the modified Metropolis dynamics (MMD) algorithm (Berthod et al. 1996), which was combined with MPM in Hedhli et al. (2016) for the case of multitemporal single-sensor classification, is generalized here to the multisensor case. We refer the reader to Hedhli et al. (2016) for more detail. In the case of both proposed methods, after this integrated MPM–MMD labeling, the classification result on the leaves of the second quad-tree provides the output classification map at the finest of the observed resolutions.
1.2.5. Probability density estimation through finite mixtures
For each class, layer and quad-tree, a finite mixture model (FMM) is used for the corresponding pixelwise class-conditional pdf. This means that the function 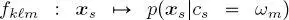 for
for 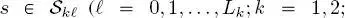
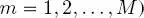 is supposed to belong to the following class of pdfs:
is supposed to belong to the following class of pdfs:
[1.11] 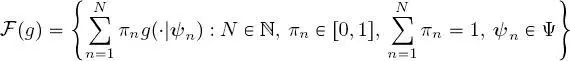
where 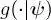 is a pdf model depending on a vector
is a pdf model depending on a vector 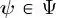 of parameters that takes values in a parameter set
of parameters that takes values in a parameter set 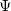 , and every function
, and every function 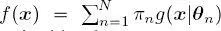 is a convex linear combination of N such pdfs, parameterized by the parameter vectors
is a convex linear combination of N such pdfs, parameterized by the parameter vectors  and weighted by the proportions
and weighted by the proportions  .
.
This modeling choice is motivated by the remarkable flexibility that FMMs offer in the characterization of data with heterogeneous statistics – a highly desirable property in the application to high spatial resolution remote sensing imagery (Hedhli et al. 2016). In the proposed methods, for each layer of each quad-tree, if the corresponding data are multispectral, then for all class-conditional pdfs, g is chosen to be a multivariate Gaussian, i.e. a Gaussian mixture model is used. In this case, the parameter vector ψn of each component obviously includes the related vector mean and covariance matrix ( n = 1, 2,..., N ) (Landgrebe 2003). This model is also extended to the layers populated by wavelet transforms of optical data, consistently with the linearity of the wavelet operators.
On the contrary, for each layer that is populated by SAR data, all class-conditional pdfs are modeled using FMMs in which g is a generalized Gamma distribution, i.e. generalized Gamma mixtures are used. In this case, the parameter vector θn of each n -th component includes a scale parameter and two shape parameters ( n = 1, 2,..., N ). The choice of the generalized Gamma mixture is explained by its accuracy in the application to high spatial resolution SAR imagery (Li et al. 2011; Krylov et al. 2013). Here, we also generalize it – albeit empirically – to the layers populated with wavelet transforms of SAR imagery.
In all of these cases, the FMM parameters are estimated through the stochastic expectation maximization (SEM) algorithm. SEM is an iterative stochastic parameter estimation technique that has been introduced for problems characterized by data incompleteness and that approaches maximum likelihood estimates under suitable assumptions (Celeux et al. 1996). It is separately applied to the training set of each class ωm in each 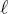 -th layer of each k -th quad-tree, to model the corresponding class-conditional pdf
-th layer of each k -th quad-tree, to model the corresponding class-conditional pdf 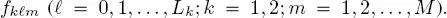 In the case of the generalized Gamma mixtures for the SAR layers, it is also integrated with the method of log-cumulants (Krylov et al. 2013). Details on this combination can be found in (Moser and Serpico 2009). We recall that SEM also automatically determines the number N of mixture components, for which only an upper bound has to be provided by the operator. This upper bound was set to 10 in all of our experiments.
In the case of the generalized Gamma mixtures for the SAR layers, it is also integrated with the method of log-cumulants (Krylov et al. 2013). Details on this combination can be found in (Moser and Serpico 2009). We recall that SEM also automatically determines the number N of mixture components, for which only an upper bound has to be provided by the operator. This upper bound was set to 10 in all of our experiments.
1.3. Examples of experimental results
1.3.1. Results of the first method
Интервал:
Закладка:
Похожие книги на «Change Detection and Image Time Series Analysis 2»
Представляем Вашему вниманию похожие книги на «Change Detection and Image Time Series Analysis 2» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Change Detection and Image Time Series Analysis 2» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.