Computational Statistics in Data Science
Здесь есть возможность читать онлайн «Computational Statistics in Data Science» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Computational Statistics in Data Science
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Computational Statistics in Data Science: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Computational Statistics in Data Science»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Computational Statistics in Data Science
Computational Statistics in Data Science
Wiley StatsRef: Statistics Reference Online
Computational Statistics in Data Science
Computational Statistics in Data Science — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Computational Statistics in Data Science», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Recently, SAS's popularity has diminished [4]; yet, it remains widely used. Open‐source competitors threaten SAS's previous overall market dominance. Rather than complete removal, we see SAS becoming a niche product in the future. Now, however, SAS expertise remains desired in certain roles and industries.
2.4 SPSS®
Norman H. Nie, C. Hadlai (Tex) Hul, and Dale Brent developed SPSS in the late 1960s. The trio were Stanford University graduate students at the time. SPSS was founded in 1968 and incorporated in 1975. SPSS became publicly traded in 1993. Now, IBM owns the rights to SPSS. Originally, developers designed SPSS for mainframe use. In 1984, SPSS introduced SPSS/PC  for computers running MS‐DOS, followed by a UNIX release in 1988 and a Macintosh version in 1990. SPSS features an intuitive point‐and‐click interface. This design empowers a broad user base to conduct standard analyses.
for computers running MS‐DOS, followed by a UNIX release in 1988 and a Macintosh version in 1990. SPSS features an intuitive point‐and‐click interface. This design empowers a broad user base to conduct standard analyses.
SPSS features a wide variety of analytic capabilities including one for regression, classification trees, table creation, exact tests, categorical analysis, trend analysis, conjoint analysis, missing value analysis, map‐based analysis, and complex samples analysis. In addition, SPSS supports numerous stand‐alone products including Amos™ (a structural equation modeling package), SPSS Text Analysis for Surveys™ (a survey analysis package utilizing natural language processing (NLP) methodology), SPSS Data Entry™ (a web‐based data entry package; see Web Based Data Management in Clinical Trials), AnswerTree® (a market segment targeting package), SmartViewer® Web Server™ (a report‐generation and dissemination package), SamplePower® ( sample size calculation package), DecisionTime® and What if?™ (a scenario analysis package for the nonspecialist), SmartViewer® for Windows (a graph/report sharing utility), SPSS WebApp Framework (web‐based analytics package), and the Dimensions Development Library (a data capture library).
SPSS remains popular, especially in scholarly work [4]. For many researchers whom apply standard models, SPSS gets the job done. We see SPSS remaining a useful tool for practitioners across many fields.
3 Noteworthy Statistical Software and Related Tools
Next, we discuss noteworthy statistical software, aiming to provide essential details for a fairly complete survey of the most commonly used statistical software and related tools.
3.1 BUGS/JAGS
The BUGS (Bayesian inference using Gibbs sampling) project led to some of the most popular general‐purpose Bayesian posterior sampling programs – WinBUGS [10] and, later, OpenBUGS, the open‐source equivalent. BUGS begin in 1989 in the MRC Biostatistics Unit, Cambridge University. The project in part led to a rapid expansion of applied Bayesian statistics due its pioneering timing, relative ease of use, and broad range of applicable models.
JAGS (Just Another Gibbs Sampler) [11] was developed as a cross‐platform engine for the BUGS modeling language. A secondary goal was to provide extensibility, allowing user‐specific functions, distributions, and sampling algorithms. The BUGS/JAGS approach to specifying probabilistic models has become standard in other related software (e.g., NIMBLE). Both BUGS and JAGS are still widely used and are well suited for tasks of small‐to‐medium complexity. However, for highly complex models and big data problems there are similar, more‐powerful Bayesian inference engines emerging, for example, STAN and Pyro (see Section 4for more details).
3.2 C++
C 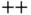 is a general‐purpose, high‐performance programming language. Unlike other scripting languages for statistics such as R and Python, C
is a general‐purpose, high‐performance programming language. Unlike other scripting languages for statistics such as R and Python, C 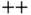 is a compiled language – adding complexity (such as memory management) and strict syntax requirements. As such, C's design may complicate prototyping. Thus, data scientists typically turn to C
is a compiled language – adding complexity (such as memory management) and strict syntax requirements. As such, C's design may complicate prototyping. Thus, data scientists typically turn to C 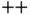 to optimize/scale a developed algorithm at the production level.
to optimize/scale a developed algorithm at the production level.
C 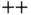 's standard libraries lack many mathematical and statistical operations. However, since C
's standard libraries lack many mathematical and statistical operations. However, since C 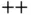 can be compiled cross‐platform, developers often interface C
can be compiled cross‐platform, developers often interface C 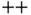 functions from different languages (e.g., R and Python). Thus, C
functions from different languages (e.g., R and Python). Thus, C 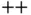 can be used to develop libraries across languages, offering impressive computing performance.
can be used to develop libraries across languages, offering impressive computing performance.
To enable analysis, developers created mathematical and statistical libraries in C 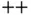 . The packages often employ of BLAS (basic linear algebra subprograms) libraries, written in C/Fortran and offer numerous low‐level, high‐performance linear algebra operations on numbers, vectors, and matrices. Some popular BLAS‐compatible libraries include Intel Math Kernel Library (MKL) [12], automatically tuned linear algebra software (ATLAS) [13], OpenBLAS [14], and linear algebra package (LAPACK) [15].
. The packages often employ of BLAS (basic linear algebra subprograms) libraries, written in C/Fortran and offer numerous low‐level, high‐performance linear algebra operations on numbers, vectors, and matrices. Some popular BLAS‐compatible libraries include Intel Math Kernel Library (MKL) [12], automatically tuned linear algebra software (ATLAS) [13], OpenBLAS [14], and linear algebra package (LAPACK) [15].
Among the C  libraries for mathematics and statistics built on top BLAS, we detail three popular, well‐maintained libraries: Eigen [16], Armandillo [17], and Blaze [18] below:
libraries for mathematics and statistics built on top BLAS, we detail three popular, well‐maintained libraries: Eigen [16], Armandillo [17], and Blaze [18] below:
Eigen is a high‐level, header‐only library developed by Guennebaud et al . [16]. Eigen provides classes dealing with vector types, arrays, and dense/sparse/large matrices. It also supports matrix decomposition and geometric features. Eigen uses single instruction multiple data vectorization to avoid dynamic memory allocation. Eigen also implements extra features to optimize the computing performance, including unrolling techniques and processor‐cache utilization. Eigen itself does not take much advantage from parallel hardware, currently supporting parallel processing only for general matrix–matrix products. However, since Eigen uses BLAS‐compatible libraries, users can utilize external BLAS libraries in conjunction with Eigen for parallel computing. Python and R users can call Eigen functions using the minieigen and RcppEigen packages.
The National ICT Australia (NICTA) developed the open‐source library Armadillo to facilitate science and engineering [17]. Armadillo provides a fast, easy‐to‐use matrix library with MATLAB‐like syntax. Armadillo employs template meta‐programming techniques to avoid unnecessary operations and increase library performance. Further, Armadillo supports 3D objects and provides numerous utilities for matrices manipulation and decomposition. Armadillo automatically utilizes open multiprocessing (OpenMP) [19] to increase speed. Developers designed Armadillo to provide a balance between speed and ease of use. Armadillo is widely used for many applications in ML, pattern recognition, signal processing, and bioinformatics. R users may call Armadillo functions through the RcppArmadillo package.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Computational Statistics in Data Science»
Представляем Вашему вниманию похожие книги на «Computational Statistics in Data Science» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)











Обсуждение, отзывы о книге «Computational Statistics in Data Science» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.